聊聊Cassandra-概览
如果你想学习分布式系统,Cassandra可以说是一个好的开始。 Cassandra借鉴了两篇重要的论文中的思想:Google的BigTable和Amazon的Dynamo。它的存储基于BigTable,分布式基于Dynamo。这篇文章将尝试解释整体架构中的一些细节。
数据模型(Data Model)
在关系型数据库中的一些常见术语在Cassandra中则有不同的定义。如果你能暂时忘记常规的定义,则阅读本文可能会更加顺利。
列(Colunmn)
“列”由一个name,一个相关的value和一个时间戳组成。name和value可以是任何类型,name不需要是字符串。一个列就是一个Name-Value-Timestamp集合。
列族(Column Family)
可以想象成在关系数据库中一行所包含的一个key和一些列。
超列族(Super Column Family)
就是一个列族,这个列族中每个列的值就是一个列的集合。
大家可能会有些疑惑,可以看看下面的图片:
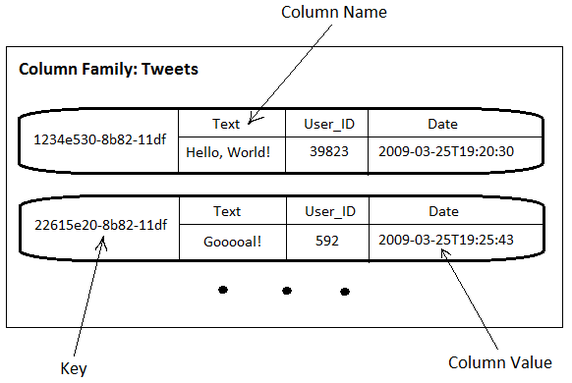

对Column Family再多说两句。一个column family 可以被定义为一个有序rows的集合,每个row都包含了一个有序的columns的集合。Cassandra是一个自由的模式,之后你可以在任意时刻添加任意column到任意column family中。Columns不需要相同,并且每行都不需要有相同数量的columns。尽管这样,在相同的column family有相同的columns还是比较好的,因为每个column family都存储在一个单独的文件中。
一个column family 有一个name和一个比较器,比较器的的值决定了columns的排序。每行中的key被用来决定该行存储在集群中哪个节点中。
KeySpaces
是数据最外层的容器。可以把它想象成RDBMS中的一个数据库。尽管不是必须的,但是为每个应用创建一个单独的keyspace比较好。一个keyspace有一个name和一些别的属性(比如说复制因子,复制策略等)。
Clusters
Cassandra运行在多个节点(一个集群)之上,它在集群间复制数据,所以当有一个节点宕机,另外的节点能接管工作。这让Cassandra是高可用的。
简而言之,Cassandra的数据模型像下面这样:
Cluster => Keyspace => Column Families (Standard or Super) => Column => (Name, Value, Timestamp)
一致性哈希
Cassandra是一个分布式数据库,一般会运行在多个机器上。在这些节点中,我们该怎么划分数据呢?可以使用一个简单的策略,比如在N个节点的集群中,把数据存放在(hash(key)%N)个机器上,但是当一个节点增加或者删除的时候会引起一些问题,因为每个节点上的数据都会变化。为了避免这种情况,我们使用一致性哈希。
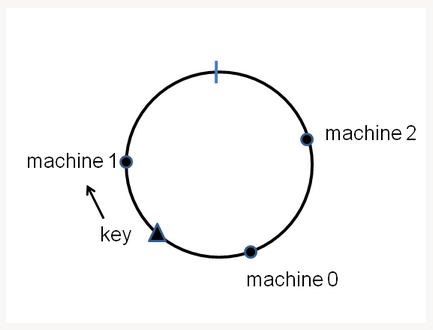
在一致性哈希中,机器被放在一个逻辑上的圆环上,如下图所示,key同样也在这个圆环上,并被分配到顺时针的最近一个机器上,并复制N份到顺时针前的节点上(N被称为复制因子)。Cassandra是一个最终一致性的存储系统, 会在后台进行复制操作。客户端没必要等待所有的副本写入完成,可以设置要等待完成写入的节点数。
现在,如果我们从圆环上增加或删除一个机器,key只会在移动到和它相邻的节点上去。
反熵(Anti-Entropy) 和 读修复
Anti-Entropy是Cassandra的一个副本同步机制,来保证在不同节点上的数据都被更新到最新的版本。Anti-Entropy使用Merkle Trees,对于每个column family,都会构造这个tree。为什么叫Anti-Entropy呢?在一个最终一致性性的数据库中,随着时间流逝,应该被精确复制的节点都会慢慢互相偏差。这个偏差可以被认为是系统的“entropy”。反熵 就是让节点之间互相同步的过程。
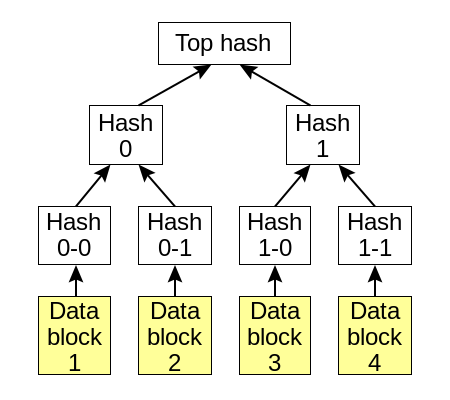
Hash Tree被交换用来找出陈旧的数据。他们被用来减少节点之间的数据交换。Hashes trees看起来像下面这样:
当反熵 开始的时候,hash trees被构建,并在节点之间互相交换。而不是交换真实的数据。然后从root开始比较。如果某些节点的hash不一样,我们可以准确的判断出哪些数据是陈旧的。
Memtables,SSTable and Commit Logs
一个写操作会立即写到节点的commit log中。只有当这个请求被写入到commit log中的时候,它才被认为是成功的。在被写入commit log之后,这个value被写入到一个被称为memtable的内存结构中。当memtable的大小到达一个阈值的时候,它就被刷到磁盘中的SSTable中。Memtables根据key进行排序,然后被顺序的写到磁盘中。因此,写入是非常快的。
在磁盘中的一个SSTable是不可变的。若干个SSTable被一个compaction程序合并到一起。每个SSTable都有一个相关的布隆过滤器和一个索引。布隆过滤器可以快速的检查一个元素是否在这个集合中。
读的时候,Cassandra首先会检查memtable。然后会尝试查找所有的SSTable。
Compaction
在压缩期间,SSTable会被合并:key会被合并,标记为tombstones 的数据会被丢弃,会创建新的索引。
什么是tombstones?
当一个值被 删除的时候,他不会真正的被删除,但是会给他一个tombstone标记。为什么要这么做呢?因为如果一个值在一个副本中被删除,而在另外的副本中没被删除,当重新调节的时候,系统会认为被删除值的副本是没有被更新的,然后又重新写入这个值。Tombstones显然会浪费空间,并且需要被清除。一个anti-entropy 开始的时候,在压缩的时候是最好摆脱他们的时机。在每次GCGraceSeconds之后,Tombstones被会垃圾收集。
在压缩的时候,合并的数据会被排序,一个新的索引也会被创建,然后新的合并后的数据、索引数据都会被写到一个单独的新的SSTable中。
Gossip 和失败检测
Cassandra使用Gossip协议来内部交流,所以每个节点都能知道别的节点的信息。 gossiper每秒运行一次。当节点发现目标节点上线的时候,会触发暗示提交。
gossiper会定期的随机选择一个节点,并和它开始一个gossip回话。每个回合需要三种信息:
1.发送一个GossipDigestSynMessage给它选择的节点。
2.当节点收到信息的是,他也返回一个GossipDigestAckMessage。
3.当节点收到ack信息的时候,他发送一个GossipDigestAck2Message给友节点来完成一个gossip回合。
每个节点都包含了死亡节点和可用节点的列表。Cassandra使用一个 Phi Accrual Failure Detection 技术来替代传统的“heat beat”来检查节点是否死亡。这个技术使用一个怀疑度概念来找出可能的死亡节点。
暗示提交(Hinted Handoff)
由于某些原因,节点的某些写入的数据不可用。其他节点将会处理这个写请求,并且等待着节点回来,当这个节点上线的时候,它会把写入又发回给节点。这被称为暗示提交。为什么是暗示提交呢?
- 当一致性不是必须的时候保证高可用
- 减少死亡节点上线所需要的时间
一个写入请求会被发送到所有的副本,当达到要求的数量的节点返回的时候,这个写入会被认为是成功的。
所以,这只是Cassandra架构的一个基本的概览。一些主题如一致性哈希、anti-entropy 等等。在后面我将单独讲这些东西。
原创文章,转载请注明: 转载自并发编程网 – ifeve.com本文链接地址: 聊聊Cassandra-概览

 (8 votes, average: 4.00 out of 5)
(8 votes, average: 4.00 out of 5)

暂无评论