深入浅出ClassLoader
Dedicate to Molly.
你真的了解ClassLoader吗?
这篇文章翻译自zeroturnaround.com的 Do You Really Get Classloaders? ,融入和补充了笔者的一些实践、经验和样例。本文的例子比原文更加具有实际意义,文字内容也更充沛一些,非常感谢作者 Jevgeni Kabanov 能够共享如此优秀的文档。
Dedicate to Molly.
这篇文章翻译自zeroturnaround.com的 Do You Really Get Classloaders? ,融入和补充了笔者的一些实践、经验和样例。本文的例子比原文更加具有实际意义,文字内容也更充沛一些,非常感谢作者 Jevgeni Kabanov 能够共享如此优秀的文档。
译者:大胃 原文链接
从Velocity 1.2以后的版本,开发者对于Velocity引擎的使用有了两种方式,单例模型(Singleton)以及多个独立实例模型。Velocity的核心部分也采用了这两种模型,目的是为了让Velocity可以更容易与你的JAVA应用相集成。
原文链接 译者: 李璟(jlee381344197@gmail.com)
这是一块非常简单的Java代码片段:
[code lang=”java”]
public class HelloWorld{
public static void main(String []args){
int product = 1;
for (int i = 10; i <= 99; i++) {
product *= i;
}
System.out.println(product);
}
}
[/code]
为什么得出的结果是0呢?
原文链接 作者: Plumbr 译者:之诸暇
许多事件都可能会导致JVM暂停所有的应用线程。这类暂停又被称为”stop-the-world”(STW)暂停。触发STW暂停最常见的原因就是垃圾回收了(github中的一个例子),但不同的JIT活动(例子),偏向锁擦除(例子),特定的JVMTI操作,以及许多场景也可能会导致应用程序暂停。
原文链接 译文链接 作者:Tai Truong 译者:Jaxon
所有的Java开发人员可能会遇到这样的困惑?我该为堆内存设置多大空间呢?OutOfMemoryError的异常到底涉及到运行时数据的哪块区域?该怎么解决呢?
Java内存模型在JVM specification, Java SE 7 Edition, and mainly in the chapters “2.5 Runtime Data Areas” and “2.6 Frames”中有详细的说明。对象和类的数据存储在3个不同的内存区域:堆(heap space)、方法区(method area)、本地区(native area)。 阅读全文
欢迎各位光临并发编程网,并发网最近几年一直致力于翻译优秀的技术文章,从未间断,并发网从本月开始计划组织翻译各个技术框架的官方指南,本月组织翻译Apache Velocity官方指南。Velocity是在阿里巴巴和支付宝等公司被广泛使用的一种基于Java的模板引擎,有兴趣翻译的同学请在评论中回复翻译章节和完成时间,翻译完之后提交到并发编程网,网站使用指南请参考:如何投稿。
原文链接 作者:Dimitris Andreou 译者:魏嘉鹏 校对:方腾飞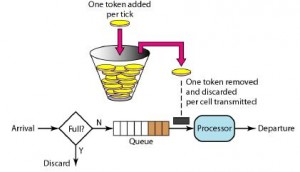
RateLimiter 从概念上来讲,速率限制器会在可配置的速率下分配许可证。如果必要的话,每个acquire() 会阻塞当前线程直到许可证可用后获取该许可证。一旦获取到许可证,不需要再释放许可证。
校对注:RateLimiter使用的是一种叫令牌桶的流控算法,RateLimiter会按照一定的频率往桶里扔令牌,线程拿到令牌才能执行,比如你希望自己的应用程序QPS不要超过1000,那么RateLimiter设置1000的速率后,就会每秒往桶里扔1000个令牌。
[code lang=”java”]
com.google.common.util.concurrent.RateLimiter
@ThreadSafe
@Betapublic
abstract class RateLimiter extends Object
[/code]
原文地址 原文作者:Benjamin Winterberg 译者:张坤
欢迎阅读我的Java8并发教程的第一部分。这份指南将会以简单易懂的代码示例来教给你如何在Java8中进行并发编程。这是一系列教程中的第一部分。在接下来的15分钟,你将会学会如何通过线程,任务(tasks)和 exector services来并行执行代码。
并发在Java5中首次被引入并在后续的版本中不断得到增强。在这篇文章中介绍的大部分概念同样适用于以前的Java版本。不过我的代码示例聚焦于Java8,大量使用lambda表达式和其他新特性。如果你对lambda表达式不属性,我推荐你首先阅读我的Java 8 教程。
几天前,我偶然地将之前写的用来测试AtomicInteger和synchronized的自增性能的代码跑了一下,意外地发现AtomicInteger的性能比synchronized更好了,经过一番原因查找,有了如下发现:
在jdk1.7中,AtomicInteger的getAndIncrement是这样的:
作者:Nikita Salnikov-Tarnovski 译者:Amanda 校对:
“你好,你能过来看看帮我解决一个奇怪的问题么。”就是这个技术支持案例使我想起写下这篇帖子。眼前的这个问题就是关于不同工具对于可用内存大小检测的差异。
其实就是一个工程师在调查一个应用程序的过高的内存使用情况时发现,尽管该程序已经被指定分配2G堆内存,但是JVM检测工具似乎并不能确定进程实际能用多少内存。例如 jconsole显示可用堆内存为1,963M,然而 jvisualvm 却显示能用2,048M。所以到底哪个工具才是对的,为什么检测结果会出现差异呢?
这确实是个挺奇怪的问题,特别是当最常出现的几种解释理由都被排除后,看来JVM并没有耍一些明显的小花招:
颠覆大数据分析之结论
译者:吴京润 购书
随着Hadoop2.0到来——被称作YARN的Hadoop新版本——超越Map-Reduce的思想已经稳固下来。就像本章要解释的,Hadoop YARN将资源调度从 MR范式分离出来。需要注意的是在Hadoop1.0,Hadoop第一代,调度功能是与Map-Reduce范式绑定在一起的——这意味着在HDFS上惟一的处理方式就是Map-Reduce或它的业务流程。这一点已在YARN得到解决,它使得HDFS数据可以使用非Map-Reduce范式处理。其含义是,从事实上确认了Map-Reduce不是惟一的大数据分析范式,这也是本书的中心思想。 Hadoop YARN允许企业将数据存储在HDFS,并使用专业框架以多种方式处理数据。比如,Spark可以借助HDFS上的数据迭代运行机器学习算法。(Spark已重构为工作在YARN之上,感谢Yahoo的创新精神),还有GraphLab/Giraph可以借助这些数据用来运行基于图的算法。显而易见的事实是,主要的Hadoop发行版已宣布支持Spark(Cloudera的),Storm(Hortonworks的),还有Giraph(Hortonworkds的)。所有的一切,本书一直主张的超越Hadoop Map-Reduce的思想已通过Hadoop YARN得到了验证。本章概述了Hadoop YARN以及不同的框架(Spark/GraphLab/Storm)如何工作在它上面工作。
MR范式分离出来。需要注意的是在Hadoop1.0,Hadoop第一代,调度功能是与Map-Reduce范式绑定在一起的——这意味着在HDFS上惟一的处理方式就是Map-Reduce或它的业务流程。这一点已在YARN得到解决,它使得HDFS数据可以使用非Map-Reduce范式处理。其含义是,从事实上确认了Map-Reduce不是惟一的大数据分析范式,这也是本书的中心思想。 Hadoop YARN允许企业将数据存储在HDFS,并使用专业框架以多种方式处理数据。比如,Spark可以借助HDFS上的数据迭代运行机器学习算法。(Spark已重构为工作在YARN之上,感谢Yahoo的创新精神),还有GraphLab/Giraph可以借助这些数据用来运行基于图的算法。显而易见的事实是,主要的Hadoop发行版已宣布支持Spark(Cloudera的),Storm(Hortonworks的),还有Giraph(Hortonworkds的)。所有的一切,本书一直主张的超越Hadoop Map-Reduce的思想已通过Hadoop YARN得到了验证。本章概述了Hadoop YARN以及不同的框架(Spark/GraphLab/Storm)如何工作在它上面工作。



 (19 votes, average: 4.53 out of 5)
(19 votes, average: 4.53 out of 5)