看山聊并发:如果非要在多线程中使用ArrayList会发生什么?

你好,我是看山。
我们都知道,Java中的ArrayList是非线程安全的,这个知识点太熟了,甚至面试的时候都很少问了。
但是我们真的清楚原理吗?或者知道多线程情况下使用ArrayList会发生什么?
前段时间,我们就踩坑了,而且直接踩了两个坑,今天就来扒一扒。
你好,我是看山。
我们都知道,Java中的ArrayList是非线程安全的,这个知识点太熟了,甚至面试的时候都很少问了。
但是我们真的清楚原理吗?或者知道多线程情况下使用ArrayList会发生什么?
前段时间,我们就踩坑了,而且直接踩了两个坑,今天就来扒一扒。

7月并发网组织翻译GO官网教程https://golang.google.cn/doc/相关技术文章,欢迎大家踊跃参加。
通过评论领取想要翻译的文章,每次领取一章或一节(根据内容长短),翻译完后再领取其他章节。领取完成之后,译文最好在一个星期内翻译完成,如果不能完成翻译,也欢迎你邀请其他同学和你一起完成翻译。请谨慎领取,很多文章领取了没有翻译,导致文章很长时间没人翻译。
阅读全文Feign 是⼀个 HTTP 请求的轻量级客户端框架。通过 接口 + 注解的方式发起 HTTP 请求调用,面向接口编程,而不是像 Java 中通过封装 HTTP 请求报文的方式直接调用。服务消费方拿到服务提供方的接⼝,然后像调⽤本地接⼝⽅法⼀样去调⽤,实际发出的是远程的请求。让我们更加便捷和优雅的去调⽤基于 HTTP 的 API,被⼴泛应⽤在 Spring Cloud 的解决⽅案中。开源项目地址:Feign,官方描述如下:
阅读全文Feign is a Java to HTTP client binder inspired by Retrofit, JAXRS-2.0, and WebSocket. Feign’s first goal was reducing the complexity of binding Denominator uniformly to HTTP APIs regardless of ReSTfulness.
MySQL 支持由 RFC 7159 定义的原生JSON 数据类型,该数据类型可以有效访问 JSON(JavaScript Object Notation)中的元素数据。与将JSON 格式的字符串存储为单个字符串类型相比,JSON 数据类型具有以下优势:
MYSQL 8.0,除了提供JSON 数据类型,还有一组 SQL 函数可用于操作 JSON 的值,例如创建JSON对象、增删改查JSON数据中的某个元素。
阅读全文在上篇「如何实现 AOP(上)」介绍了 AOP 技术出现的原因和一些重要的概念,在我们自己实现之前有必要先了解一下 AOP 底层到底是如何运作的,所以这篇再来看看 AOP 实现所依赖的一些核心基础技术。AOP 是使用动态代理和字节码生成技术来实现的,在运行期(注意:不是编译期!)为目标对象生成代理对象,然后将横切逻辑织入到生成的代理对象中,最后系统使用的是带有横切逻辑的代理对象,而不是被代理对象,由代理对象转发到被代理对象。
本文是「如何实现一个简易版的 Spring 系列」的第五篇,在之前介绍了 Spring 中的核心技术之一 IoC,从这篇开始我们再来看看 Spring 的另一个重要的技术——AOP。用过 Spring 框架进行开发的朋友们相信或多或少应该接触过 AOP,用中文描述就是面向切面编程。学习一个新技术了解其产生的背景是至关重要的,在刚开始接触 AOP 时不知道你有没有想过这个问题,既然在面向对象的语言中已经有了 OOP 了,为什么还需要 AOP 呢?换个问法也就是说在 OOP 中有哪些场景其实处理得并不优雅,需要重新寻找一种新的技术去解决处理?(P.S. 这里建议暂停十秒钟,自己先想一想…)
The JSR-133 Cookbook
“The JSR-133 Cookbook for Compiler Writers”
original website is http://g.oswego.edu/dl/jmm/cookbook.html. by Doug Lea, with help from members of the JMM mailing list.
Chinese edition is translated by 崔新, And website is https://yellowstar5.cn/direct/The%20JSR-133%20Cookbook-chinese.html
阅读全文本文作者 https://github.com/lich0079 转载请注明
多核执行多线程的情况下,每个core读取变量不是直接从内存读,而是从L1, L2 …cache读,所以你在一个core中的write不一定会被其他core马上观测到。
解决这个的办法就是volatile关键字,加上它修饰后,变量在一个core中做了修改,会导致其他core的缓存立即失效,这样就会从内存中读出最新的值,保证了可见性。
阅读全文grpc 是一个由 google 推出的、高性能、开源、通用的 rpc 框架。它是基于 HTTP2 协议标准设计开发,默认采用 Protocol Buffers 数据序列化协议,支持多种开发语言。
一般业务场景下,我们都是使用grpc的simple-rpc模式,也就是每次客户端发起请求,服务端会返回一个响应结果的模式。
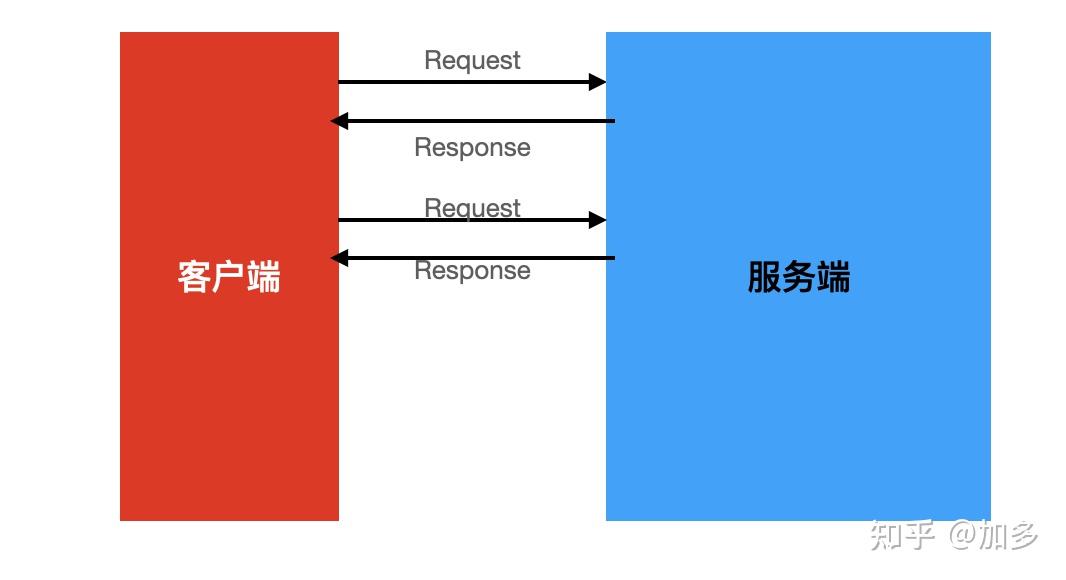
image.png
但是grpc除了这种一来一往的请求模式外,还有流式模式,下面我们一一道来。
阅读全文CS架构也称为两层架构,客户端与服务端进行通信,服务端替客户端做一些计算。
一些常见的CS架构:
作者:Jakob Jenkov 更新时间:2014-06-01
Scala是一个非常有趣的新编程语言,相比Java有很多新特性。Scala非常吸引Java程序员,因为Scala被编译为Java字节码,在虚拟机中运行。这意味着你可以在Scala代码中使用Java类,甚至是我们自己开发的Java类。Java程序员可以方便使用Scala,因为可以重用大量Java代码。
阅读全文作者:Jakob Jenkov 更新时间:2014-05-25
本文旨在为您提供Scala编程语言和Scala平台的概述。 由于Scala一直在开发,因此该概述页面可能会随着时间的推移而变化。 另外,随着作者对Scala语言了解的深入,本文也会有所添加。
Scala被编译成Java字节码,由Java虚拟机(JVM)执行。 Scala和Java具有通用的运行时平台。 如果您或您的组织已经使用Java标准化,那么您也不会对scala感到完全陌生。 Scala与Java不同的语言,相同的运行环境。
阅读全文你好,我是看山。
本文源自并发编程网的翻译邀请,翻译的是 Jakob Jenkov 的 《软件架构》 中关于事件驱动的内容,虽然是 2014 年的文章,但是从软件架构层面上,并不过时。
以下是正文。
事件驱动架构是一种系统或组件之间通过发送事件和响应事件彼此交互的架构风格。当某个事件发生时,组件A不直接调用组件B,而只是发出一个事件。组件A不知道哪些组件监听并处理这些事件。事件驱动架构可以在进程内和进程间使用。比如,GUI框架中会大量使用事件驱动。【译者注:目前很多系统采用微服务架构,事件驱动使用的更加广泛了。】此外,正如我在并发模型教程 中所提到的,装配线并发模型(AKA reactive,非阻塞并发模型)也使用了事件驱动架构。
本文主要介绍进程之间的事件驱动架构,后文提到这个词的时候也是指进程交互方式。




 (7 votes, average: 3.29 out of 5)
(7 votes, average: 3.29 out of 5)
