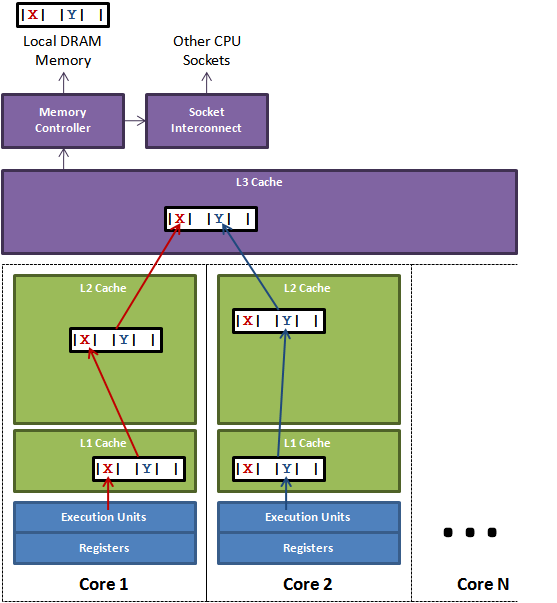
CPU Cache Flushing Fallacy
原文地址:http://mechanical-sympathy.blogspot.com/2013/02/cpu-cache-flushing-fallacy.html (因有墙移动到墙内)
Even from highly experienced technologists I often hear talk about how certain operations cause a CPU cache to “flush”. This seems to be illustrating a very common fallacy about how CPU caches work, and how the cache sub-system interacts with the execution cores. In this article I will attempt to explain the function CPU caches fulfil, and how the cores, which execute our programs of instructions, interact with them. For a concrete example I will dive into one of the latest Intel x86 server CPUs. Other CPUs use similar techniques to achieve the same ends. 阅读全文


 (32 votes, average: 4.31 out of 5)
(32 votes, average: 4.31 out of 5)