Java FP: Java中函数式编程的Map和Fold(Reduce)
原文链接 作者: Cyrille Martraire 译者: 李璟(jlee381344197@gmail.com)
在函数式编程中,Map和Fold是两个非常有用的操作,它们存在于每一个函数式编程语言中。既然Map和Fold操作如此强大和重要,但是Java语言缺乏Map和Fold机制,那么该如何解释我们使用Java完成日常编码工作呢?实际上你已经在Java中利用手动编写循环的方式实现了Map和Fold操作(译者注:许多动态语言如python都提供了内置的实现)。
免责声明:本篇文章仅仅只是一篇入门简介,并非函数式编程的参考。函数式编程爱好者可能会不赞同本文观点。
你已经很熟悉Map和Fold
假设这里有一个List<Double>,存储了不含增值税VAT(译者注:Value Added Tax)的金额列表,现在我们想把这个列表转换成包含增值税金额的列表。首先我们定义一个方法,为金额添加增值税:
[code lang=”java”]
public double addVAT(double amount, double rate) {
return amount * (1 + rate);
}
[/code]
现在将这个方法应用到每份金额上:
[code lang=”java”]
public List<Double> addVAT(List<Double> amounts, double rate) {
final List<Double> amountsWithVAT = new ArrayList<Double>();
for(double amount : amounts) {
amountsWithVAT.add(addVAT(amount, rate));
}
return amountsWithVAT;
}
[/code]
我们创建了一个输出列表,它的大小与输入列表一致,存储了对输入列表中每个元素应用了addVAT()之后的结果。恭喜你,我们刚才手工完成了对输入列表应用addVAT()的Map操作。让我们再来一次。
现在我们想利用汇率把每一份金额转换成另一种货币的金额,所以我们需要一个新的函数:
[code lang=”java”]
public List<Double> convertCurrency(List<Double> amounts, double currencyRate) {
final List<Double> amountsInCurrency = new ArrayList<Double>();
for(double amount : amounts) {
amountsInCurrency.add(convertCurrency(amount, currencyRate));
}
return amountsInCurrency;
}
[/code]
请注意,这两个方法接收同样的列表,除了在以下第2步稍显不同:
- 创建一个输出列表。
- 为输入列表中每个元素调用某个给定的函数,将函数结果存入输出列表中。
- 返回输出列表。
你经常使用Java完成上述的工作,这正式一个标准的Map操作:对输入列表list<T>中的每个元素应用给定的函数someMethod(T),返回一个同样大小的Map结果列表list<T>。
函数式编程语言意识到这样特殊的需求(为集合中每个元素应用某个方法)是非常常见的,所以设计者把这种行为封装到了内建函数Map中。这意味着,对于给定的addVAT(double, double) 方法,我们可以直接利用Map操作写出这样的代码:
[code lang=”java”]
List amountsWithVAT = map (addVAT, amounts, rate);
[/code]
是的,第一个参数是一个函数。因为在函数式编程语言中,函数是第一要素,所以函数可以被当做是参数传递给方法。
代码中使用了Map操作,将会比使用了循环更加清晰以及更加不容易出错,并且代码的意图会更加明确,但是Map操作并不存在于Java中。
以上例子的重点是,你已经很熟悉你甚至不知道的函数式编程关键概念:Map操作。
现在轮到Fold操作
回到之前提到的包含了金额的列表中,现在我们需要计算列表中每个金额之和。很简单,我们用循环实现:
[code lang=”java”]
public double totalAmount(List<Double> amounts) {
double sum = 0;
for(double amount : amounts) {
sum += amount;
}
return sum;
}
[/code]
基本上我们将了“+=”函数,应用到列表中每一个数字元素上,递增式地把每个元素并拢到一个元素里,实现了一个Fold操作。Fold与Map类似,不同的是Fold返回一个标量而非一个列表。
同样,这也是你经常用Java编写的代码,现在这段代码拥有了在函数式编程语言中的名字:Fold或者Reduce。在函数式编程语言中,Fold操作通常是递归式的,这里不进行深入讨论。然而,我们可以在一个循环体内,利用可变状态累加每次循环之后的结果,实现类似Fold的操作。在这种方式中,Fold操作将一个带有内部可变变量并且读取单个参数的函数,比如someMethod(T),应用到输入列表list<T>中的每个元素中,一直到产生最后的Fold操作的结果之后结束。
典型的Fold操作如累加,逻辑与、逻辑或,List.add()和List.addAll(),StringBuilder.append(),max以及min等。
Fold的思想与SQL中的聚集函数类似。
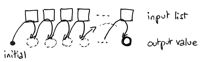
在图形中思考
可以利用草图辅助我们思考。Map操作读取一个长度为n的列表,并且返回一个处理过后的同样大小的列表:

另一方面,Fold操作读取一个长度为n的列表,返回一个标量:
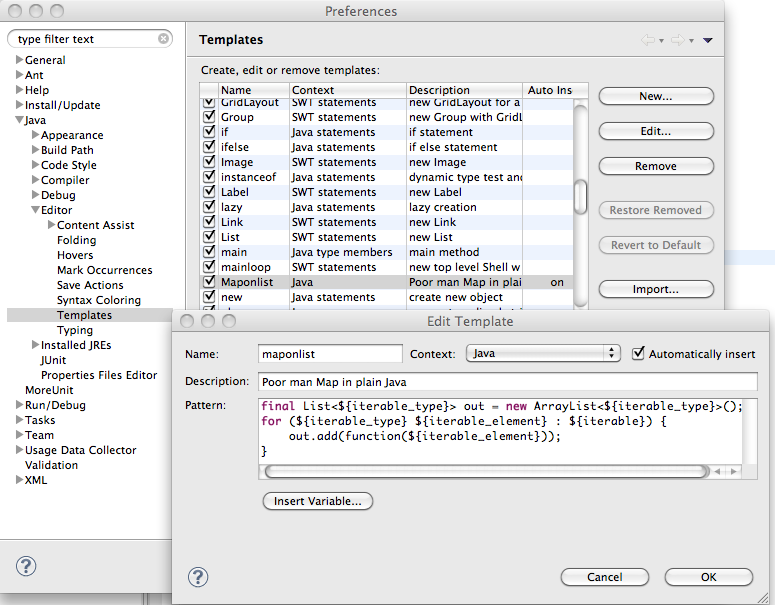
Eclipse模板
Map和Fold如此常用,我们在Eclipse中为这两个操作创建模板,比如Map:
走进Java中的Map和Fold
Map和Fold是一种期望读取到函数对象作为参数的代码结构。在Java中,将待传递函数包装到接口中,传递此接口的某个实现,是唯一的实现传递函数的途径。
在Apache Commons Collections中,有两个接口能满足我们的需求:只有transform(T):T方法的Transformer接口以及只有execute(T):void方法的Closure接口。CollectionUtils为Java集合类提供了简陋的类似Map的collect(Iterator, Tramformer)方法,以及一个利用Closure模拟Fold操作的的forAllDo()方法。
Google Guava的Iterables提供了一个静态的Map操作方法transform(Iterable, Function)。
[code lang=”java”]
List<Double> exVat = Arrays.asList(new Double[] { 99., 127., 35. });
Iterable<Double> incVat = Iterables.transform(exVat, new Function<Double, Double>() {
public Double apply(Double exVat) {
return exVat * (1.196);
}
});
System.out.println(incVat); //print [118.404, 151.892, 41.86]
[/code]
类似的transform方法的实现同样可以用在List和Map集合类中。
为了在Java中模拟Fold操作,可以使用Apache Common Collection中的Closure接口,该接口仅包含一个execute(T):void方法,所以你必须在内部维护当前可变状态,就像“+=”操作那样。
不幸的是,尽管被强烈要求,但是Guava中没有类似Fold操作的实现,甚至连类似闭包的功能都没有。但是实现你自己的Fold操作其实并不难,比如,你可以用以上提到的类简单封装:
[code lang=”java”]
// the closure interface with same input/output type
public interface Closure<T> {
T execute(T value);
}
// an example of a concrete closure
public class SummingClosure implements Closure<Double> {
private double sum = 0;
public Double execute(Double amount) {
sum += amount; // apply ‘+=’ operator
return sum; // return current accumulated value
}
}
// the poor man Fold operator
public final static <T> T foreach(Iterable<T> list, Closure<T> closure) {
T result = null;
for (T t : list) {
result = closure.execute(t);
}
return result;}
@Test // example of use
public void testFold() throws Exception {
SummingClosure closure = new SummingClosure();
List<Double> exVat = Arrays.asList(new Double[] { 99., 127., 35. });
Double result = foreach(exVat, closure);
System.out.println(result);// print 261.0
}
[/code]
并非只为简单集合:在树形结构和其他结构上进行Fold
除了能操作简单集合,还能应用于任何有向结构中,这是Map和Fold的强大之处。
想象一下,一个树形结构将Node类作为它的子节点。把深度优先搜索DFS和广度优先搜索BFS分别编写到一个通用的接收Closure作为参数的方法中,会是一个非常不错的主意:
[code lang=”java”]
public class Node …{
…
public void dfs(Closure closure){…}
public void bfs(Closure closure){…}
}
[/code]
我以前经常使用这样的技巧,并且我发现利用一个通用的方法替代许多看起来相似的方法之后,可以大幅减少类的大小。最重要的是,可以通过伪造闭包实现遍历的单元测试,每个闭包同时也可以独立地进行单元测试。
访问者模式同样可以实现相似的功能,有可能你已经非常熟悉这个模式了。我不止一次在代码中发现,访问者模式非常适用于在遍历数据结构期间对状态的累加。在这个条件下,该访问者就是一个Fold操作的传递给其他函数的特殊闭包Closure。
一句话描述Map-Ruduce
也许你已经听过Map-Reduce模式。是的,Map和Reduce分别指的是我们提到过的Map和Fold的函数操作。虽然实际的应用程序非常复杂,但是不难理解,Map操作是高度并行的,所以可以将其用于做大量的并行运算。
参考文献
Thinking functional programming with Map and Fold in your everyday Java
原创文章,转载请注明: 转载自并发编程网 – ifeve.com本文链接地址: Java FP: Java中函数式编程的Map和Fold(Reduce)



写得不错,但面向对象的语言,面向函数的语言,以及两者结合的语言,但想用好他们,其实泛型的协变和逆变的使用时机,非常的重要。
java8的function的定义中,经常会用到。
我一直有些困惑
有资料说:
输入参数,要求得少,可以给调用者提供更小的要求,所以一般可以使用逆变,即“下界通配符”
输出参数,提供得多,可以给调用者返回更具体更大范围的信息,所以一般可以使用协变,即“上界通配符”
但又有资料说:
输入,如果是数据信息的提供者,则最好使用上界通配符
输出,如果是数据信息的提供者,则最好使用下界通配符
请看此文
http://docs.oracle.com/javase/tutorial/java/generics/wildcardGuidelines.html
再看此文
file:///E:/pdf_resoucrce/19_04_java8/tutorial/extra/generics/morefun.html
朋友,能给总结一二吗?
谢谢
你好。
请问file:///E:/pdf_resoucrce/19_04_java8/tutorial/extra/generics/morefun.html有网页地址吗? 我本地是看不到的
http://docs.oracle.com/javase/tutorial/extra/generics/morefun.html
http://docs.oracle.com/javase/tutorial/java/generics/wildcardGuidelines.html
java,c#,scala等都涉及到泛型,只要是泛型,类库的编写者都需要充分利用“泛型协变和泛型逆变”来提高灵活性与安全性
您还可以看一下c#的官方解释,c#使用in关键字来修饰泛型,代表该参数是符合“逆变”的,使用out关键字来修饰泛型,代表该参数是符合“协变”的。
而scala使用+,-来分别代表协变和逆变
如果没有很好的掌握这个使用协变和逆变的原则,就很难在开发中,将自己设计的API泛型化。
希望能在本网开辟这一主题的高级讨论。
另外,在scala快学一书中也有相关解释,但感觉也是没有解释清楚,你也可以参考一下。
好的,我看看