Tomcat7.0.26的连接数控制bug的问题排查
感谢同事[空蒙]的投稿。
首先感谢@烈元一起排查此问题。今天发现线上一台机器,监控一直在告警,一看是健康检查不通过,就上去查看了下,首先自己curl了下应用的url,果然是超时没有响应,那就开始按顺序排查了:
1、 load非常低,2、gc也正常,3、线程上也没死锁,4、日志一切正常。那是什么情况呢,不能忘记网络啊。果然,netstat命令一把,结果如下:
TIME_WAIT 68 CLOSE_WAIT 194 ESTABLISHED 3941 SYN_RECV 100
问题出来了,SYN_RECV竟然达到100个,正常情况下,半连接的请求应该是很小的。而且我们机器是内部的,不是lvs,不太会有半连接攻击,怎么可能达到这么大呢?
再grep SYN_RECV的连接,看到全部都是nginx在连接这台mtop机器,那接下来就dump tcp包看看了
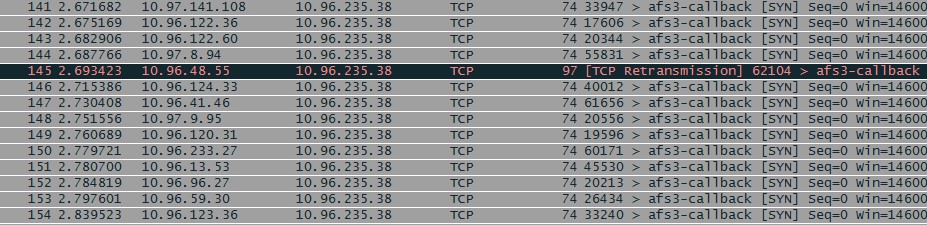
一看一堆堆的wjas向mtop发起SYN连接请求,可是mtop机器是绝大部分没回应,只有极少的mtop机器syn+ack包。
注:wjas一天向mtop发起了近20亿的健康检查请求,够多的,所以没有外部流量时,还是有一大堆的http请求到应用上。
看系统信息,内核是2.6.32-220.23.2.ali1113.el5.x86_64的,半连接队列的长度是128不同的内核,半连接队列长度算法稍有不同,可以参考文章:linux诡异的半连接(SYN_RECV)队列长度。
可见是mtop半连接队列满了,不再接受新的tcp连接,导致请求没有响应了,但应用其实很空闲。
问题表现很清楚了,接下来就是各种怀疑了,因为这机器为解决之前tcnative的crash bug,刚切换成了nio模式、又昨天我手贱,在上面搞过btrace,aliperf。自己也成嫌疑,但这是半连接队列满,要么受到半连接攻击(排除,内网不太可能有半连接攻击),要么是Accept线程没有及时处理,应用没有接收连接的请求,导致三次握手后的队列连接满再引起半连接队列满了。(总结起来好像很有逻辑,排查的时候没那么明确的,还在想各种可能)
我们知道,tomcat有一个Acceptor线程,监听在端口上,在收到连接请求后,会立刻把请求交个后面线程池处理,bio是直接拿线程等待数据,nio与apr会在poller线程上注册监听,也就是select模式,底层再基于epoll事件触发(和nginx的处理模式有点区别)。那就是这个Acceptor线程难道停止了。
查看堆栈信息,果然
 当前的这个acceptor已经被禁用了,需要唤醒,多次dump线程,发现此线程一直是这个状态,这就解释了为什么了。
当前的这个acceptor已经被禁用了,需要唤醒,多次dump线程,发现此线程一直是这个状态,这就解释了为什么了。
马上查看tomcat源码,发现此代码是在tomcat的连接数(nio)达到1w的时候,会park当前线程,再请求处理后,会再唤醒,继续接受新的连接,Btrace了一把,果然这个连接数值是1w,但什么情况下,会导致这个值那么大,一直把线程暂停呢?按说如果要达到这么大的连接,我们的T4机器早就鸡飞狗跳了。
Google一把,原来是tomcat7.0.27之前的bug,我们使用的刚好是7.0.26.中枪了,不管是nio,bio,apr,都存在这个问题。Tomcat的代码如下:
 当接受连接,出现异常时候,旧版本没有把这个数组减少,这时候就拼人品了,如果异常的请求累积,达到连接的最大值,就发生机器很闲,但tcp的连接队列与半连接队列满的情况了
当接受连接,出现异常时候,旧版本没有把这个数组减少,这时候就拼人品了,如果异常的请求累积,达到连接的最大值,就发生机器很闲,但tcp的连接队列与半连接队列满的情况了
tomcat在7.0.28修复了此问题,参见Tomcat 7 Changelog 。
1、如有遇到此类似情况,可看看是否这原因。
2、当最新版的jar或者容器稳定后,早点升级吧,特别是bug修复。
3、提供一次问题排查的参考。
原创文章,转载请注明: 转载自并发编程网 – ifeve.com本文链接地址: Tomcat7.0.26的连接数控制bug的问题排查





和我们之前遇到的现象类似,内部运行的飞起,没有任何错误,CPU内存完好无损,新请求进不去。后来看源代码+百度,发现resin用来accept请求的Port线程,也是有自己的增长规则,最小接受线程数(就是一个Runnable,被注册到nio 的selector,来socket请求后被选中后开始工作,扔给threadpool去执行),这队列配置默认是坑爹的16个,如果不满足增加条件,就自己等待60S…是60秒…..不是毫秒。。这期间请求暴增直接全部超时,60秒过后也要看人品,果断配置加大到1000多甚至更多。迎刃而解了。 在loadrunner 3000-5000并发压测下也表现较好,业务简单,不过threadpool的大小还有待研究,现在配置的1000. 上下文切换较多,尝试过配置过500,平均响应时间很差。切换确是少了。
对线程池最大值和CPU的计算公式表示怀疑,可能是研究的不够深,看现象和结果是宁可多点,也别为了减少上下文切换去减少数值,试想要是配置30-100,在压测3000的情况下,估计压测工具事物全挂了。
这种实战非常有价值,可以写一篇详细的文章发表在并发网上。
其实也没什么实战,这类问题无非就是看看源码,网上搜搜实现原理。一般都会有答案,目前JAVA系开源的无非就是NIO 线程池 各类并发API 队列等合理使用。太底层的epoll/select实现也搞不太懂,
之前评论里说的最大线程数的配置后来研究了一下,主要是网络IO次数太多了(memcached/mysql),毕竟是基于数据存储的项目,任意一个网络请求都要阻塞线程,CPU时间片就会流转到其他线程处理,要是配置线程很少,那CPU就只能原地等待不干活,所以导致结果惨不忍睹,所以根据测试结果配置多一点线程,让CPU去切换其他线程充分忙起来,每个CPU忙完一圈后回来处理IO阻塞完毕的就可以了,只要别配置过于多就行了。单独测试了一下无阻塞的场景,每个请求处理都是纯CPU计算,那样确实是线程池只配置CPU逻辑核数就是性能最好的。这也就是redis为什么敢单线程,memcache也默认只有4个线程的原因了,多了反而切换性能下降。
>> 导致三次握手后的队列连接满再引起半连接队列满了
这句话有点问题