《软件架构模式》-第四章 微服务框架模式(下)
原文链接 译者:克里斯托刘
《软件架构模式》-第四章 微服务框架模式(下)
避免依赖和编排
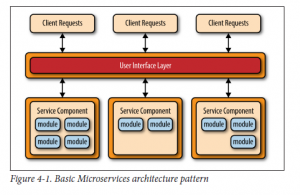
设计微服务架构的一个主要难度是为服务组件选择正确的粗细粒度。如果服务组件设计的太粗糙,就彰显不了这种架构模式带来的好处(如部署、可扩展性、可测试性和松耦合)。但是,服务组件设计的过于细化,对服务组件编排要求更高,将你的微服务系统演变成面向服务的重量级体系结构,通常会带来缺点如复杂性、误导性、高开销,这些都是能在基于SOA的应用程序中找到的。
原文链接 译者:克里斯托刘
《软件架构模式》-第四章 微服务框架模式(下)
避免依赖和编排
设计微服务架构的一个主要难度是为服务组件选择正确的粗细粒度。如果服务组件设计的太粗糙,就彰显不了这种架构模式带来的好处(如部署、可扩展性、可测试性和松耦合)。但是,服务组件设计的过于细化,对服务组件编排要求更高,将你的微服务系统演变成面向服务的重量级体系结构,通常会带来缺点如复杂性、误导性、高开销,这些都是能在基于SOA的应用程序中找到的。
原文地址 译者:克里斯托刘
微服务架构模式正在迅速成为行业中单一应用程序及面向服务架构的可行的解决方案。因为这个架构模式仍在不断发展,关于这种模式的定义和其实现方式还有很多困惑之处。本章将为您解释其关键概念和基础知识,以理解这种模式的优点以及是否适合您的应用程序。
模式描述
无论选择的拓扑或实施方式如何,有许多普遍的核心概念是适用于所有的该架构模式。第一个概念是独立部署单元。如图4-1所示,每个微服务架构的组件都部署为一个独立的单元,这达到了以下优点:部署简单(通过高效和流水交付管道)、可扩展性增加、以及高度的应用和组件在应用程序内的解耦。

原文链接:A Java Fork/Join Framework(PDF) – Doug Lea
Doug Lea 大神关于Java 7引入的他写的Fork/Join框架的论文。
响应式编程(Reactive Programming / RP)作为一种范式在整个业界正在逐步受到认可和落地,是对过往系统的业务需求理解梳理之后对系统技术设计/架构模式的提升总结。Java作为一个成熟平台,对于趋势一向有些稳健的接纳和跟进能力,有着令人惊叹的生命活力:
Java 7提供了ForkJoinPool,支持了Java 8提供的Stream。Java 8还提供了Lamda(有效地表达和使用RP需要FP的语言构件和理念)。Java 9中提供了面向RP的官方Flow API,实际上是直接把Reactive Streams的接口加在Java标准库中,即Reactive Streams规范转正了,Reactive Streams是RP的基础核心组件。Flow API标志着RP由集市式的自由探索阶段 向 教堂式的统一使用的转变。通过上面这些说明,可以看到ForkJoinPool的基础重要性。
对了,另外提一下Java 9的Flow API的@author也是 Doug Lee 哦~
PS:基于Alex/萧欢 翻译、方腾飞 校对的译文稿:Java Fork Join 框架,补译『结论』之后3节,调整了格式和一些用词,整理成完整的译文。译文源码在GitHub的这个仓库中,可以提交Issue/Fork后提交代码来建议/指正。
这篇论文描述了Fork/Join框架的设计、实现以及性能,这个框架通过(递归的)把问题划分为子任务,然后并行的执行这些子任务,等所有的子任务都结束的时候,再合并最终结果的这种方式来支持并行计算编程。总体的设计参考了为Cilk设计的work-stealing框架。就设计层面来说主要是围绕如何高效的去构建和管理任务队列以及工作线程来展开的。性能测试的数据显示良好的并行计算程序将会提升大部分应用,同时也暗示了一些潜在的可以提升的空间。
原文地址 译者:克里斯托刘
事件驱动架构模式是一个非常流行的异步分布模式,可生成高可扩展性应用。而且它也具有强适应能力,可被用于小程序或者大型复杂程序。事件驱动架构是由高耦合度、单一目的的事件处理模块构成,这些模块异步接收、处理事件。
事件驱动架构模式有两种主要拓扑结构,“调度员”(mediator)和“经纪人”(broker)拓扑结构。“调度员”拓扑结构通常用在一个事件中由多个步骤组成,而你需要通过中央“调度员”模块去调度这些步骤。然而“经纪人”结构是当需要执行一系列事件链,而不需要中央“调度员”模块。由于这两种结构的特征和执行策略不同,深入理解两者的用法能帮助你在自己的案例中做出正确的判断。
原文地址 译者:克里斯托刘
模式实例
为更好描述分层架构怎样工作,考虑一个业务从业人员获取特定目标用户信息的需求,如图1-4所示。黑色箭头标志一路下到数据库的获取用户数据的请求流向,而红色箭头显示从下往上直到显示数据的屏幕这一数据反馈流向。在这个例子中,客户信息包含客户数据及订单数据(用户下的订单)。“用户屏幕”负责接收查询请求和显示用户信息,它并不知道数据在哪里、如何获取它、有多少数据库表格需要查询才能满足查询请求。一旦“用户屏幕”接收到查询客户信息的请求,它接着传递请求到“用户代理”模块。这个模块知道业务层中哪个模块可以处理该请求,同时知道如何调用该模块、传递哪些参数给该模块。业务层中的“用户类”负责收集所有业务请求需要的信息。该模块调用持续层的“用户数据访问接口”(Dao data access object)模块获取用户数据;调用“订单数据访问接口”模块获取订单信息。这些模块接着执行SQL语句去获得相关数据,再传递回业务层的“用户类”模块。一旦“用户类”获得数据,它会收集订单和用户信息两块数据同时传递回“用户代理”模块,“用户代理”模块继而传递数据回“用户屏幕”呈现给使用者。
我们认为,一个流处理平台应该具有三个关键能力:
原文地址 译者:克里斯托刘
第一章
分层架构
最通常的架构模式就是分层架构模式,即所谓的N层架构。这种模式对大部分JAVAEE应用程序来说是标准模式,因此被大部分架构师、软件设计师、开发者广泛知晓。由于分层架构模式和公司里传统的IT沟通以及组织结构非常类似,使得它成为大多数商务应用开发最自然的选择。
1. Disruptor是什么
LMAX是在英国注册并受到FCA监管(监管号码为509778)的外汇黄金交易所, LMAX架构是LMAX内部研发并应用到交易系统的一种技术。它之所以引起人们的关注,是因为它是一个非常高性能系统,这个系统是建立在JVM平台上,核心是一个业务逻辑处理器,官方号称它能够在一个线程里每秒处理6百万订单.
一个仅仅部署在4台服务器上的服务,每秒向Database写入数据超过100万行数据,每分钟产生超过1G的数据。而每台服务器(8核12G)上CPU占用不到100%,load不超过5。
原文链接 作者:Tomasz Nurkiewicz 译者:simonwang
(译者:强力推荐这篇文章,作者设计了一个用于小流量的流式数据处理框架,并详细给出了每一个需要注意的设计细节,对比了不同设计方案的优缺点,能够让你对流处理过程,某些设计模式和设计原则以及指标度量工具有一个更深刻的认识!)
在GeeCON 2016上我为我的公司准备了一个编程竞赛,这次的任务是设计并实现一个能够满足以下要求的系统:
阅读全文
摘要: 原创出处:www.bysocket.com 泥瓦匠BYSocket 希望转载,保留摘要,谢谢!
简单就好,生活可以很德国
Q:什么是 Spring MVC ? ※
Spring MVC 是 Spring Web 的一个重要模块。Spring 支持 Web 应用,Spring MVC 是对 MVC 模式的支持。
1. 简介.
前些天spring4.2出来了, 从GA开始就一直在跟了, 前2天看完了所有官方Release Notes, 觉得记录下我比较感兴趣的特性.
我看的是4.2GA, 4.2RC3, 4.2RC2, 4.2RC1。4.0和4.1的新特性, 可以看看涛哥的博客。这里主要是讲照官方文档里面列的, changelog里面太多了 -.-!