消息队列二三事
最近在看kafka的代码,就免不了想看看消息队列的一些要点:服务质量(QOS)、性能、扩展性等等,下面一一探索这些概念,并谈谈在特定的消息队列如kafka或者mosquito中是如何具体实现这些概念的。
Kafka在0.10版本推出了Stream API,提供了对存储在Kafka内的数据进行流式处理和分析的能力。
本文将从流式计算出发,之后介绍Kafka Streams的特点,最后探究Kafka Streams的架构。
Producer APIs
Producer API封装了底层两个Producer:
如果你想学习分布式系统,Cassandra可以说是一个好的开始。 Cassandra借鉴了两篇重要的论文中的思想:Google的BigTable和Amazon的Dynamo。它的存储基于BigTable,分布式基于Dynamo。这篇文章将尝试解释整体架构中的一些细节。
原文链接 译者:andy huang
(雅虎Storm团队排名不分先后) Sanket Chintapalli, Derek Dagit, Bobby Evans, Reza Farivar, Tom Graves, Mark Holderbaugh, Zhuo Liu, Kyle Nusbaum, Kishorkumar Patil, Boyang Jerry Peng and Paul Poulosky。
免责声明:2015年12月17日的数据,数据团队已经给我们指出,我们不小心在Flink基准测试中留下的一些调试代码。 所以Flink基准测试应该不能直接与Storm和Spark比较。 我们在重新运行和重新发布报告时已经解决了这个问题。
原文链接 译者:小村长
本项目是 Hortonworks开发者认证官方文档的中文翻译版,Hortonworks致力于打造一个全新的大数据处理平台来满足大数据处理和分析的各个使用场景,它组合了大数据平台使用的各个组件, 比如Hadoop、Hbase、Hive、Spark等等一些列的组件, 它安装方便使用便捷, 而且已经在2000节点以上的节点上商用. 本次翻译主要针对对Hortonworks感兴趣和致力于从事大数据方法开发的人员提供有价值的中文资料,希望能够对大家的工作和学习有所帮助。
由于我公司鼓励大家考Hortonworks认证(呵呵,公司出费用),于是今天简单的看了下官方考试大纲,感觉还不错,故翻译了下供大家参考学习,本次翻译并没有咬文嚼字, 而是根据我个人的理解进行翻译, 由于本人能力有限难免有些地方翻译不到位,还希望大家谅解,同时也鼓励大家去看官方文档。
原文链接 译者:小村长
本项目是 Apache Spark官方文档的中文翻译版,致力于打造一个全新的大数据处理平台来满足大数据处理和分析的各个使用场景,本次翻译主要针对对Spark感兴趣和致力于从事大数据方法开发的人员提供有价值的中文资料,希望能够对大家的工作和学习有所帮助。
Spark最近几年在国内外都比较火,在淘宝、百度、腾讯、高伟达等一些公司有比较成熟的应用,做大数据方面的开发人员或多或少都与其有接触。Spark的中文资料相对前几年相对较多,但是我认为官方文档才是最好最完美的学习资料,今天让小村长为你揭开Spark的神秘面纱,一同走进Spark的精神世界。 阅读全文
zookeeper 是一个分布式的,开源的协调服务框架,服务于分布式应用程序。
它暴露了一系列的基础的操作服务,因此分布式应用能够基于这些服务,构建出更高级别的服务,比如同步,配置管理,分组和命名服务。
zookeeper设计上易于编码,数据模型构建在我们熟悉的树形结构目录风格的文件系统中。
zookeeper运行在java中,同时支持java和C 语言。正确的实现协调服务是公认的难干的差事。 他们及其容易出错,比如资源竞争和死锁.
zookeeper 的使命和力量来源于,将分布式应用从处理协调服务的泥潭中走出来。





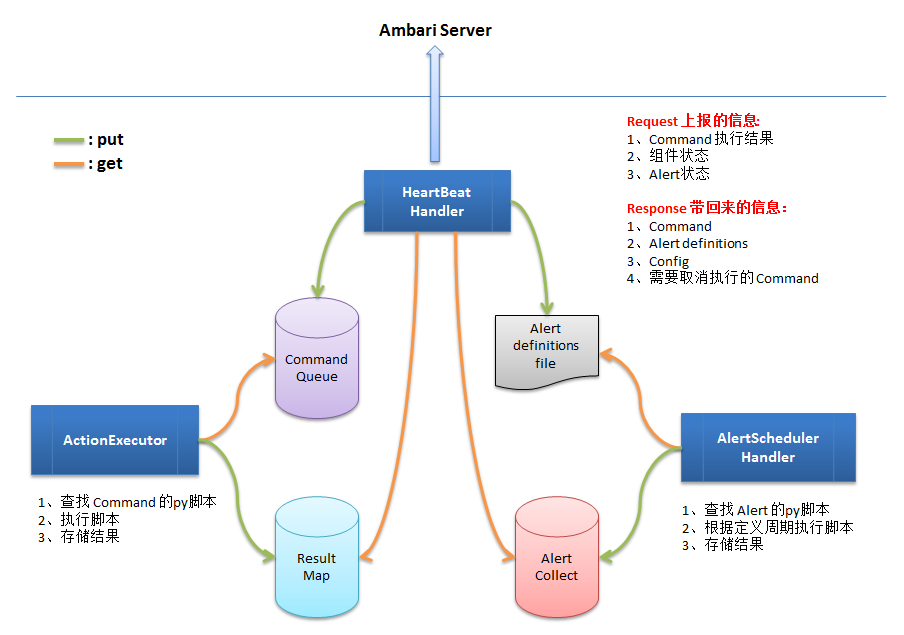
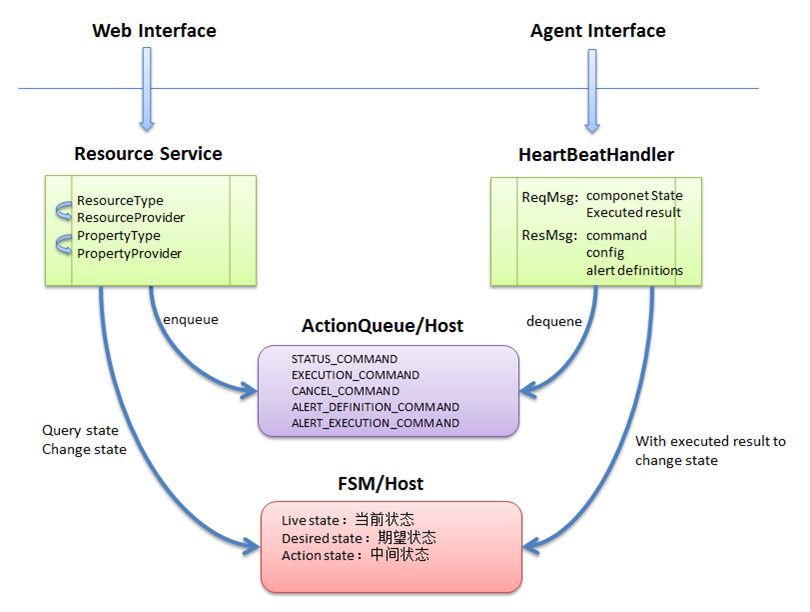 主要有4部分:
主要有4部分: