伪共享(False Sharing)
原文地址:http://ifeve.com/false-sharing/
作者:Martin Thompson 译者:丁一
缓存系统中是以缓存行(cache line)为单位存储的。缓存行是2的整数幂个连续字节,一般为32-256个字节。最常见的缓存行大小是64个字节。当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。缓存行上的写竞争是运行在SMP系统中并行线程实现可伸缩性最重要的限制因素。有人将伪共享描述成无声的性能杀手,因为从代码中很难看清楚是否会出现伪共享。
为了让可伸缩性与线程数呈线性关系,就必须确保不会有两个线程往同一个变量或缓存行中写。两个线程写同一个变量可以在代码中发现。为了确定互相独立的变量是否共享了同一个缓存行,就需要了解内存布局,或找个工具告诉我们。Intel VTune就是这样一个分析工具。本文中我将解释Java对象的内存布局以及我们该如何填充缓存行以避免伪共享。
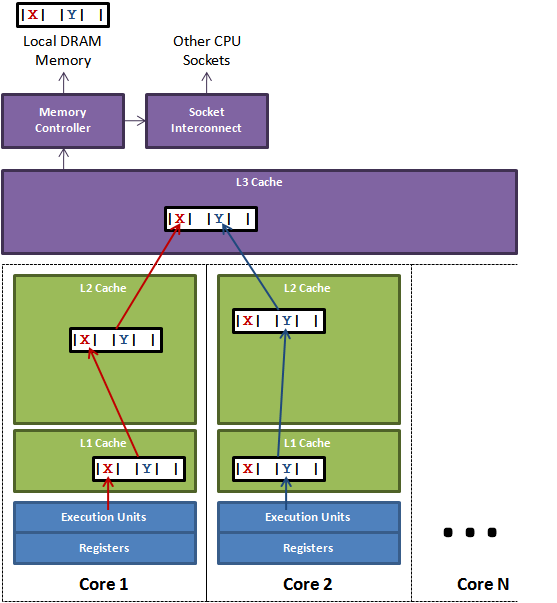 |
| 图 1. |
图1说明了伪共享的问题。在核心1上运行的线程想更新变量X,同时核心2上的线程想要更新变量Y。不幸的是,这两个变量在同一个缓存行中。每个线程都要去竞争缓存行的所有权来更新变量。如果核心1获得了所有权,缓存子系统将会使核心2中对应的缓存行失效。当核心2获得了所有权然后执行更新操作,核心1就要使自己对应的缓存行失效。这会来来回回的经过L3缓存,大大影响了性能。如果互相竞争的核心位于不同的插槽,就要额外横跨插槽连接,问题可能更加严重。
对于HotSpot JVM,所有对象都有两个字长的对象头。第一个字是由24位哈希码和8位标志位(如锁的状态或作为锁对象)组成的Mark Word。第二个字是对象所属类的引用。如果是数组对象还需要一个额外的字来存储数组的长度。每个对象的起始地址都对齐于8字节以提高性能。因此当封装对象的时候为了高效率,对象字段声明的顺序会被重排序成下列基于字节大小的顺序:
- doubles (8) 和 longs (8)
- ints (4) 和 floats (4)
- shorts (2) 和 chars (2)
- booleans (1) 和 bytes (1)
- references (4/8)
- <子类字段重复上述顺序>
(译注:更多HotSpot虚拟机对象结构相关内容:http://www.infoq.com/cn/articles/jvm-hotspot)
了解这些之后就可以在任意字段间用7个long来填充缓存行。在Disruptor里我们对RingBuffer的cursor和BatchEventProcessor的序列进行了缓存行填充。
为了展示其性能影响,我们启动几个线程,每个都更新它自己独立的计数器。计数器是volatile long类型的,所以其它线程能看到它们的进展。
[code lang=”java”]
public final class FalseSharing
implements Runnable
{
public final static int NUM_THREADS = 4; // change
public final static long ITERATIONS = 500L * 1000L * 1000L;
private final int arrayIndex;
private static VolatileLong[] longs = new VolatileLong[NUM_THREADS];
static
{
for (int i = 0; i < longs.length; i++)
{
longs[i] = new VolatileLong();
}
}
public FalseSharing(final int arrayIndex)
{
this.arrayIndex = arrayIndex;
}
public static void main(final String[] args) throws Exception
{
final long start = System.nanoTime();
runTest();
System.out.println("duration = " + (System.nanoTime() – start));
}
private static void runTest() throws InterruptedException
{
Thread[] threads = new Thread[NUM_THREADS];
for (int i = 0; i < threads.length; i++)
{
threads[i] = new Thread(new FalseSharing(i));
}
for (Thread t : threads)
{
t.start();
}
for (Thread t : threads)
{
t.join();
}
}
public void run()
{
long i = ITERATIONS + 1;
while (0 != –i)
{
longs[arrayIndex].value = i;
}
}
public final static class VolatileLong
{
public volatile long value = 0L;
public long p1, p2, p3, p4, p5, p6; // comment out
}
}
[/code]
结果(Results)
运行上面的代码,增加线程数以及添加/移除缓存行的填充,下面的图2描述了我得到的结果。这是在我4核Nehalem上测得的运行时间。
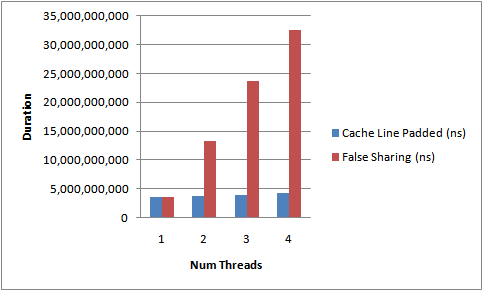 |
| 图 2. |
从不断上升的测试所需时间中能够明显看出伪共享的影响。没有缓存行竞争时,我们几近达到了随着线程数的线性扩展。
这并不是个完美的测试,因为我们不能确定这些VolatileLong会布局在内存的什么位置。它们是独立的对象。但是经验告诉我们同一时间分配的对象趋向集中于一块。
所以你也看到了,伪共享可能是无声的性能杀手。
注意:更多伪共享相关的内容,请阅读我后续blog。
原创文章,转载请注明: 转载自并发编程网 – ifeve.com本文链接地址: 伪共享(False Sharing)

 (18 votes, average: 4.78 out of 5)
(18 votes, average: 4.78 out of 5)

该代码在4×4核Xeon E7520 1.87G上测试,16线程加padding和不加padding性能差别是2.9倍左右,远没有图示数据那么夸张;另外用C/C++写的测试代码也是类似结果(差距更小一些),详见 http://www.felix021.com/blog/read.php?2106 。我怀疑是共享的L2/L3 Cache导致Cache Line失效的开销显著降低了。
volatile修饰?
public final static class VolatileLong
{
public volatile long value = 0L;
public long p1, p2, p3, p4, p5, p6; // comment out
}
经过测试,如果填充只填充4个(p1-p4)的时候,性能比填充6个(p1-p6)还快。这个是不是由于cache lines不是独占(可能还有其他任务在使用)的?所以导致可能填充4个就满了? 当然这种情况是随机和存在不确定性的。
还有,文章前面说的是用7个填充,代码里面又是只有6个 这算是失误么?
这是数组,还有第三个对象头,所以是p6
你说的不对,p6的原因是,对象本身的对象头要占4个字节,但是对象本身大小也是要8字节的整数倍,所以还会padding4个字节,总共是64字节
你好,为何不采用
long p1, p2, p3, p4, p5, p6, p7; // cache line padding
long value;
long p8, p9, p10, p11, p12, p13, p14; // cache line padding
14×8=112字节的padding,只有这样才可以保证value绝对独占缓存行(即value那缓存行除了他都是废物)
我想的跟你一样
我试了你的方法,快了一倍
他的代码给你的少2秒,这是为啥呢,我想他把内部类放在文件最后,变量也定义在最后就是怕后面加上字段吧,但后面加上字段也没事啊,这已经是一个缓存行了。
我用自己的机器测试了一下。
public volatile long value = 0L;
public long p1, p2, p3, p4, p5, p6; // comment out
填充6个long,测试结果大概4s
public volatile long value = 0L;
public long p1, p2, p3, p4, p5, p6, p7; // comment out
填充7个long,耗时反而增加到14s。
何解?
https://mp.weixin.qq.com/s?__biz=Mzg4ODMwNzY0MA==&mid=2247483940&idx=1&sn=15d00692a68c08c2b751d4c6aa076c4a&chksm=cffc68f3f88be1e5edce65bbf580acbf0329f0314223993d1c6cd84eaaf9ae2a67db9f4e0d25&token=1471045935&lang=zh_CN#rd 可以查看我的这篇文章,有讲到
我在自己机器上测试了下本文的填是6个long型 并不能达到预期效果
改为5个之后可达到预期效果
查了下资料 发现对象头好像是再32位机器和64位机器不一样
object header长度
object header 两部分组成
第一部分在64位机器占8个字节,在32位机器上占4个字节
第二部分是一个对象引用。
对象引用在32位机器上占4个字节,在64位机器上有两种情况,开启指针压缩时4个字节;未开启指针压缩是8个字节。
如果是64位机器 对象头本身占用16个字节 另外value 8个字节 额外再填充5个long可以达到缓存行的64字节
不知道这是不是这个原因引起
希望有大大可以解答下疑问。
我也测试了下,6个缓存行填充,是15.0秒,5个缓存行填充3.9秒,
原因是
5个缓存行+1个value共有48个字节,并且我的机器是64位,开启了压缩,所以对象头是12个字节,总共就是60字节,因为java必须是8的整数,所以是有4个字节的填充,总共就是64字节,我通过软件查看到我的缓存行大小是64字节,刚刚好
请教下:我在4核jre1.6环境测试了你的代码,结果如下:
1. volatile/padding: 31S
2. volatile/no-padding:67S
3. no-volatile/padding: 1S
4. no-volatile/no-padding: 1S
如果value变量不用volatile修饰,那么padding或者不padding 没有什么区别。
如果value变量用volatile修饰,那么padding 比 不padding 快了1倍。(但是volatile修饰完时间性能竟下降了30倍。)
我的理解:
1. volatile修饰的变量,每次读写,都会直接访问主内存(L3 cache)。每次访问主内存的时候,由于是volatile long,所以都需要对主内存进行加锁。假设主内存加锁也是加在一个cache line上,那么有可能出现padding的性能2倍好的现象(可能cache line 不是64bytes而是128bytes,2个VolatileLong占用一个cache line,所以并发其实只有2倍)。
2. 如果不用volatile修饰,那么读写value都是在L1 cache上发生(所以要比volatile修饰的要快很多)。但这个时候有无padding性能上没有差距,我不知道怎么解释。就像cache line不用竞争也不会失效。
补充下:
我测试了
long p1, p2, p3, p4, p5, p6, p7; // cache line padding
volatile long value;
long p8, p9, p10, p11, p12, p13, p14; // cache line padding
以验证1中cache line是128 bytes的猜测,在volatile修饰的情况下是5s。看起来猜测对了,相对于没有padding,性能高了6倍。可以认为4个线程都不需要等待。
请多多指教,谢谢。
在不用volatile修饰时程序运行速度确实会提升很多,但这样做在多线程访问同一数据中有可能造成线程读取的值和实际值不一样
个人赞同你2中的理解
至于1中所说cache line 不是64bytes而是128bytes,这个可以下载鲁大师什么的,查看处理器信息:
一级数据缓存 64 KB, 2-Way, 64 byte lines
二级缓存 2 x 512 KB, 16-Way, 64 byte lines
三级缓存 6 MB, 48-Way, 64 byte lines
可以看到我电脑cpu的cache line确实是64 byte;通常规格应该都是64byte,层主也可以查看一下
至于为什么会出现以上情况:
(个人理解)
一个核心上同时会运行许多线程cache line会自动进行所有线程数据的padding,直到填满当前cache line,然后继续向下一个cache line填充,可能刚好cache line 1填充完毕,然后我们启动了测试程序,这个时候就算直接写
public volatile long value = 0L;
假设没有后续线程进行数据填充,我们的数据就独自占用了一个cache line,这个时候不用padding也是最优
不用volatile修饰有无padding性能上都没有差距可能就是这个原因
无volatile修饰情况下我的测试结果是:
padding时 :max 1.1s
no padding时:max1.8s,min1.3s
而这样写
long p1, p2, p3, p4, p5, p6, p7; // cache line padding
volatile long value;
long p8, p9, p10, p11, p12, p13, p14; // cache line padding
则是无论当前cache line被填充到了什么位置,我们都能保证value这个值都独自占用一个cache line,
而这样写
long p1, p2, p3, p4, p5, p6, p7; // cache line padding
volatile long value;
如果没有其他线程填充数据,value值确实独自占用一个cache line,但是如果碰巧有其他线程填充了数据,则其实还是和其他数据共用了一个cache line
这样想也能解释更上面层主的疑问(经过测试,如果填充只填充4个(p1-p4)的时候,性能比填充6个(p1-p6)还快。这个是不是由于cache lines不是独占(可能还有其他任务在使用)的?所以导致可能填充4个就满了? 当然这种情况是随机和存在不确定性的。)
如果层主有什么新的发现或者见解,以及我的回答有什么错误,烦请指教,共同学习成长,谢谢
测试机 64位 MAC 酷睿
i5处理器 双核
用博主的代码测了一下,发现value前面放置p1-p5的效果比 value后面放置p1-p5的时间快一个数量级。
上面看了很多人说 前面放置p1-p6后面再放置p1-p6很快,其实value后面的p1-p6去掉,一样这么快,改成p1-p5会再快一点。
这里跟我自己的理解有点出入,为什么放value前面和后面会差这么多?
———
这里说一下,博主这里的填充了p1-p6可能是对的,因为博主没有说他的测试机是几位系统,假设是32位。
对象头 mark word 4字节,klass 4字节 + value8字节+p1-p6 = 64字节
如果是64位机,应该填充p1-p5才是最优的。但是不清楚放前面和后面为什么会差这么多,期待博主回复!!!
https://mp.weixin.qq.com/s?__biz=Mzg4ODMwNzY0MA==&mid=2247483940&idx=1&sn=15d00692a68c08c2b751d4c6aa076c4a&chksm=cffc68f3f88be1e5edce65bbf580acbf0329f0314223993d1c6cd84eaaf9ae2a67db9f4e0d25&token=1471045935&lang=zh_CN#rd 我这里有一个测试用例,用的双核64位的机器,测试结果发现跟线程的数量有关系,当线程数量超过核心数,时间会增加。
其实直接
@sun.misc.Contended
public final static class VolatileLong
然后-XX:-RestrictContended
就不用手动填充了
而且更快