角色对象模式
作者:Dirk Bäumer, Dirk Riehle, Wolf Siberski, and Martina Wulf 原文链接 译者:f0tlo <1357654289@qq.com>
意图
单个对象透过不同的角色对象来满足不同客户的不同需求。每一个角色对象针对不同的客户内容来扮演其角色。对象能够动态的管理其角色集合。角色作为独立的对象是的不同的内容能够简单的被分离开来,系统间的配置也变得容易。
原文链接 作者:Pankaj Kumar 译者:f0tlo <1357654289@qq.com>
命令模式是一种行为模式,因此,它处理的是对象的行为。命令模式为系统中不同的对象提供中性化的交流媒介。根据GoF的定义,命令模式是:
通过封装一组完全不相关的对象相互之间的的交互及通讯来完成松耦合。 允许某一个对象的行为的变化是独立于其他对象的。
在企业级应用中,命令模式是非常有用的,它使得多个对象可以相互交流。如果一些对象与另一些对象直接交流,系统组件之间是紧耦合的方式。这种方式导致系统具有更高的可维护性,可扩展的灵活性变得很低。命令模式专注于提供一个调解人介于需要交流的对象之间来帮助完成对象间的松耦合。
阅读全文
原文链接 作者:Pankaj Kumar 译者:f0tlo <1357654289@qq.com>
状态模式是一种行为设计模式。适用于当对象的内在状态改变它自身的行为时。
如果想基于对象的状态来改变自身的行为,通常利用对象的状态变量及if-else条件子句来扮演针对对象的不同行为。状态模式Context(环境)和State(状态)分离的方式既保证状态与行为的联动变化,又使得这种变化是条理明晰且松耦合的。
感谢同事【向西】投递本稿
云OS 3.0已发布,总算向外界表达了我们想做个啥,很多人也开始质疑,Cloud Card到底是个啥?云OS 3.0算不算自主研发的OS?等等,今天想就Cloud Card能否干掉App这个主题聊聊这些事情。
装饰者模式可以给已经存在的对象动态的添加能力。下面,我将会用一个简单的例子来演示一下如何在程序当中使用装饰者模式。
1.装饰者模式
让我们来假设一下,你正在寻找一个女朋友。有很多来自不同国家的女孩,比如:美国,中国,日本,法国等等,他们每个人都有不一样的个性和兴趣爱好,如果需要在程序当中模拟这么一种情况的话,假设每一个女孩就是一个Java类的话,那么就会有成千上万的类,这样子就会造成类的膨胀,而且这样的设计的可扩展性会比较差。因为如果我们需要一个新的女孩,就需要创建一个新的Java类,这实际上也违背了在程序开发当中需要遵循的OCP(对扩展开放,对修改关闭)原则。
让我们来重新做另外一种设计,让每一种个性或者兴趣爱好成为一种装饰从而可以动态地添加到每一个女孩的身上。
tomcat在处理每个连接时,Acceptor角色负责将socket上下文封装为一个任务SocketProcessor然后提交给线程池处理。在BIO和APR模式下,每次有新请求时,会创建一个新的SocketProcessor实例(在之前的tomcat对keep-alive的实现逻辑里也介绍过可以简单的通过SocketProcessor与SocketWrapper实例数对比socket的复用情况);而在NIO里,为了追求性能,对SocketProcessor也做了cache,用完后将对象状态清空然后放入cache,下次有新的请求过来先从cache里获取对象,获取不到再创建一个新的。
这个cache是一个ConcurrentLinkedQueue,默认最多可缓存500个对象(见SocketProperties)。可以通过socket.processorCache来设置这个缓存的大小,注意这个参数是NIO特有的。
接下来在SocketProcessor执行过程中,真正的业务逻辑是通过一个org.apache.coyote.Processor的接口来封装的,默认这个Processor的实现是org.apache.coyote.http11.Http11Processor。我们看一下SocketProcessor.process(...)方法的大致逻辑:
tomcat的最大连接数参数是maxConnections,这个值表示最多可以有多少个socket连接到tomcat上。BIO模式下默认最大连接数是它的最大线程数(缺省是200),NIO模式下默认是10000,APR模式则是8192(windows上则是低于或等于maxConnections的1024的倍数)。如果设置为-1则表示不限制。
在tomcat里通过一个计数器来控制最大连接,比如在Endpoint的Acceptor里大致逻辑如下:
对于acceptCount这个参数,含义跟字面意思并不是特别一致(个人感觉),容易跟maxConnections,maxThreads等参数混淆;实际上这个参数在tomcat里会被映射成backlog:
static {
replacements.put("acceptCount", "backlog");
replacements.put("connectionLinger", "soLinger");
replacements.put("connectionTimeout", "soTimeout");
replacements.put("rootFile", "rootfile");
}
backlog表示积压待处理的事物,是socket的参数,在bind的时候传入的,比如在Endpoint里的bind方法里:
原文链接 译者:张军 校对:方腾飞
本文将并发和内存管理做了个类比。最近有一个说法是因为现代工程师几乎总是面对计算机集群编程,所以我们需要用于构建分布式系统的工具。这就意味着我们需要在语言层面支持分布式系统开发。像GO和Erlang这样的语言其优势正好符合这个观点。
GO和Erlang可能最终会流行,但我不认为是这个原因。分布式系统开发并不会成为每个应用开发者日常工作的一部分,因为那将会是件非常痛苦的事情。在某种程度上,我想今天发生的事情是因为缺乏良好的分布式计算框架,而迫使应用去重新实现一些分布式系统原语。但这种情况不会一直存在,而必将有一些框架提供不同的编程模型,在弹性机器池上处理分布和并发问题。
MapReduce已经解决了这个问题。MapReduce编程几乎都是单线程的,并发是由框架来管理,另外有助于你写好MapReduce程序的原因是,有很多用户级别(user-level)的并发原语,并且MapReduce是高度并行的。 阅读全文
感谢同事【沐剑】的投稿
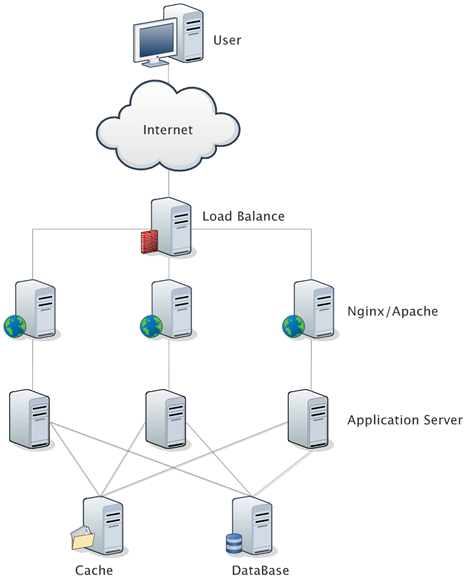
在大规模互联网应用中,负载均衡设备是必不可少的一个节点,源于互联网应用的高并发和大流量的冲击压力,我们通常会在服务端部署多个无状态的应用服务器和若干有状态的存储服务器(数据库、缓存等等)。
负载均衡设备的任务就是作为应用服务器流量的入口,首先挑选最合适的一台服务器,然后将客户端的请求转发给这台服务器处理,实现客户端到真实服务端的透明转发。最近几年很火的「云计算」以及分布式架构,本质上也是将后端服务器作为计算资源、存储资源,由某台管理服务器封装成一个服务对外提供,客户端不需要关心真正提供服务的是哪台机器,在它看来,就好像它面对的是一台拥有近乎无限能力的服务器,而本质上,真正提供服务的,是后端的集群。
一个典型的互联网应用的拓扑结构是这样的:



 (4 votes, average: 4.00 out of 5)
(4 votes, average: 4.00 out of 5)