《Redis官方教程》-基准测试
原文连接 译者:looyup
Redis有多快?
Redis 包含了工具程序redis-benchmark,它可以模拟运行命令,相当于模拟N个客户端同时发送总数M个查询(和apache的ab工具程序类似)。下面是在linux系统上执行benchemark后的完整输出,支持的选项如下:
Usage: redis-benchmark [-h <host>] [-p <port>] [-c <clients>] [-n <requests]> [-k <boolean>]
-h <hostname> Server hostname (default 127.0.0.1)
-p <port> Server port (default 6379)
-s <socket> Server socket (overrides host and port)
-a <password> Password for Redis Auth
-c <clients> Number of parallel connections (default 50)
-n <requests> Total number of requests (default 100000)
-d <size> Data size of SET/GET value in bytes (default 2)
-dbnum <db> SELECT the specified db number (default 0)
-k <boolean> 1=keep alive 0=reconnect (default 1)
-r <keyspacelen> Use random keys for SET/GET/INCR, random values for SADD
Using this option the benchmark will expand the string __rand_int__
inside an argument with a 12 digits number in the specified range
from 0 to keyspacelen-1. The substitution changes every time a command
is executed. Default tests use this to hit random keys in the
specified range.
-P <numreq> Pipeline <numreq> requests. Default 1 (no pipeline).
-q Quiet. Just show query/sec values
–csv Output in CSV format
-l Loop. Run the tests forever
-t <tests> Only run the comma separated list of tests. The test
names are the same as the ones produced as output.
-I Idle mode. Just open N idle connections and wait.
启动benchmark之前你得有个正在运行的Redis实例。运行benchmark典型示例如下:
redis-benchmark -q -n 100000
使用这个工具比较简单,你也可以实现你自己的benchmark,但是有些坑不要踩。
只运行一部分测试
不是每次运行redis-benchmark时,都要运行所有默认的测试。选择一部分来测试,只要简单地使用-t选项,如下:
$ redis-benchmark -t set,lpush -n 100000 -q
SET: 74239.05 requests per second
LPUSH: 79239.30 requests per second
上面的例子中,在安静模式下(参见-q选项),我们只测试了SET和LPUSH命令。也可以直接给benchmark指定命令,如下:
$ redis-benchmark -n 100000 -q script load “redis.call(‘set’,’foo’,’bar’)”
script load redis.call(‘set’,’foo’,’bar’): 69881.20 requests per second
选择key空间的大小
默认情况下,benchmark只针对单一个key测试。在人为测试环境和真实使用环境下,Redis表现出来的差别不是很大,因为它是一个内存系统。但如果使用更大范围的key,则可以测试缓存命中,并模拟一个更真实的工作负载。
使用-r选项就可以达到此目的,比如我想运行一百万次SET操作,每次操作从10万个key里面随机选一个,可以使用下面的命令:
$ redis-cli flushall
OK$ redis-benchmark -t set -r 100000 -n 1000000
====== SET ======
1000000 requests completed in 13.86 seconds
50 parallel clients
3 bytes payload
keep alive: 199.76% `<=` 1 milliseconds
99.98% `<=` 2 milliseconds
100.00% `<=` 3 milliseconds
100.00% `<=` 3 milliseconds
72144.87 requests per second$ redis-cli dbsize
(integer) 99993
管道化
默认情况下,每个模拟的客户端(如果不指定选项-c,benchmark模拟50个客户端)需要等待,只有收到前一条命令的响应之后才会发送下一条命令。这意味着,客户端发送的每条命令,服务器都需要一次read调用才能获得。当然,等待时间也得算上RTT的时间。
Redis支持/topics/pipelining即管道化,因此是可以一次发送多条命令的。现实中的应用经常用到这个特性。Redis在管道化模式下能够大幅提高服务器的每秒操作数。
下面的例子中,使用由16条命令的组成的管道,在一台MacBook Air 11″上运行benchmark:
$ redis-benchmark -n 1000000 -t set,get -P 16 -q
SET: 403063.28 requests per second
GET: 508388.41 requests per second
使用管道化可以大大地提高性能。
一些坑和误区
第一点很明显: benmark测试的黄金法则是只比较相互有可比性的东西。例如基于相同的工作负载比较不同版本的Redis。或者使用相同版本的Redis,但是使用不同的选项运行。如果你打算把Redis和其他什么东西进行比较,评估和考虑他们功能上和技术上的差异非常重要。
- Redis是个服务器:所有的命令在网络和IPC的之间都需要经过一个来回的过程。把redis和内嵌数据存储(embedded data stores)比如SQLite,Berkeley DB,Tokyo/Kyoto Cabinet等等进行比较没有意义,因为redis大多数操作的代价花在网络/协议管理上了。
- redis对所有常用命令都会返回一个确认。其他的数据存储未必这样,比如MongoDB就不确认写操作。把redis和单向查询的存储比较用处不大。
- 简单地迭代同步的Redis命令并不是测试redis,而是测算你的网络(或者IPC)延迟。要想真正测试redis,你需要多个连接(像redis-benchmark那样),使用多线程或多进程,使用管道化以便一次发多条命令。
- redis是一个内存数据存储(in-memory data store),也带一些持久化功能。如果打算把它和事务类服务器(MySQL, PostgreSQL等)进行比较,你得激活AOF,并且确定合适的fsync策略。
- redis是个单线程服务器,没有设计成利用多核cpu获得更多性能。如果需要的话,应该启动多个redis实例来利用多核。将单个redis实例和多线程的数据存储(multi-threaded data store)不大公平。
一种常见的误区是redis-benchmark被设计成使得redis性能看上去更好,redis-benchmark的吞吐量似乎有点假,而不是由真实应用输出的。这种认识实际是不对的。
要获得和评估一个redis实例在给定硬件上的性能,使用redis-benchmark程序是一种快速且有用的方式。然而,默认情况下,redis-benmark并不能测出一个redis实例所能承受的最大吞吐量。实际上,通过使用管道化和快速客户端(hiredis),写一个吞吐量比redis-benchmark更高的程序是相当容易的。redis-benchmark的默认行为仅仅是利用并发性来达成吞吐量(即创建了好几个连接到服务器),并没有使用管道化或者任何并行操作(每个连接上最多一条等待处理的查询,也没有多线程)。
要使用管道化运行一个benchmark获得更大吞吐量,你需要加上-P选项。注意,这样比较切实,因为很多基于redis的应用积极使用管道化来提高性能。
最后,进行多个数据存储比较时,benchmark应该处在相同的工作模式下,使用相同的操作。把redis-benchmark的测试结果和其他benchmark程序的结果比较和推断,没什么意义。
例如,可以对redis和单线程模式的memcached基于GET/SET操作进行比较。两个都是内存数据存储,协议层几乎是一样的工作方式。如果各自的benchmark程序以同样的方式(管道化)汇集多条查询,并使用差不多的连接数,这样的比较才有意义。
Redis (antirez) 和memcached (dormando) 的开发人员之间的对话就是最好的例子。
antirez 1 – On Redis, Memcached, Speed, Benchmarks and The Toilet (校对注:欢迎在ifeve.com翻译发表此文)
dormando – Redis VS Memcached (slightly better bench) (校对注:不能访问)
antirez 2 – An update on the Memcached/Redis benchmark
从最后的结果可以看到,考虑所有技术相关的方面,这两种解决方案之间的差异并没有大得让人出乎意料。注意,在这些性能测试之后,redis和memcached已经又进一步优化了。
最后,在测试那些高效的服务器时(redis和memcache肯定属于这一类),其实很难让服务达到满负荷。有时性瓶颈在客户端这边,而不是服务器那边。这种情况下,要让服务器达到最大吞吐量,客户端(也就是benchmark程序本身)必须得修复或扩展。
影响redis性能的因素
有多种因素会直接影响redis的性能。这里,我们分析一些,因为它们可以改变所有benchmark测试的结果。但请注意,一个典型的redis实例,运行在低速、未调优过的系统上,提供的性能对大多数应用来说也是够好的。
- 网络带宽和延迟常常是直接影响性能。启动benchmark程序前,使用ping程序快速检查客户端和服务器之间的延迟是一种好习惯。关于带宽,一般用Gbit/s来评估吞吐量,并和网络的理论带宽比较。例如,一个benchmark以每秒100000次设置4KB的string到redis中,将消耗2Gbit/s的带宽,一般需要带宽为10Gbit/s的链接,而不是1Gbit/s的链接。在很多现实的场景中,redis吞吐量先受到网络限制,然后才是CPU。要在一台机器上整合多个高性能的redis实例,要考虑装一块10Gbit/s或者多块1Gbit/s的TCP/IP网卡。
- CPU是另一个重要的因素。作为单线程的,redis喜欢高速有大缓存而不是有多个核的cpu。这场较量中,intel cpu是赢家。redis使用AMD Operon CPU时的性能只达到使用Nehalem EP/Westmere EP/Sandy Bridge Intel CPUs时的一半,这并不稀奇。当客户端和服务器运行在同一个系统上,cpu就是redis-benchmark的限制因素。
- ram的速度和内存带宽对全局性能的影响则次要多了,尤其是小数据对象时。对大对象(大于10KB)而言,影响会明显一些。一般来说,买昂贵的快速内存来优化redis并不是很经济的做法。
- 相同的硬件上,运行在虚拟机上的redis会比运行在真实系统上的redis慢。如果可以在物理机上运行redis是最好的。当然,这并不意味着,在虚拟环境下redis就慢,处理性能依然很好,虚拟环境下,可能遇到的大多数性能问题是由于预留空间(over-provisioning),高延迟的非本地磁盘(non-local disks with high latency),或者哪些使用低速fork系统调用实现的旧管理程序(hypervisor)。
- 当服务器和客户端benchmark程序运行同一系统上时,TCP/IP回路和unix域套接字都可使用。取决于平台,使用unix域套接字可以比使用TCP/IP回路多大约15%的吞吐量(比如在linux上)。redis-benchmark默认使用TCP/IP回路。
- 大量使用管道化(即长管道)时,比起使用TCP/IP,unix域套接字的性能提升会有所下降。
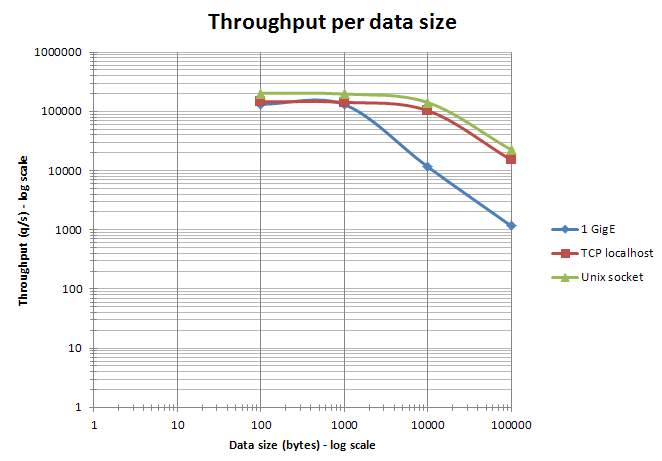
- 使用以太网访问redis,数据大小保持小于以太网报文大小(大约1500字节),使用管道化汇集多条命令特别有效。实际上,处理10字节,100字节,1000字节的查询几乎是一样的吞吐量。如下图。
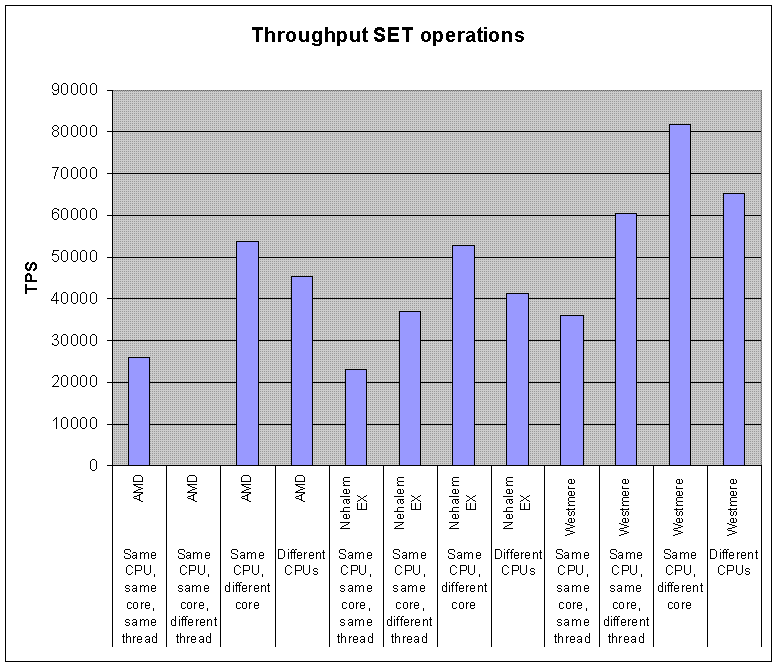
- 在有多个CPU插口的服务器上,redis的性能依赖于NUMA配置和进程位置。最明显的是,redis-benchmark的结果似乎无法确定,因为客户端和服务器进程随机分配在这些核上。要得到确定性的结果,得使用进程安置工具(linux上是taskset或numactl)。最有效的组合是,总是把客户端和服务器进程放在cpu不同的核上,充分利用起L3缓存。使用4KB的SET命令,在不同的进程安置组合下, benchmark测试三个CPU(AMD Istanbul, Intel Nehalem EX, and Intel Westmere)的结果如下。请注意,这个benchmark测试并不是为了比较CPU型号本身(这里并未标出CPU的准确型号和频率)。
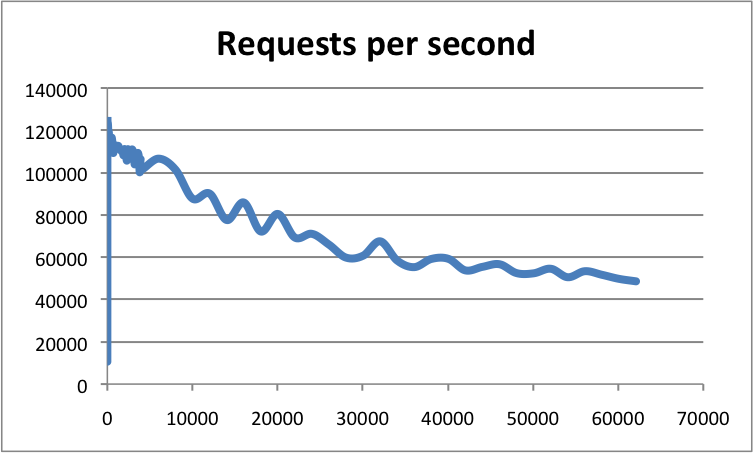
- 使用高级配置,客户端连接数也是很重要的因素。基于epoll/kqueue,redis的事件循环伸缩性较好。redis已经测试过超过60000连接,这些条件下,仍然能承受每秒50000次请求。经验告诉我们,有30000连接的redis,只能处理100连接时一半的吞吐量。下面的例子中显示各连接数下,redis实例对应的吞吐量:
- 在高级配置上,通过调优NIC的配置和对应的中断,可能会获得更高的吞吐量。通过设置和CPU核数相近的网卡队列数,并激活RPS(Receive Packet Steering),则可以获得最大吞吐量。更多内容清参考这里。传送大对象时,使用大容量帧(Jumbo frames)也可以提升性能。
- 看平台支持情况,redis可以在编译时指定使用不同的内存分配器(libc malloc, jemalloc, tcmalloc),从原始速度(raw speed),内部和外部碎片这些方面看,行为表现会有不同。如果不是自己编译的redis,可以使用命令INFO查看内存分配器。和生产环境的redis相比,benchmark运行的时间不够长,无法产生足够多的外部碎片。
其他要考虑的事情
benchmark的一个重要目的是得到可重复的结果,这样才能和其他测试的结果进行比较。
- 好的做法是尽可能地在孤立的硬件上运行测试。如果没条件,则必须监控系统确保benchmark没有受外界活动影响。
- 某些机器(桌面和笔记本肯定支持,有些服务器也支持)支持可变的cpu 核心频率。控制策略可以在OS层设置。某些CPU型号在改变CPU频率适应工作负载方面比其他型号更快。要得到可重复的结果,在测试时,最好把所有CPU核的频率固定设在最高值。
- 根据benchmark测试,调整系统也是很重要的。系统必须要有足够的RAM,不使用SWAP。在LINUX上不要忘记正确设置overcommit_memory参数。注意32位和64位的redis使用的内存空间是不一样的。
- 如果打算使用RDB或AOF,请确保系统中没有其他I/O活动。避免把RDB或AOF文件在NAS或NFS上共享,或放在其他影响网络带宽或延迟的设备上(比如Amazon EC2的EBS)。
- 设置redis的日志级别(参数loglevel)为warning 或notice。避免把日志放在远程文件系统上。
- 避免使用影响benchmark结果的监控工具。比如,定期使用INFO收集统计信息是可以的,但MONITOR则会对测试的性能结果有较大影响。
不同虚拟机和裸机上的benchmark结果
- 同时使用50个客户端发送2百万请求进行测试
- 所有测试使用版本6.14
- 使用回路接口测试
- 使用1百万的key空间测试
- 使用管道化(汇集16条命令)和不使用管道化分别测试
Intel(R) Xeon(R) CPU E5520 @ 2.27GHz (with pipelining)
$ ./redis-benchmark -r 1000000 -n 2000000 -t get,set,lpush,lpop -P 16 -q
SET: 552028.75 requests per second
GET: 707463.75 requests per second
LPUSH: 767459.75 requests per second
LPOP: 770119.38 requests per second
Intel(R) Xeon(R) CPU E5520 @ 2.27GHz (without pipelining)
$ ./redis-benchmark -r 1000000 -n 2000000 -t get,set,lpush,lpop -q
SET: 122556.53 requests per second
GET: 123601.76 requests per second
LPUSH: 136752.14 requests per second
LPOP: 132424.03 requests per second
Linode 2048 instance (with pipelining)
$ ./redis-benchmark -r 1000000 -n 2000000 -t get,set,lpush,lpop -q -P 16
SET: 195503.42 requests per second
GET: 250187.64 requests per second
LPUSH: 230547.55 requests per second
LPOP: 250815.16 requests per second
Linode 2048 instance (without pipelining)
$ ./redis-benchmark -r 1000000 -n 2000000 -t get,set,lpush,lpop -q
SET: 35001.75 requests per second
GET: 37481.26 requests per second
LPUSH: 36968.58 requests per second
LPOP: 35186.49 requests per second
更多未使用管道化的详细测试
$ redis-benchmark -n 100000
====== SET ======
100007 requests completed in 0.88 seconds
50 parallel clients
3 bytes payload
keep alive: 158.50% <= 0 milliseconds
99.17% <= 1 milliseconds
99.58% <= 2 milliseconds
99.85% <= 3 milliseconds
99.90% <= 6 milliseconds
100.00% <= 9 milliseconds
114293.71 requests per second====== GET ======
100000 requests completed in 1.23 seconds
50 parallel clients
3 bytes payload
keep alive: 143.12% <= 0 milliseconds
96.82% <= 1 milliseconds
98.62% <= 2 milliseconds
100.00% <= 3 milliseconds
81234.77 requests per second====== INCR ======
100018 requests completed in 1.46 seconds
50 parallel clients
3 bytes payload
keep alive: 132.32% <= 0 milliseconds
96.67% <= 1 milliseconds
99.14% <= 2 milliseconds
99.83% <= 3 milliseconds
99.88% <= 4 milliseconds
99.89% <= 5 milliseconds
99.96% <= 9 milliseconds
100.00% <= 18 milliseconds
68458.59 requests per second====== LPUSH ======
100004 requests completed in 1.14 seconds
50 parallel clients
3 bytes payload
keep alive: 162.27% <= 0 milliseconds
99.74% <= 1 milliseconds
99.85% <= 2 milliseconds
99.86% <= 3 milliseconds
99.89% <= 5 milliseconds
99.93% <= 7 milliseconds
99.96% <= 9 milliseconds
100.00% <= 22 milliseconds
100.00% <= 208 milliseconds
88109.25 requests per second====== LPOP ======
100001 requests completed in 1.39 seconds
50 parallel clients
3 bytes payload
keep alive: 154.83% <= 0 milliseconds
97.34% <= 1 milliseconds
99.95% <= 2 milliseconds
99.96% <= 3 milliseconds
99.96% <= 4 milliseconds
100.00% <= 9 milliseconds
100.00% <= 208 milliseconds
71994.96 requests per second
注意:修改包的载荷分别为256,1024,4096字节,并没有明显改变结果数字(但应答包被合在一起直到1024字节,因此大数据包时GET会慢些)。客户端数量从50变到256时,结果数字是一样的。只有10个客户端时,则慢一点。
不同的系统上会有不同结果。比如一个低配主机,CPU是主频为1.66GHz 的intel coreT5500,运行着linux 2.6,测试结果如下:
$ ./redis-benchmark -q -n 100000
SET: 53684.38 requests per second
GET: 45497.73 requests per second
INCR: 39370.47 requests per second
LPUSH: 34803.41 requests per second
LPOP: 37367.20 requests per second
另一个CPU为2.5GHz Xeon L5420的64位主机上,结果如下:
$ ./redis-benchmark -q -n 100000
PING: 111731.84 requests per second
SET: 108114.59 requests per second
GET: 98717.67 requests per second
INCR: 95241.91 requests per second
LPUSH: 104712.05 requests per second
LPOP: 93722.59 requests per second
在优化过的高端服务硬件上的测试结果示例
- 版本为redis 2.4.2
- 默认数量的连接数,数据载荷为256字节
- linux主机运行着SLES10 SP3 2.6.16.60-0.54.5-smp,配备2 个主频为93GHz的Intel X5670 CPU
- benchmark客户端和redis运行在同一个CPU上,但在不同的核上进行测试
使用UNIX域套接字:
$ numactl -C 6 ./redis-benchmark -q -n 100000 -s /tmp/redis.sock -d 256
PING (inline): 200803.22 requests per second
PING: 200803.22 requests per second
MSET (10 keys): 78064.01 requests per second
SET: 198412.69 requests per second
GET: 198019.80 requests per second
INCR: 200400.80 requests per second
LPUSH: 200000.00 requests per second
LPOP: 198019.80 requests per second
SADD: 203665.98 requests per second
SPOP: 200803.22 requests per second
LPUSH (again, in order to bench LRANGE): 200000.00 requests per second
LRANGE (first 100 elements): 42123.00 requests per second
LRANGE (first 300 elements): 15015.02 requests per second
LRANGE (first 450 elements): 10159.50 requests per second
LRANGE (first 600 elements): 7548.31 requests per second
使用TCP回路:
$ numactl -C 6 ./redis-benchmark -q -n 100000 -d 256
PING (inline): 145137.88 requests per second
PING: 144717.80 requests per second
MSET (10 keys): 65487.89 requests per second
SET: 142653.36 requests per second
GET: 142450.14 requests per second
INCR: 143061.52 requests per second
LPUSH: 144092.22 requests per second
LPOP: 142247.52 requests per second
SADD: 144717.80 requests per second
SPOP: 143678.17 requests per second
LPUSH (again, in order to bench LRANGE): 143061.52 requests per second
LRANGE (first 100 elements): 29577.05 requests per second
LRANGE (first 300 elements): 10431.88 requests per second
LRANGE (first 450 elements): 7010.66 requests per second
LRANGE (first 600 elements): 5296.61 requests per second
原创文章,转载请注明: 转载自并发编程网 – ifeve.com本文链接地址: 《Redis官方教程》-基准测试



发表后的文章,如何修改?
我发现个错别字。
redis 和 memcached 比较的那三篇引用文章,我都可以打开。
我抽时间翻译一下,回头发上来。
好,修改文章需要我升级下你的权限