volatile 关键字需要知道的几点
本文作者 https://github.com/lich0079 转载请注明
可见性
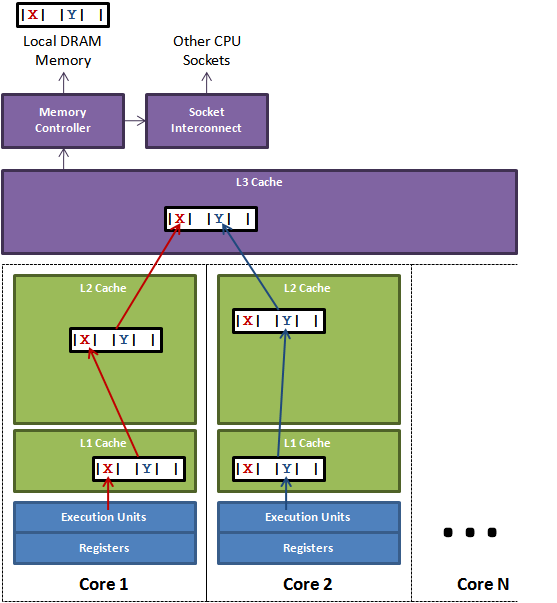
多核执行多线程的情况下,每个core读取变量不是直接从内存读,而是从L1, L2 …cache读,所以你在一个core中的write不一定会被其他core马上观测到。
解决这个的办法就是volatile关键字,加上它修饰后,变量在一个core中做了修改,会导致其他core的缓存立即失效,这样就会从内存中读出最新的值,保证了可见性。
阅读全文本文作者 https://github.com/lich0079 转载请注明
多核执行多线程的情况下,每个core读取变量不是直接从内存读,而是从L1, L2 …cache读,所以你在一个core中的write不一定会被其他core马上观测到。
解决这个的办法就是volatile关键字,加上它修饰后,变量在一个core中做了修改,会导致其他core的缓存立即失效,这样就会从内存中读出最新的值,保证了可见性。
阅读全文从Java视角理解系统结构连载, 关注我的微博(链接)了解最新动态
从我的前一篇博文中, 我们知道了CPU缓存及缓存行的概念, 同时用一个例子说明了编写单线程Java代码时应该注意的问题. 下面我们讨论更为复杂, 而且更符合现实情况的多核编程时将会碰到的问题. 这些问题更容易犯, 连j.u.c包作者Doug Lea大师的JDK代码里也存在这些问题.
MESI协议及RFO请求
从前一篇我们知道, 典型的CPU微架构有3级缓存, 每个核都有自己私有的L1, L2缓存. 那么多线程编程时, 另外一个核的线程想要访问当前核内L1, L2 缓存行的数据, 该怎么办呢?
有人说可以通过第2个核直接访问第1个核的缓存行. 这是可行的, 但这种方法不够快. 跨核访问需要通过Memory Controller(见上一篇的示意图), 典型的情况是第2个核经常访问第1个核的这条数据, 那么每次都有跨核的消耗. 更糟的情况是, 有可能第2个核与第1个核不在一个插槽内.况且Memory Controller的总线带宽是有限的, 扛不住这么多数据传输. 所以, CPU设计者们更偏向于另一种办法: 如果第2个核需要这份数据, 由第1个核直接把数据内容发过去, 数据只需要传一次。
原文链接 作者:Dave 译者:卓二妹 校对:丁一
详细描述看Aleksey Shipilev这封邮件 —— 我们期待@Contended已久。JVM会自动为对象字段进行内存布局。通常JVM会这样做:(a)将对象的域按从大到小的顺序排列,以优化占用的空间;(b)打包引用类型的字段,以便垃圾收集器在追踪的时候能够处理相连的引用类型的字段。@Contended让程序能够更明确地控制并发和伪共享。通过该功能我们能够把那些频繁进行写操作的共享字段,从其它几乎是只读或只有少许写操作的字段中分离开来。原则很简单:对共享内容进行读操作的代价小,对共享内容的写操作代价非常高。我们也可以将那些可能会被同一个线程几乎同时写的字段打包到一起。
原文:False Shareing && Java 7 (依然是马丁的博客) 译者:杨帆 校对:方腾飞
在我前一篇有关伪共享的博文中,我提到了可以加入闲置的long字段来填充缓存行来避免伪共享。但是看起来Java 7变得更加智慧了,它淘汰或者是重新排列了无用的字段,这样我们之前的办法在Java 7下就不奏效了,但是伪共享依然会发生。我在不同的平台上实验了一些列不同的方案,并且最终发现下面的代码是最可靠的。(译者注:下面的是最终版本,马丁在大家的帮助下修改了几次代码) 阅读全文
原文:http://mechanical-sympathy.blogspot.hk/2011/08/false-sharing-java-7.html (因为被墙移动到墙内)
In my previous post on False Sharing I suggested it can be avoided by padding the cache line with unused longfields. It seems Java 7 got clever and eliminated or re-ordered the unused fields, thus re-introducing false sharing. I’ve experimented with a number of techniques on different platforms and found the following code to be the most reliable.
 Martin Fowler在自己网站上写了一篇LMAX架构的文章,在文章中他介绍了LMAX是一种新型零售金融交易平台,它能够以很低的延迟产生大量交易。这个系统是建立在JVM平台上,其核心是一个业务逻辑处理器,它能够在一个线程里每秒处理6百万订单。业务逻辑处理器完全是运行在内存中,使用事件源驱动方式。业务逻辑处理器的核心是Disruptor。
Martin Fowler在自己网站上写了一篇LMAX架构的文章,在文章中他介绍了LMAX是一种新型零售金融交易平台,它能够以很低的延迟产生大量交易。这个系统是建立在JVM平台上,其核心是一个业务逻辑处理器,它能够在一个线程里每秒处理6百万订单。业务逻辑处理器完全是运行在内存中,使用事件源驱动方式。业务逻辑处理器的核心是Disruptor。
Disruptor它是一个开源的并发框架,并获得2011 Duke’s 程序框架创新奖,能够在无锁的情况下实现网络的Queue并发操作。本文是Disruptor官网中发布的文章的译文(现在被移到了GitHub)。
原文地址:http://ifeve.com/false-sharing/
作者:Martin Thompson 译者:丁一
缓存系统中是以缓存行(cache line)为单位存储的。缓存行是2的整数幂个连续字节,一般为32-256个字节。最常见的缓存行大小是64个字节。当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。缓存行上的写竞争是运行在SMP系统中并行线程实现可伸缩性最重要的限制因素。有人将伪共享描述成无声的性能杀手,因为从代码中很难看清楚是否会出现伪共享。
为了让可伸缩性与线程数呈线性关系,就必须确保不会有两个线程往同一个变量或缓存行中写。两个线程写同一个变量可以在代码中发现。为了确定互相独立的变量是否共享了同一个缓存行,就需要了解内存布局,或找个工具告诉我们。Intel VTune就是这样一个分析工具。本文中我将解释Java对象的内存布局以及我们该如何填充缓存行以避免伪共享。
阅读全文
原文地址:http://mechanical-sympathy.blogspot.com/2011/07/false-sharing.html(有墙移到墙内)
Memory is stored within the cache system in units know as cache lines. Cache lines are a power of 2 of contiguous bytes which are typically 32-256 in size. The most common cache line size is 64 bytes. False sharing is a term which applies when threads unwittingly impact the performance of each other while modifying independent variables sharing the same cache line. Write contention on cache lines is the single most limiting factor on achieving scalability for parallel threads of execution in an SMP system. I’ve heard false sharing described as the silent performance killer because it is far from obvious when looking at code.
To achieve linear scalability with number of threads, we must ensure no two threads write to the same variable or cache line. Two threads writing to the same variable can be tracked down at a code level. To be able to know if independent variables share the same cache line we need to know the memory layout, or we can get a tool to tell us. Intel VTune is such a profiling tool. In this article I’ll explain how memory is laid out for Java objects and how we can pad out our cache lines to avoid false sharing.
 |
| Figure 1. |




