Sharing Data Among Threads Without Contention
原文地址:http://www.oraclejavamagazine-digital.com/javamagazine/20120304/?pg=56&pm=1&u1=friend 作者 Trisha
The London Multi-Asset Exchange (LMAX) Disruptor is an open source concurrency framework that recently won the 2011 Duke’s Choice Award for Innovative Programming Framework. In this article, I use diagrams to describe what the Disruptor is; what it does; and, to some extent, how it works.
What Is the Disruptor?
The Disruptor is a framework for interthread communication (ITC), that is, the sharing of data among threads. LMAX created the Disruptor as part of its reliable messaging architecture and developed it into an extremely fast way of handing off data between different components.
Using mechanical sympathy (an understanding of how the underlying hardware works), fundamental computer science, and domain-driven design, the Disruptor has evolved into a framework that developers can use to do much of the heavy lifting for concurrent programming.
In many architectures, it is common to use a queue to share data (that is, pass messages) among threads. Figure 1 shows an example of passing messages between stages using a queue. (Each little blue spinner is meant to represent a thread.)
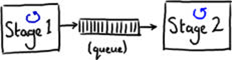
Figure 1
This architecture allows the producing thread (Stage 1 in Figure 1) to move on to the next piece of work if Stage 2 is too busy to accept the data immediately, which provides a way to deal with bursts of traffic in a system. The queue acts as a buffer between the threads.
In its simplest form, the Disruptor can be used in place of the queue in the architecture shown in Figure 2, in which messages are passed between stages using the Disruptor.
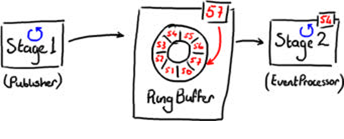
Figure 2
The data structure storing the messages is a RingBuffer, implemented as an array. Stage 1 places items into the RingBuffer, and Stage 2 reads items from the RingBuffer.
You’ll see in Figure 2 that each spot in the RingBuffer is indexed by a sequence number, and the RingBuffer tracks the highest (most recent) sequence number, which is the index pointing to the last item in the RingBuffer. This sequence number continually increases as more data is added to the ring.
The key thing about the Disruptor is that it was designed to have zero contention within the framework. This is achieved by following the single-writer principle—only one thing can ever write to a single piece of data. Following this principle eliminates the need for expensive lock or compare and swap (CAS) operations, which is one of the reasons the Disruptor is so fast.
One source of contention has been removed by having the RingBuffer and each EventProcessor track their own sequence numbers. This way, the only thing that ever updates a sequence number is the thing that owns the sequence number. This concept is covered in more detail when I describe writing to and reading from the RingBuffer.
Publishing to the Disruptor
Writing to the RingBuffer is achieved using a two-phase commit. First, Stage 1 (the Publisher) has to determine the next available slot in the RingBuffer, as shown in Figure 3.

Figure 3
The RingBuffer has the sequence number of the most recently written-to slot (Slot 18 in Figure 3) and, therefore, it can determine the next sequence number and, consequently, the corresponding slot in the array.
The RingBuffer determines whether the next slot is free by inspecting the sequence number of any EventProcessor that is reading from the RingBuffer. Figure 4 shows the next slot being claimed.
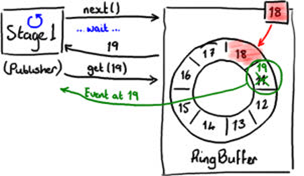
Figure 4
When the Publisher gets the next sequence number, it asks the RingBuffer for the object in that slot. The Publisher can then do what it likes to that object. You can think of the slot as a simple container that you write values into.
All the while, the RingBuffer sequence number is still Slot 18, so anything reading from the RingBuffer will not be able to read the event in Slot 19 while the Publisher is still working on it.
Figure 5 shows changes being committed to the RingBuffer.

Figure 5
Finally, when the Publisher is finished writing things into Slot 19, it tells the RingBuffer to publish the item that is in Slot 19. At this point, the RingBuffer updates its sequence number, and anything that wants to read from the RingBuffer can see the item in Slot 19.
Reading from the RingBuffer
The Disruptor framework includes a BatchEventProcessor that will read events from the RingBuffer for you, but I’m going to outline how that works to highlight the design.
While the Publisher needed to ask the RingBuffer for the number of the next slot to write to, an EventProcessor, which is kind of like a consumer except it doesn’t actually consume (remove) things from the RingBuffer, will track the last sequence number it processed and ask for the next sequence number it wants.
Figure 6 shows the EventProcessor waiting for the next expected sequence number.

Figure 6
Rather than asking the RingBuffer directly for its sequence number, an EventProcessor has a SequenceBarrier do this job. This detail is not important for the case we’re looking at now, but its purpose will become apparent later.
In Figure 6, Stage 2, the EventProcessor has seen up to sequence number 16. It wants the item at Slot 17 next, so it calls waitFor(17) on the SequenceBarrier. Stage 2 can happily hang around waiting for the next sequence number, because it might be that nothing else has written to the RingBuffer. If so, there’s nothing else to process. However, in the case shown in Figure 6, the RingBuffer has been populated up to Slot 18, so waitFor returns the number 18, telling the EventProcessor it can safely read anything up to and including Slot 18, as shown in Figure 7.

Figure 7
This methodology provides some really nice batching behavior, which you can see in the BatchEventProcessor code. The code simply asks the RingBuffer for every item from the next value it needs up to the highest available sequence number.
You can use this batching code by implementing EventHandler. There are examples of how to use batching in the Disruptor performance tests, for example FizzBuzzEventHandler.
Is It a Low-Latency Queue?
Sure, it can be used as such. We have figures from testing early versions of the Disruptor that show how much faster it is than ArrayBlockingQueue for a three-stage pipeline running on a 2.2 GHz Intel Core i7-2720QM processor using Java 1.6.0_25 64-bit on Ubuntu 11.04. Table 1 shows the latency per hop in the pipeline. For more details about this test, see the Disruptor technical paper.
But don’t think that these latency figures mean the Disruptor is a specialist solution for a specific performance niche, because it’s not.
More Cool Stuff
One of the interesting things about the Disruptor is how it supports graphs of dependencies between system components without incurring any of the cost of contention usually associated with sharing data among threads.
The Disruptor achieves contention free design by adhering to the single writer principle, so each bit of data can be written only by a single thread. However, that doesn’t mean you can’t have multiple readers. And that’s exactly what the Disruptor enables.
The system the Disruptor was originally designed to support had a staged pipeline of events that needed to happen in a particular order, which is not an uncommon requirement in an enterprise application. Figure 8 shows a standard three-stage pipeline.
![]()
Figure 8
First, each event is written to disk (journaling) for recovery purposes. Next, the events are replicated to secondary servers. Only after both these stages occur can the system be allowed to proceed with the real business logic.
Doing these tasks sequentially is a logical approach, but it is not the most efficient. Journaling and replication can happen in parallel, because they are not dependent on each other. But the business logic is dependent upon the other two events having taken place. Figure 9 shows how to parallelize the dependencies.
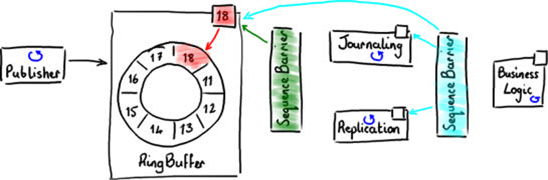
Figure 9
If you wire up the dependencies using the Disruptor, the first two stages (journaling and replication) can read directly from the RingBuffer. As with the simple case in Figure 7, they both use a single sequence barrier to get the next available sequence number from the RingBuffer. They track their own sequence numbers, so they know which events they’ve seen, and can process batches of events using a BatchEventProcessor.
The business logic can also read events from the same RingBuffer, but it is limited to processing only those events that the first two stages have successfully dealt with. This is achieved with a second SequenceBarrier, which is configured to inspect the sequence numbers of the journaling EventProcessor and the replication EventProcessor and return the lower of the two numbers when it is asked for a number that is safe to read up to.
After every EventProcessor has used the sequence barriers to determine the events that are safe to read from the RingBuffer, it can request them from the RingBuffer (see Figure 10).
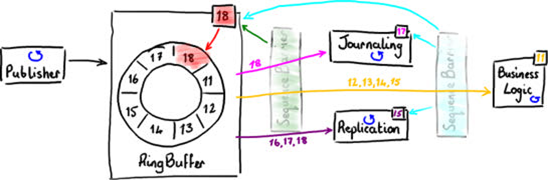
Figure 10
There’s a lot of reading of different sequence numbers—those from the RingBuffer, the journaling EventProcessor, and the replication EventProcessor—but only one thing can ever increment each sequence number. This ensures no contention on these values among the different threads.
What About Multiple Publishers?
The Disruptor also supports multiple publishers writing to the RingBuffer. However, because that entails two different things writing to the same place, this is a scenario in which you will get contention. The Disruptor provides different ClaimStrategy types for cases where you have more than one publisher.
Conclusion
I’ve talked at a high level about how the Disruptor is a framework for sharing data among threads in a very high performance fashion. I’ve also described a little about how it works. I didn’t touch on features such as more-advanced event processors and various strategies for claiming a slot in the RingBuffer and waiting for the next sequence in the RingBuffer. The Disruptor is open source—go explore the code!




暂无评论