为什么无等待如此重要
无锁(完全同步)
想象一下,一个无锁算法或数据结构有一个方法,这个方法所有执行过程都需要同步。假设在单线程模式下这个方法每次调用需要10ns,而每增加一个线程调用这个方法,将在同步状态(变量)上产生争用。
很显然,如果只有一个线程,每次调用该方法到返回平均时间都为10ns,我们称之为:每10ns完成的任务数;如果你增加更多的线程,他们将会增加其他线程执行完成的时间,这是因为同一时刻只有一个线程能获得锁;
记住,无锁(Lock-Free)保证一个线程可以执行,但没说是哪一个,并且在当前这个特定的例子中,每次只有一个线程可以执行(完成任务),其他线程不得不从头开始:

上图中,W表示该线程赢得锁,L表示没有获得锁,意味着要重新获得;
无锁(少量同步)
上面的示意图并不能准确地描述大多数现存的无锁(Lock-Free)算法,大多数无锁算法不会将所有的时间都花在同步上,相反地,大部分时间通常花在跟算法自身相关的计算上,而这些计算并不需要重新计算当其他线程赢得运行权时,而实际上只有一部分时间是在做同步;
因此,让我们想象这样一种情况,方法需要10ns完成任务,但只有前2.5ns用来做同步;不难发现,平均而言每10ns我们可以有多个任务同时在多个线程/核上运行,准确地说,多达4个线程可以同时运行,如图所示:
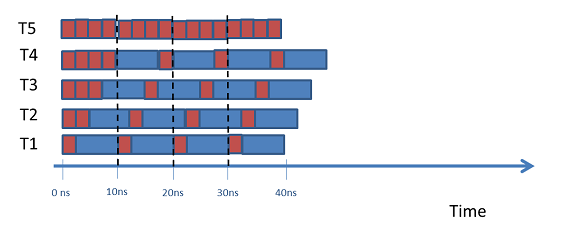
上述例子中,同步时间占了该方法运行时间10ns的四分之一;
此外,如果用一个图来表示随着线程数量的增加该算法的整体性能时,我们将会看到几乎是线性的扩展到4个线程,然后遇到瓶颈无法继续升高;如果线程数进一步增加,性能甚至降低:

注意我们假设至少有4核,能同时运行4个或更多线程;
Wait-Free-Population-Oblivious(集居数无关无等待)
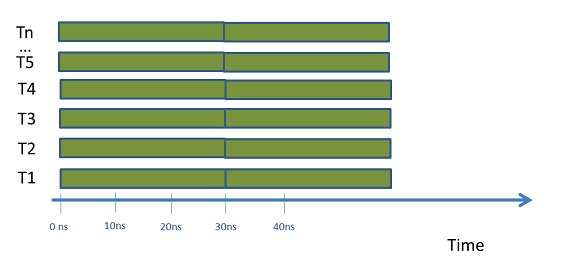
现在考虑一种不同的情况,有一个集居数无关无等待(Wait-Free-Population-Oblivious,简称WFPO)算法,我们假设该算法比前一个无锁(Lock-Free)算法慢3倍,即它需要30ns完成单个任务,但它是WFPO,依WFPO定义可知,只要你有足够多的核就能保证所有线程正在进展,因为它是集居数无关无等待(WFPO),不单单是无等待(Wait-Free);由同步产生的额外指令数不依赖于并发线程数,因此,仍能保持(或多或少)恒定的线程数增长;
示意图如下:
该算法随着线程数增长的总体性能表现如下图所示:
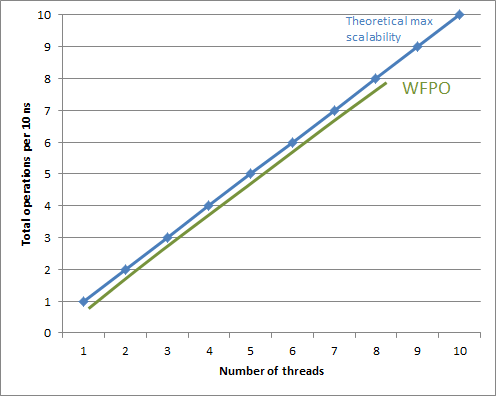
注意,性能能不断扩展直到所有的核都在运行线程,或者使用的同步原语由于一些硬件限制导致算法不再是集居数无关无等待(WFPO);
算法优化
再回到前面无锁(Lock-Free)的场景,同步花了1ns,假设有个聪明的家伙优化了计算时间,将原来的7.5ns优化为只需2.5ns,这意味着单线程模式下该算法的性能提高了一倍,那么在多线程模式下能获得多大的性能提升呢?
答案出乎意料,0。为什么是0,原因是线程只会在无竞争时运行,所以即使剩余的代码运行再快,每个线程仍然需要跟其他线程竞争且只有一个能获得锁并且执行,其他线程不得不重新竞争:

对于集居数无关无等待(WFPO)算法来说,如果你能设法将花在计算上的时间减少5ns,总体性能将得到17%(5 ns / 30 ns)左右的提升;
现在你会说:好吧,如果我们能将无锁(Lock-Free)算法花在同步上的时间从2.5ns优化为1ns该多好?
是的,你可以这么做,但你可能需要重新设计整个同步部分,这等于说你将设计一个新的无锁(Lock-Free)协同机制,它本身就是一个可发表的成果,但并不是一件容易的事(至少可以这么说),只有像Maurice Herlihy, Nir Shavit, or Doug Lea那样的人有能力做这种事,你能胜任吗?
无等待
常规无等待(Wait-Free)(非集居数无关)如何呢?
嗯,这取决于:如果随着线程数增加,操作数的增长非常平缓,那么性能可能会扩展和增加。
如果随着线程数增加,操作数成二次方地增长,那你就惨了,该算法不会比一个无锁(Lock-Free)算法好很多(甚至可能更差)。
基本上,非集居数无关无等待算法和数据结构处于无锁(Lock-Free)和集居数无关无等待(WFPO)之间。
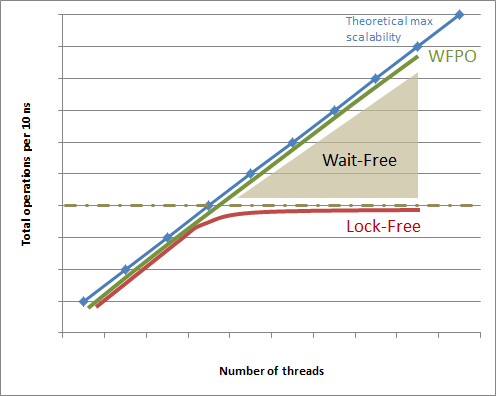
结论
无锁(Lock-Free)算法和数据结构固有的可扩展性上限,在某个点,无论使用多少线程/核都不会提高整体性能,由于高争用实际上可能还会降低性能。
在一定程度上增加更多线程执行无锁(Lock-Free)算法是好事,你会惊讶的是对于某些算法和数据结构这个限制点有多低。如果你有长远考虑,或者你的应用打算在大量线程/核上运行,还是选择集居数无关无等待(WFPO)算法吧,否则你不会走太远。
总结一句,忘了无锁(Lock-Free)和常规无等待(Wait-Free),如果你想设计一个算法可扩展到大量的并发线程,你需要的是集居无关无等待(WFPO)。
其实,这篇文章的标题应该是:“为什么集居数无关无等待(Wait-Free-Population-Oblivious)如此重要” ?
注:Wait-Free-Population-Oblivious-集居数无关无等待,翻译参考[1].
参考
[1] 多处理器编程的艺术
原创文章,转载请注明: 转载自并发编程网 – ifeve.com本文链接地址: 为什么无等待如此重要

 (4 votes, average: 4.00 out of 5)
(4 votes, average: 4.00 out of 5)

有点看不懂,是不是太菜了。。
您好,要理解这些概念,我建议按以下步骤走:
1.
http://ifeve.com/lock-free-and-wait-free/
这篇文章,首先对所有progress condition有一个大致的了解。
2.
了解Amadal law以及多核数据结构的主要概念,
http://ifeve.com/cds-plan/
事实上我们正在翻译这篇概论性的文章。
3.
多核并发算法主要分两个方面来讨论,一个是progress condition,即wait-free,lock-free等性质,这是程序员使用需要关心的。一个是correctness,如linearizablility等,这是科研人员需要关心的。
之所以多核并发算法很难设计,一个比较重要的原因是progress condition对应的是工程,实践层面,而correctness对应的是理论层面。设计者必须具有扎实的理论基础,还需要有较强的实践能力。
文中提到:
“但并不是一件容易的事(至少可以这么说),只有像Maurice Herlihy, Nir Shavit, or Doug Lea那样的人有能力做这种事,你能胜任吗?”
其中Maurice Herlihy本身是《多处理器编程的艺术》的第一作者,Nir Shavit是第二作者,他在STM(软件事务内存)领域有很大的贡献。Doug Lea则是J.U.C框架的开发者。他们都是美国高校的教授。
所以,正如文中说的,这本来就不是一件容易的事情……
如果能有实现集居数无关无等待(Wait-Free-Population-Oblivious)的代码配合食用更佳!The Art of Multiprocessor Programming这本书里应该是有的。