原文地址:http://mechanitis.blogspot.com/2011/06/dissecting-disruptor-whats-so-special.html(因被墙移到墙内) 作者:Trisha
Recently we open sourced the LMAX Disruptor, the key to what makes our exchange so fast. Why did we open source it? Well, we’ve realised that conventional wisdom around high performance programming is… a bit wrong. We’ve come up with a better, faster way to share data between threads, and it would be selfish not to share it with the world. Plus it makes us look dead clever.
On the site you can download a technical article explaining what the Disruptor is and why it’s so clever and fast. I even get a writing credit on it, which is gratifying when all I really did is insert commas and re-phrase sentences I didn’t understand.
However I find the whole thing a bit much to digest all at once, so I’m going to explain it in smaller pieces, as suits my NADD audience.
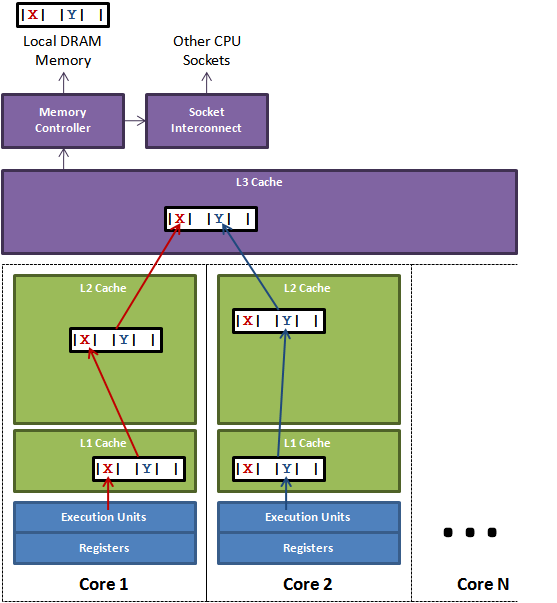
First up – the ring buffer. Initially I was under the impression the Disruptor was just the ring buffer. But I’ve come to realise that while this data structure is at the heart of the pattern, the clever bit about the Disruptor is controlling access to it.
阅读全文


 (11 votes, average: 3.91 out of 5)
(11 votes, average: 3.91 out of 5)