Java NIO系列教程(三) Buffer
原文链接 作者:Jakob Jenkov 译者:airu 校对:丁一
Java NIO中的Buffer用于和NIO通道进行交互。如你所知,数据是从通道读入缓冲区,从缓冲区写入到通道中的。
缓冲区本质上是一块可以写入数据,然后可以从中读取数据的内存。这块内存被包装成NIO Buffer对象,并提供了一组方法,用来方便的访问该块内存。
下面是NIO Buffer相关的话题列表:
- Buffer的基本用法
- Buffer的capacity,position和limit
- Buffer的类型
- Buffer的分配
- 向Buffer中写数据
- flip()方法
- 从Buffer中读取数据
- clear()与compact()方法
- mark()与reset()方法
- equals()与compareTo()方法
Buffer的基本用法
使用Buffer读写数据一般遵循以下四个步骤:
- 写入数据到Buffer
- 调用
flip()方法 - 从Buffer中读取数据
- 调用
clear()方法或者compact()方法
当向buffer写入数据时,buffer会记录下写了多少数据。一旦要读取数据,需要通过flip()方法将Buffer从写模式切换到读模式。在读模式下,可以读取之前写入到buffer的所有数据。
一旦读完了所有的数据,就需要清空缓冲区,让它可以再次被写入。有两种方式能清空缓冲区:调用clear()或compact()方法。clear()方法会清空整个缓冲区。compact()方法只会清除已经读过的数据。任何未读的数据都被移到缓冲区的起始处,新写入的数据将放到缓冲区未读数据的后面。
下面是一个使用Buffer的例子:
[code lang=”java”]
RandomAccessFile aFile = new RandomAccessFile("data/nio-data.txt", "rw");
FileChannel inChannel = aFile.getChannel();
//create buffer with capacity of 48 bytes
ByteBuffer buf = ByteBuffer.allocate(48);
int bytesRead = inChannel.read(buf); //read into buffer.
while (bytesRead != -1) {
buf.flip(); //make buffer ready for read
while(buf.hasRemaining()){
System.out.print((char) buf.get()); // read 1 byte at a time
}
buf.clear(); //make buffer ready for writing
bytesRead = inChannel.read(buf);
}
aFile.close();
[/code]
Buffer的capacity,position和limit
缓冲区本质上是一块可以写入数据,然后可以从中读取数据的内存。这块内存被包装成NIO Buffer对象,并提供了一组方法,用来方便的访问该块内存。
为了理解Buffer的工作原理,需要熟悉它的三个属性:
- capacity
- position
- limit
position和limit的含义取决于Buffer处在读模式还是写模式。不管Buffer处在什么模式,capacity的含义总是一样的。
这里有一个关于capacity,position和limit在读写模式中的说明,详细的解释在插图后面。
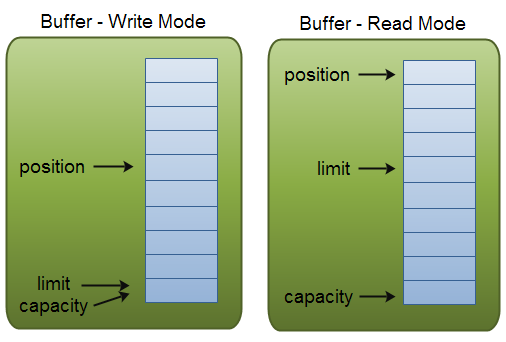
capacity
作为一个内存块,Buffer有一个固定的大小值,也叫“capacity”.你只能往里写capacity个byte、long,char等类型。一旦Buffer满了,需要将其清空(通过读数据或者清除数据)才能继续写数据往里写数据。
position
当你写数据到Buffer中时,position表示当前的位置。初始的position值为0.当一个byte、long等数据写到Buffer后, position会向前移动到下一个可插入数据的Buffer单元。position最大可为capacity – 1.
当读取数据时,也是从某个特定位置读。当将Buffer从写模式切换到读模式,position会被重置为0. 当从Buffer的position处读取数据时,position向前移动到下一个可读的位置。
limit
在写模式下,Buffer的limit表示你最多能往Buffer里写多少数据。 写模式下,limit等于Buffer的capacity。
当切换Buffer到读模式时, limit表示你最多能读到多少数据。因此,当切换Buffer到读模式时,limit会被设置成写模式下的position值。换句话说,你能读到之前写入的所有数据(limit被设置成已写数据的数量,这个值在写模式下就是position)
Buffer的类型
Java NIO 有以下Buffer类型
- ByteBuffer
- MappedByteBuffer
- CharBuffer
- DoubleBuffer
- FloatBuffer
- IntBuffer
- LongBuffer
- ShortBuffer
p<>
如你所见,这些Buffer类型代表了不同的数据类型。换句话说,就是可以通过char,short,int,long,float 或 double类型来操作缓冲区中的字节。
MappedByteBuffer 有些特别,在涉及它的专门章节中再讲。
Buffer的分配
要想获得一个Buffer对象首先要进行分配。 每一个Buffer类都有一个allocate方法。下面是一个分配48字节capacity的ByteBuffer的例子。
[code lang=”java”]
ByteBuffer buf = ByteBuffer.allocate(48);
[/code]
这是分配一个可存储1024个字符的CharBuffer:
[code lang=”java”]
CharBuffer buf = CharBuffer.allocate(1024);
[/code]
向Buffer中写数据
写数据到Buffer有两种方式:
- 从Channel写到Buffer。
- 通过Buffer的put()方法写到Buffer里。
从Channel写到Buffer的例子
[code lang=”java”]
int bytesRead = inChannel.read(buf); //read into buffer.
[/code]
通过put方法写Buffer的例子:
[code lang=”java”]
buf.put(127);
[/code]
put方法有很多版本,允许你以不同的方式把数据写入到Buffer中。例如, 写到一个指定的位置,或者把一个字节数组写入到Buffer。 更多Buffer实现的细节参考JavaDoc。
flip()方法
flip方法将Buffer从写模式切换到读模式。调用flip()方法会将position设回0,并将limit设置成之前position的值。
换句话说,position现在用于标记读的位置,limit表示之前写进了多少个byte、char等 —— 现在能读取多少个byte、char等。
从Buffer中读取数据
从Buffer中读取数据有两种方式:
- 从Buffer读取数据到Channel。
- 使用get()方法从Buffer中读取数据。
从Buffer读取数据到Channel的例子:
[code lang=”java”]
//read from buffer into channel.
int bytesWritten = inChannel.write(buf);
[/code]
使用get()方法从Buffer中读取数据的例子
[code lang=”java”]
byte aByte = buf.get();
[/code]
get方法有很多版本,允许你以不同的方式从Buffer中读取数据。例如,从指定position读取,或者从Buffer中读取数据到字节数组。更多Buffer实现的细节参考JavaDoc。
rewind()方法
Buffer.rewind()将position设回0,所以你可以重读Buffer中的所有数据。limit保持不变,仍然表示能从Buffer中读取多少个元素(byte、char等)。
clear()与compact()方法
一旦读完Buffer中的数据,需要让Buffer准备好再次被写入。可以通过clear()或compact()方法来完成。
如果调用的是clear()方法,position将被设回0,limit被设置成 capacity的值。换句话说,Buffer 被清空了。Buffer中的数据并未清除,只是这些标记告诉我们可以从哪里开始往Buffer里写数据。
如果Buffer中有一些未读的数据,调用clear()方法,数据将“被遗忘”,意味着不再有任何标记会告诉你哪些数据被读过,哪些还没有。
如果Buffer中仍有未读的数据,且后续还需要这些数据,但是此时想要先先写些数据,那么使用compact()方法。
compact()方法将所有未读的数据拷贝到Buffer起始处。然后将position设到最后一个未读元素正后面。limit属性依然像clear()方法一样,设置成capacity。现在Buffer准备好写数据了,但是不会覆盖未读的数据。
mark()与reset()方法
通过调用Buffer.mark()方法,可以标记Buffer中的一个特定position。之后可以通过调用Buffer.reset()方法恢复到这个position。例如:
[code lang=”java”]
buffer.mark();
//call buffer.get() a couple of times, e.g. during parsing.
buffer.reset(); //set position back to mark.
[/code]
equals()与compareTo()方法
可以使用equals()和compareTo()方法两个Buffer。
equals()
当满足下列条件时,表示两个Buffer相等:
- 有相同的类型(byte、char、int等)。
- Buffer中剩余的byte、char等的个数相等。
- Buffer中所有剩余的byte、char等都相同。
如你所见,equals只是比较Buffer的一部分,不是每一个在它里面的元素都比较。实际上,它只比较Buffer中的剩余元素。
compareTo()方法
compareTo()方法比较两个Buffer的剩余元素(byte、char等), 如果满足下列条件,则认为一个Buffer“小于”另一个Buffer:
- 第一个不相等的元素小于另一个Buffer中对应的元素 。
- 所有元素都相等,但第一个Buffer比另一个先耗尽(第一个Buffer的元素个数比另一个少)。
(译注:剩余元素是从 position到limit之间的元素)
原创文章,转载请注明: 转载自并发编程网 – ifeve.com本文链接地址: Java NIO系列教程(三) Buffer

 (81 votes, average: 4.48 out of 5)
(81 votes, average: 4.48 out of 5)

Hi, compact() 方法被调用之后, limit 不应该等于capacity ! 我觉得应该是: limit = capacity – (position + 1)。因为未读的数据还在占用buffer 容量!
不好意思,我查看源码(java.nio.DirectByteBuffer),确实是吧 limit 变成了 capacity!
limit 应该是总共可以写多少
capacity 应该是总容量
capacity – (position + 1) 应该是还可以写多少
所以此时
limit=capacity应该没问题
limit – (position + 1)这样算应该更准确,毕竟容量与实际允许写的极限不一定相同
翻译厉害,希望更多
cj437055739@163.com
我觉得是设计的一个错误,比如你假如Buffer里面已经cap是40,comppact后剩下35个空,但是你的limit仍然是40,假如我要往里面填数据,填到36个的时候就会出错,好在 Buffer.class类里面有一个nextPutIndex的方法,limit>postion时抛了异常,所以我觉得是设计不合理。
我觉得这个设计没有问题,你把position给忽略了,当compact后,position不一定为0。
你好,你一定是把limit和position搞混了。compact只是做压缩,如果还要写,那么还需要空间,而且这个最大数值就是limit,所以limit设置成capacity,如果你要读了,那么就需要调用flip。
这个很好测试。
您好!equals()和compareTo()的那部分内容里,把“剩余元素”写成“从 position到limit之间的元素”更为准确一些。直接写成“剩余元素”而不加解释的话,容易产生误解,比如可以理解为buffer里未使用的部分,即limt到capacity之间的元素。
多谢你的建议,我修改下。
“可以使用equals()和compareTo()方法两个Buffer”
——缺了“比较”二字。
翻译的简洁易懂,作者的功力很深,望有更多的译文分享,不胜感激。。
while(buf.hasRemaining()){
System.out.print((char) buf.get()); // read 1 byte at a time
}
这个地方应该是读取了一个char,两个字节吧。
Sorry,非常抱歉,请删掉吧。每次一个字节!
我觉得应该有一个状态变量,表示当前buffer应该是‘读’状态还是‘写’状态,否则很容易出错。比如:
CharBuffer bf = CharBuffer.allocate(10);
bf.put(‘a’);
bf.put(‘b’);
System.out.println(bf.get());
这里不会打印任何字母,而仅仅是让position加1,而且不报错。不知道代码作者是怎么考虑的。
你的调用flip()方法让buffer处于read的状态才行。在bf.put(‘b’);后面加上bf.flip();吧~
写的真好
你只能往里写capacity个byte、long,char等类型
这句话有点问题。
感谢分享!
read是读,write是写,搞错了吧
翻译的很好,就是评论千奇百怪。。。
您好,首先感谢您的文章翻译,关于buffer,我有点疑问,请指导。
CharBuffer buff = CharBuffer.allocate(8);
System.out.println(“capacity:”+buff.capacity());
System.out.println(“limit:”+buff.limit());
System.out.println(“position:”+buff.position());
buff.put(‘a’);
buff.put(‘b’);
buff.put(‘c’);
System.out.println(“加入三个元素后,position=”+buff.position());
buff.flip();
System.out.println(“执行flip后,limit=”+buff.limit());
System.out.println(“position=”+buff.position());
//取出第一个元素
System.out.println(“第一个元素(position=0):”+buff.get());
System.out.println(“取出第一个元素后,position=”+buff.position());
buff.clear();
System.out.println(“执行clear方法后,limit=”+buff.limit());
System.out.println(“执行clear方法后,position=”+buff.position());
System.out.println(“执行clear后,缓冲区的内容并没有被清空.第三个元素为:”+buff.get(2));
System.out.println(“执行绝对读取后,position=”+buff.position());
麻烦您看上边这段代码,这段代码是在一本Java资料中讲NIO中的一段代码,声明了buffer,然后调用flip,之后读取第一个元素,然后调用buffer的clear方法,看您文章上说clear会清空整个缓冲区,如果是这样,当我clear后,再使用buffer.get(index)应该没有任何数据才对,可是我上边的代码在执行clear后再调用buff.get(2)依然可以取到第三个元素。这是不是说明buffer调用clear之后并不清空缓冲区,而只是重置了position和limit的位置,为下一次的读取做准备而已呢?麻烦了。谢谢
从源码的逻辑来看,你说的确实是对的,clear不是清空缓存,只是重置了position和limit的位置。
clear 并没有清理而是设置了postion和limit的值,让过去的数据被遗忘
写的真好!
上述代码在读取中文的文本内容时,一定会乱码,因为中文占多个字节,上面是一个字节一解码,肯定有问题, 改成下面这种写法:
RandomAccessFile aFile = new RandomAccessFile(“D:/a.txt”, “rw”);
FileChannel inChannel = aFile.getChannel();
//create buffer with capacity of 48 bytes
ByteBuffer buf = ByteBuffer.allocate(48);
int bytesRead = 0; //read into buffer.
while ((bytesRead = inChannel.read(buf)) != -1) {
buf.flip(); //make buffer ready for read
byte[] b = buf.array();
System.out.println(new String(b, 0, bytesRead, “gbk”));
buf.clear(); //make buffer ready for writing
}
aFile.close();
这种写法能避免小文件的乱码情况,当文件超过48字节也可能会有问题.
假设ByteBuffer的capacity设置为3, 读取内容为”abcde中国”的文本,第一次读取3个字节即abc然后按照gbk解码没有问题, 第二次读取”de”和”中”的第一个字节,满了三个字节,进行解码,这时de可以正常解码,但后面的中只有一个字节,按gbk解码肯定乱码,所以,当一个文本可以完全被ByteBuffer装下时是没有问题的,一旦ByteBuffer不能完全装下,在中英文混杂时,极有可能某个汉字只读取了部分字节就被解码了造成乱码,怎么解决?
请问你解决了这个循环造成的乱码问题吗?我也是刚发现,目前没想到好的方法,只能把文件编码格式转换了定长的编码,然后ByteBuffer分配的空间,刚好能够整除定长编码所占的空间就不会出现乱码了。
怎么觉得这段代码无法运行呢。。。。
简洁明了,评论也不错,帮助进一步理解。
非常好的总结,我发现一处错误,可能是手误:equals()方法的描述是比较position和limit之间的数据(当前正在使用的数据)
我发现一个乱码的问提,当使用while循环的时候,不能保证最后的几个byte刚好处理一个完整的字符,尤其是使用变长编码(Unicode)的时候,出现乱码的概率会更大。当使用ASCII编码是没问题的,因为它是1Byte,就算ByteBuffer分配一个byte也能正常读取。
感觉NIO的使用场景还是在tcp通讯实现非阻塞IO的用处比较多,在读写文件方面好像并不是特别好。
尤其是使用byteBuffer循环读取非ASCII编码字符,实在是无法保证读取的字节是完整的。
position最大可为capacity – 1.
这句有问题,position最大可为capacity
赞同。
写得真好,彻底解决了我的疑问。