Memory Barriers/Fences
原文地址:http://mechanical-sympathy.blogspot.com/2011/07/memory-barriersfences.html(因墙转载)
In this article I’ll discuss the most fundamental technique in concurrent programming known as memory barriers, or fences, that make the memory state within a processor visible to other processors.
CPUs have employed many techniques to try and accommodate the fact that CPU execution unit performance has greatly outpaced main memory performance. In my “Write Combining” article I touched on just one of these techniques. The most common technique employed by CPUs to hide memory latency is to pipeline instructions and then spend significant effort, and resource, on trying to re-order these pipelines to minimise stalls related to cache misses.
When a program is executed it does not matter if its instructions are re-ordered provided the same end result is achieved. For example, within a loop it does not matter when the loop counter is updated if no operation within the loop uses it. The compiler and CPU are free to re-order the instructions to best utilise the CPU provided it is updated by the time the next iteration is about to commence. Also over the execution of a loop this variable may be stored in a register and never pushed out to cache or main memory, thus it is never visible to another CPU.
CPU cores contain multiple execution units. For example, a modern Intel CPU contains 6 execution units which can do a combination of arithmetic, conditional logic, and memory manipulation. Each execution unit can do some combination of these tasks. These execution units operate in parallel allowing instructions to be executed in parallel. This introduces another level of non-determinism to program order if it was observed from another CPU.
Finally, when a cache-miss occurs, a modern CPU can make an assumption on the results of a memory load and continue executing based on this assumption until the load returns the actual data.
Provided “program order” is preserved the CPU, and compiler, are free to do whatever they see fit to improve performance.
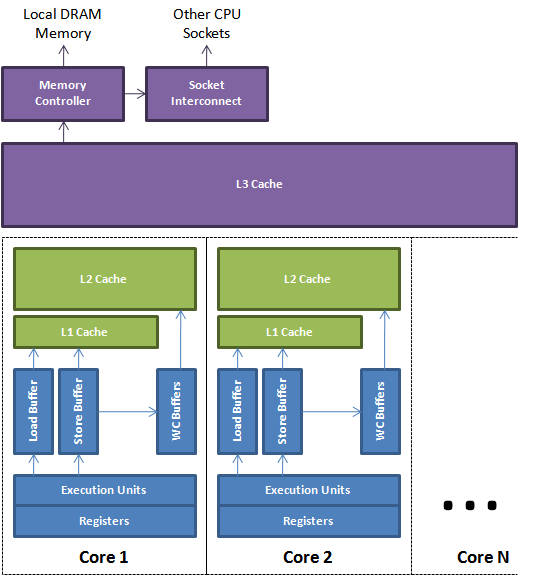 |
| Figure 1. |
Loads and stores to the caches and main memory are buffered and re-ordered using the load, store, and write-combining buffers. These buffers are associative queues that allow fast lookup. This lookup is necessary when a later load needs to read the value of a previous store that has not yet reached the cache. Figure 1 above depicts a simplified view of a modern multi-core CPU. It shows how the execution units can use the local registers and buffers to manage memory while it is being transferred back and forth from the cache sub-system.
In a multi-threaded environment techniques need to be employed for making program results visible in a timely manner. I will not cover cache coherence in this article. Just assume that once memory has been pushed to the cache then a protocol of messages will occur to ensure all caches are coherent for any shared data. The techniques for making memory visible from a processor core are known as memory barriers or fences.
Memory barriers provide two properties. Firstly, they preserve externally visible program order by ensuring all instructions either side of the barrier appear in the correct program order if observed from another CPU and, secondly, they make the memory visible by ensuring the data is propagated to the cache sub-system.
Memory barriers are a complex subject. They are implemented very differently across CPU architectures. At one end of the spectrum there is a relatively strong memory model on Intel CPUs that is more simple than say the weak and complex memory model on a DEC Alpha with its partitioned caches in addition to cache layers. Since x86 CPUs are the most common for multi-threaded programming I’ll try and simplify to this level.
Store Barrier
A store barrier, “sfence” instruction on x86, forces all store instructions prior to the barrier to happen before the barrier and have the store buffers flushed to cache for the CPU on which it is issued. This will make the program state visible to other CPUs so they can act on it if necessary. A good example of this in action is the following simplified code from the BatchEventProcessor in the Disruptor. When the sequence is updated other consumers and producers know how far this consumer has progressed and thus can take appropriate action. All previous updates to memory that happened before the barrier are now visible.
private volatile long sequence = RingBuffer.INITIAL_CURSOR_VALUE;// from inside the run() methodT event = null;long nextSequence = sequence.get() + 1L;while (running){ try { final long availableSequence = barrier.waitFor(nextSequence); while (nextSequence <= availableSequence) { event = ringBuffer.get(nextSequence); boolean endOfBatch = nextSequence == availableSequence; eventHandler.onEvent(event, nextSequence, endOfBatch); nextSequence++; } sequence.set(nextSequence - 1L); // store barrier inserted here !!! } catch (final Exception ex) { exceptionHandler.handle(ex, nextSequence, event); sequence.set(nextSequence); // store barrier inserted here !!! nextSequence++; }} |
Load Barrier
A load barrier, “lfence” instruction on x86, forces all load instructions after the barrier to happen after the barrier and then wait on the load buffer to drain for that CPU. This makes program state exposed from other CPUs visible to this CPU before making further progress. A good example of this is when the BatchEventProcessor sequence referenced above is read by producers, or consumers, in the corresponding barriers of the Disruptor.
Full Barrier
A full barrier, “mfence” instruction on x86, is a composite of both load and store barriers happening on a CPU.
Java Memory Model
In the Java Memory Model a volatile field has a store barrier inserted after a write to it and a load barrier inserted before a read of it. Qualified final fields of a class have a store barrier inserted after their initialisation to ensure these fields are visible once the constructor completes when a reference to the object is available.
Atomic Instructions and Software Locks
Atomic instructions, such as the “lock …” instructions on x86, are effectively a full barrier as they lock the memory sub-system to perform an operation and have guaranteed total order, even across CPUs. Software locks usually employ memory barriers, or atomic instructions, to achieve visibility and preserve program order.
Performance Impact of Memory Barriers
Memory barriers prevent a CPU from performing a lot of techniques to hide memory latency therefore they have a significant performance cost which must be considered. To achieve maximum performance it is best to model the problem so the processor can do units of work, then have all the necessary memory barriers occur on the boundaries of these work units. Taking this approach allows the processor to optimise the units of work without restriction. There is an advantage to grouping necessary memory barriers in that buffers flushed after the first one will be less costly because no work will be under way to refill them.
原创文章,转载请注明: 转载自并发编程网 – ifeve.com本文链接地址: Memory Barriers/Fences




暂无评论