剖析Disruptor:为什么会这么快?(一)锁的缺点
原文:http://ifeve.com/disruptor-locks-are-bad/
作者:Trisha’s 译者:张文灼,潘曦 整理和校对:方腾飞,丁一
Martin Fowler写了一篇非常好的文章,里面不仅提到了Disruptor,而且还解释了Disruptor 如何应用在LMAX的架构里。里面有提及了一些目前没有涉及的概念,但最经常问到的问题是 “Disruptor究竟是什么?"。
目前我正准备在回答这个问题,但首先回答"为什么它会这么快?"
这些问题持续出现,但是我不能没有说它是干什么的就说它为什么会这么快,不能没有说它为什么这样做就说它是什么东西。
所以我陷入了一个僵局,一个如何写博客的僵局。
要打破这个僵局,我准备以最简单方式回答第一个问题,如果幸运的话,在以后博文里,如果需要解释的话我会重新提回:Disruptor提供了一种线程之间信息交换的方式。
作为一个开发者,因为"线程"一词的出现,我的警钟已经敲响,它意味着并发,而并发是困难的。
并发 01
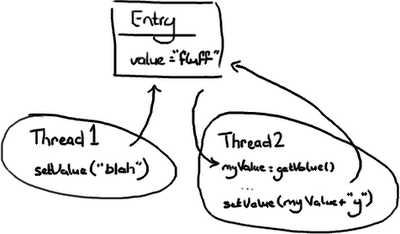
想象有两个线程尝试修改同一个变量value:
情况一:线程1先到达
- 变量value的值变为”blah”。
- 然后当线程2到达时,变量value的值变为”blahy”。
情况二:线程2先到达
- 变量value的值变为”fluffy”。
- 然后当线程1到达时,值变为”blah”。
情况三:线程1与线程2交互
- 线程2得到值"fluff"然后赋给本地变量myValue。
- 线程1改变value的值为”blah”。
- 然后线程2醒来并把变量value的值改为”fluffy”
情况三显然是唯一一个是错误的,除非除非你认为wiki编辑的幼稚做法是正确的(Google Code Wiki,我一直在关注你)。其他两种情况主要是看你的意图和想要达到的效果。线程2可能不会关心变量value的值是什么,主要的意图就是在后面加上字符 ‘y'而不管它原来的值是什么,在这种前提下,情况一和情况二都是正确的。
但是如果线程2只是想把"fluff"改为”fluffy”,那么情况二和三都不正确。假定线程2想把值设为”fluffy”,有几种办法可以解决这个问题:
办法一:悲观锁
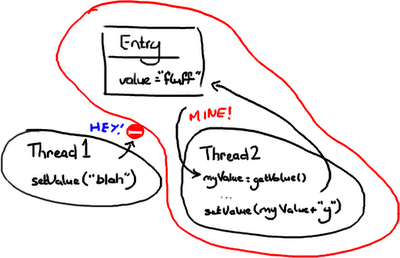
(“No Entry”的标志对于在没有在英国开车的人看得明白不?)
悲观锁和乐观锁这两个词通常在我们谈论数据库读写时经常会用到,但原理可以应用到在获得一个对象的锁的情况。
只要线程2一获得Entry 的互斥锁,它就会阻击其它线程去改变它,然后它就可以随意做它要做的事情,设置值,然后做其它事情。
你可以想象这里非常耗性能的,因为其它线程在系统各处徘徊着准备要获得锁然后又阻塞。线程越多,系统的响应性就会越慢.
办法二:乐观锁
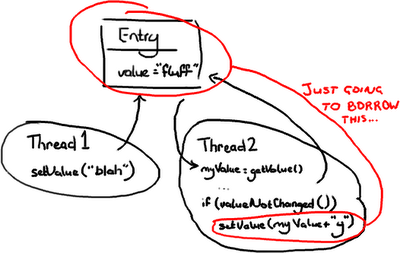
在这种情况,当线程2需要去写Entry时才会去锁定它.它需要检查Entry自从上次读过后是否已经被改过了。如果线程1在线程2读完后到达并把值改为”blah”,线程2读到了这个新值,线程2不会把"fluffy"写到Entry里并把线程1所写的数据覆盖.线程2会重试(重新读新的值,与旧值比较,如果相等则在变量的值后面附上’y’),这里在线程2不会关心新的值是什么的情况.或者线程2会抛出一个异常,或者会返回一个某些字段已更新的标志,这是在期望把”fluff”改为”fluffy”的情况.举一个第二种情况的例子,如果你和另外一个用户同时更新一个Wiki的页面,你会告诉另外一个用户的线程 Thread 2,它们需要重新加载从Thread1来新的变化,然后再提交它们的内容。
潜在的问题:死锁
锁定会带来各种各样的问题,比如死锁,想象有2个线程需要访问两个资源
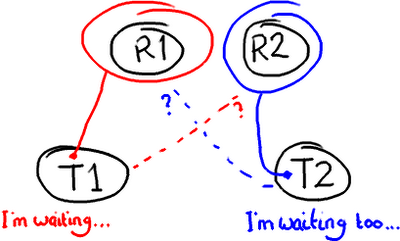
如果你滥用锁技术,两个锁都在获得锁的情况下尝试去获得另外一个锁,那就是你应该重启你的电脑的时候了。(校注:作者还挺幽默)
很明确的一个问题:锁技术是慢的..
关于锁就是它们需要操作系统去做裁定。线程就像两姐妹在为一个玩具在争吵,然后操作系统就是能决定他们谁能拿到玩具的父母,就像当你跑向你父亲告诉他你的姐姐在你玩着的时候抢走了你的变形金刚-他还有比你们争吵更大的事情去担心,他或许在解决你们争吵之前要启动洗碗机并把它摆在洗衣房里。如果你把你的注意力放在锁上,不仅要花时间来让操作系统来裁定。Disruptor论文中讲述了我们所做的一个实验。这个测试程序调用了一个函数,该函数会对一个64位的计数器循环自增5亿次。当单线程无锁时,程序耗时300ms。如果增加一个锁(仍是单线程、没有竞争、仅仅增加锁),程序需要耗时10000ms,慢了两个数量级。更令人吃惊的是,如果增加一个线程(简单从逻辑上想,应该比单线程加锁快一倍),耗时224000ms。使用两个线程对计数器自增5亿次比使用无锁单线程慢1000倍。并发很难而锁的性能糟糕。我仅仅是揭示了问题的表面,而且,这个例子很简单。但重点是,如果代码在多线程环境中执行,作为开发者将会遇到更多的困难:
- 代码没有按设想的顺序执行。上面的场景3表明,如果没有注意到多线程访问和写入相同的数据,事情可能会很糟糕。
- 减慢系统的速度。场景3中,使用锁保护代码可能导致诸如死锁或者效率问题。
这就是为什么许多公司在面试时会多少问些并发问题(当然针对Java面试)。不幸的是,即使未能理解问题的本质或没有问题的解决方案,也很容易学会如何回答这些问题。
Disruptor如何解决这些问题。
首先,Disruptor根本就不用锁。
取而代之的是,在需要确保操作是线程安全的(特别是,在多生产者的环境下,更新下一个可用的序列号)地方,我们使用CAS(Compare And Swap/Set)操作。这是一个CPU级别的指令,在我的意识中,它的工作方式有点像乐观锁——CPU去更新一个值,但如果想改的值不再是原来的值,操作就失败,因为很明显,有其它操作先改变了这个值。
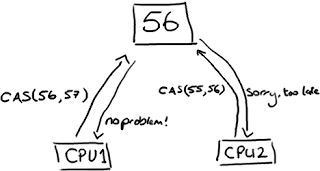
注意,这可以是CPU的两个不同的核心,但不会是两个独立的CPU。
CAS操作比锁消耗资源少的多,因为它们不牵涉操作系统,它们直接在CPU上操作。但它们并非没有代价——在上面的试验中,单线程无锁耗时300ms,单线程有锁耗时10000ms,单线程使用CAS耗时5700ms。所以它比使用锁耗时少,但比不需要考虑竞争的单线程耗时多。
回到Disruptor,在我讲生产者时讲过ClaimStrategy。在这些代码中,你可以看见两个策略,一个是SingleThreadedStrategy(单线程策略)另一个是MultiThreadedStrategy(多线程策略)。你可能会有疑问,为什么在只有单个生产者时不用多线程的那个策略?它是否能够处理这种场景?当然可以。但多线程的那个使用了AtomicLong(Java提供的CAS操作),而单线程的使用long,没有锁也没有CAS。这意味着单线程版本会非常快,因为它只有一个生产者,不会产生序号上的冲突。
我知道,你可能在想:把一个数字转成AtomicLong不可能是Disruptor速度快的唯一秘密。当然,它不是,否则它不可能称为“为什么这么快(第一部分)”。
但这是非常重要的一点——在整个复杂的框架中,只有这一个地方出现多线程竞争修改同一个变量值。这就是秘密。还记得所有的访问对象都拥有序号吗?如果只有一个生产者,那么系统中的每一个序列号只会由一个线程写入。这意味着没有竞争、不需要锁、甚至不需要CAS。在ClaimStrategy中,如果存在多个生产者,唯一会被多线程竞争写入的序号就是 ClaimStrategy 对象里的那个。
这也是为什么Entry中的每一个变量都只能被一个消费者写。它确保了没有写竞争,因此不需要锁或者CAS。
回到为什么队列不能胜任这个工作
因此你可能会有疑问,为什么队列底层用RingBuffer来实现,仍然在性能上无法与 Disruptor 相比。队列和最简单的ring buffer只有两个指针——一个指向队列的头,一个指向队尾:
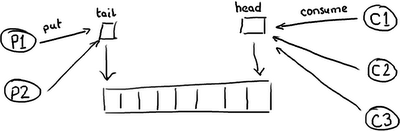
如果有超过一个生产者想要往队列里放东西,尾指针就将成为一个冲突点,因为有多个线程要更新它。如果有多个消费者,那么头指针就会产生竞争,因为元素被消费之后,需要更新指针,所以不仅有读操作还有写操作了。
等等,我听到你喊冤了!因为我们已经知道这些了,所以队列常常是单生产者和单消费者(或者至少在我们的测试里是)。
队列的目的就是为生产者和消费者提供一个地方存放要交互的数据,帮助缓冲它们之间传递的消息。这意味着缓冲常常是满的(生产者比消费者快)或者空的(消费者比生产者快)。生产者和消费者能够步调一致的情况非常少见。
所以,这就是事情的真面目。一个空的队列:
…
一个满的队列:
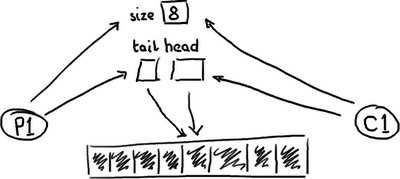
队列需要保存一个关于大小的变量,以便区分队列是空还是满。否则,它需要根据队列中的元素的内容来判断,这样的话,消费一个节点(Entry)后需要做一次写入来清除标记,或者标记节点已经被消费过了。无论采用何种方式实现,在头、尾和大小变量上总是会有很多竞争,或者如果消费操作移除元素时需要使用一个写操作,那元素本身也包含竞争。
基于以上,这三个变量常常在一个cache line里面,有可能导致false sharing。因此,不仅要担心生产者和消费者同时写size变量(或者元素),还要注意由于头指针尾指针在同一位置,当头指针更新时,更新尾指针会导致缓存不命中。这篇文章已经很长了,所以我就不再详述细节了。
这就是我们所说的“分离竞争点问题”或者队列的“合并竞争点问题”。通过将所有的东西都赋予私有的序列号,并且只允许一个消费者写Entry对象中的变量来消除竞争,Disruptor 唯一需要处理访问冲突的地方,是多个生产者写入 Ring Buffer 的场景。
总结
Disruptor相对于传统方式的优点:
- 没有竞争=没有锁=非常快。
- 所有访问者都记录自己的序号的实现方式,允许多个生产者与多个消费者共享相同的数据结构。
- 在每个对象中都能跟踪序列号(ring buffer,claim Strategy,生产者和消费者),加上神奇的cache line padding,就意味着没有为伪共享和非预期的竞争。
校订:需要注意Disruptor2.0使用了与本文中不一样的名字。如果对类名感到困惑,请参考我的变更汇总。
原创文章,转载请注明: 转载自并发编程网 – ifeve.com本文链接地址: 剖析Disruptor:为什么会这么快?(一)锁的缺点

 (16 votes, average: 4.31 out of 5)
(16 votes, average: 4.31 out of 5)

如果没翻译完,最好把没翻译的英文贴在下面,不要让用户去另外的帖子看。这样能保持一定的持续性,用户体验更好。
好建议!马上加上。
第二篇译文也出来了,所以建议在文字末尾加上第二篇文字的链接 http://ifeve.com/disruptor-cacheline-padding/
你可能感兴趣的文章里有第二篇的链接。
You can always tell an expert! Thanks for cotnrbiuitng.
我也总结下:
1.不使用锁,使用CAS。(锁涉及到操作系统,而CAS是CPU级别,更快)
2.RingBuffer的特殊设计,不像传统队列需要head、tail、size,RingBuffer只需要一个序列号来保存下一个可用的空间,减小竞争。
3.Cache Line Padding
总结得很到位,读后总结是好习惯。
你测过Java的synchronized的性能吗?
我测试过。在不发生冲突的前提下,在我i5的电脑上,大概8纳秒。
synchronized内部实现就是一个小小的自旋锁,自旋几十纳秒后如果无法开锁,才会让操作系统挂起线程。
是的,我在另外一篇文章里有详细讲解synchronized=》http://ifeve.com/java-synchronized/
synchronized不发生频繁冲突时,很快。绝大多数情况下要比自己费老大劲用CAS去写lock-free算法还要快。
翻译好烂
哪里翻译有问题?
我又重新校对一遍
没有做浏览器兼容测试么?
ie9, chrome, firefox 里,版面都是乱的。
我这边看都是正常的,刷新下看看
以前的确有问题,已经修复,谢谢。
http://blog.sina.com.cn/s/blog_68ffc7a4010150yl.html
http://blog.sina.com.cn/s/blog_68ffc7a401014d94.html
相似的工作。
多谢推荐
请教一下,结论中的第二点:
2. 让所有的组件都能跟踪自己的序列号,这样可以使多个生产者和多个消费者使用相同的数据结构。
能否详细解释一下,你翻译的没有看明白,原文也没读懂,多谢,这里的“序列号”是指什么?为什么说所有组件都有自己的序列号?
针对你的问题这篇文章的确没有讲清楚,你可以继续阅读后面的文章。
关于RingBuffer的详细介绍可以看=》http://ifeve.com/dissecting-disruptor-whats-so-special/
可以结合源码一起看=》https://github.com/kiral/disruptor/blob/master/src/main/java/com/lmax/disruptor/RingBuffer.java
我大概说一下,RingBuffer这个类由数组结构和序列号等组成,这个序号指向数组中下一个可用的元素。为什么要搞一个序号出来?因为当我们往RingBuffer里添加元素时候,序号可以告诉我们要添加到数组的哪一个位置上。
翻译的不错,夕水溪下总结的也好。支持支持。
“然后当线程1到达时,值变为”blash”。”
“blash”翻译时多了个s,虽然也无关痛痒。。
:) 已修正。
Disruptor相对于传统方式的优点
1:减少竞争点,只有一个地方需要处理竞争。多个生产者写入 Ring Buffer 的时候。这是RingBuffer的独特设计。
2:避免伪共享,使用padding。
3:使用乐观锁,如循环CAS。
从github下了C#版本的Disputor,然后我自己测试了一下。发现用Disputor进行3P1C的测试,发现性能远不如传统的同步模型…大概慢三倍左右。
test result 的output 上面说 WARN: 4 cores required for this test. 是不是没有4个物理核心,Disputor 性能还不如用锁?
Operating System: Microsoft Windows 7 Enterprise
– Version: 6.1.7601
– ServicePack: 1
Number of Processors: 1
– Name: Intel(R) Core(TM) i5-2540M CPU @ 2.60GHz
– Description: Intel64 Family 6 Model 42 Stepping 7
– ClockSpeed: 2601 Mhz
– Number of cores: 2
– Number of logical processors: 4
– Hyperthreading: ON
Memory: 8079 MBytes
L1Cache: 64 KBytes
L2Cache: 256 KBytes
L3Cache: 3072 KBytes
Your computer has 2 physical core(s) but most of the tests require at least 4 cores
Hyperthreading can degrade performance, you should turn it off.
文中:
“情况二:线程2先到达
变量value的值变为”fluffy”。
然后当线程1到达时,值变为”blash”。”
这里应该就是变成”blah”吧?而不是”blash”?
另外有个建议,可以在把翻译的文章放在github上面,这样有问题可以直接发pull request给你们。
是的,已修正。放在github上我们考虑下。
你好,@方腾飞-清英 请教个问题,如下我声明了一个成员变量mainLock: private final ReentrantLock mainLock = new ReentrantLock();然后在某个方法里我将这个成员赋值给了一个局部变量mainLock,final ReentrantLock mainLock = this.mainLock; 然后进行同步,这种再赋值一次有什么意义吗,谢谢。
没有意义,都是指的同一把锁。
“64位的计数器循环自增5亿次” 这个是不是太夸张了,我实验了下 差别不大
http://zh.wikipedia.org/wiki/%E4%B9%90%E8%A7%82%E5%B9%B6%E5%8F%91%E6%8E%A7%E5%88%B6
我没想明白。
“乐观并发控制多数用于数据争用不大、冲突较少的环境中,这种环境中,偶尔回滚事务的成本会低于读取数据时锁定数据的成本,因此可以获得比其他并发控制方法更高的吞吐量。”
为什么这种情况下,乐观所会比悲观锁有更高的吞吐量。比如,如果数据争用不大,那锁定数据的成本不也很低了吗?
我理解的乐观锁和悲观锁性能应该是差不多的,理由如下:
1、竞争大的时候,悲观锁锁定数据的成本要高很多,乐观锁的事务回滚会比较频繁。
2、竞争小的时候,悲观锁锁定数据的成本会很低,乐观锁的成功率也高。
我对锁的认知很低,并不清楚这两种情况下性能的关键点在哪里,是比较锁定数据的成本和回滚事务的成本吗?
有没有事物整合方面的内容,比如正在处理一个queue item的时候机器出了问题如果处理?
这段翻译的不是很好啊,读了好几遍才勉强看懂,以后可不可以提供英文原文链接呢?
“在这种情况,当线程2需要去写Entry时才会去锁定它.它需要检查Entry自从上次读过后是否已经被改过了。如果线程1在线程2读完后到达并把值改为”blah”,线程2读到了这个新值,线程2不会把"fluffy"写到Entry里并把线程1所写的数据覆盖.线程2会重试(重新读新的值,与旧值比较,如果相等则在变量的值后面附上’y’),这里在线程2不会关心新的值是什么的情况.或者线程2会抛出一个异常,或者会返回一个某些字段已更新的标志,这是在期望把”fluff”改为”fluffy”的情况.举一个第二种情况的例子,如果你和另外一个用户同时更新一个Wiki的页面,你会告诉另外一个用户的线程 Thread 2,它们需要重新加载从Thread1来新的变化,然后再提交它们的内容。”
修改了自己的邮箱
文章第一段就有英文链接。
要是能把页面上一篇和下一篇的链接直接放在文章结束的地方就好了,中间隔了那么多评论真不方便
辛苦小编翻译。
针对本文的结论,有个异议,刚才读了ringbuffer,在多个生产者情况下 还是会出现竞争,所以下面的结论是不是在单个生产者前提下?
Disruptor相对于传统方式的优点:
没有竞争=没有锁=非常快。
文中说到,只有cursor一个竞争点,只有多线程生产者的时候会对cursor有写竞争,多消费者不会产生竞争么?如果没有一个统一的标识来只是哪个位置的已经被消费了,那相同的元素岂不是会被重复消费?
都说单线程自增,与synchronized加锁自增有2个量级的差距,不知道作者是在哪个jdk版本中做的测试,在jdk1.8中,其实加锁与不加锁的差距几乎没有,而且现在的synchronized经过了多次的优化,性能已经大有提高了。
牛人呀
这三个变量常常在一个cache line里面,有可能导致false sharing。看来只写代码,不懂硬件(cpu,内存,cache),不能达到代码的极致啊。