深入理解并行编程-锁
原文链接 作者:paul 译者:谢宝友,鲁阳,陈渝
锁
在过去几十年并发研究领域的出版物中,锁总是扮演着坏人的角色,锁背负的指控包括引起死锁、锁封护(luyang注:lock convoying,多个同优先级的线程重复竞争同一把锁,此时大量虽然被唤醒而得不到锁的线程被迫进行调度切换,这种频繁的调度切换相当影响系统性能)、饥饿、不公平、data races以及其他许多并发带来的罪孽。有趣的是,在共享内存并行软件中真正承担重担的是——你猜对了——锁。

图1.1:锁:坏人还是懒汉?
这种截然不同的看法源于下面几个原因:
1. 很多因锁产生的问题大都有实用的解决办法,可以在大多数场合工作良好,比如
a) 使用锁层级避免死锁。
b) 死锁检测工具,比如Linux内核lockdep功能[Cor06]。
c) 对锁友好的数据结构,比如数组、哈希表、基数,第十一章将会讲述这些数据结构。
2. 有些锁的问题只有在竞争程度很高时才会出现,一般只有不良的设计才会让锁竞争如此激烈。
3. 有些锁的问题可以通过其他同步机制配合锁来避免。包括引用计数、统计计数、不阻塞的简单数据结构,还有RCU。
4. 在不久之前,几乎所有的共享内存并行程序都是闭源的,所以多数研究者很难知道业界的实践解决方案。
5. 所有美好的故事都需要一个坏人,锁在研究文献中扮演坏小子的角色已经有着悠久而光荣的历史了。

图1.2:锁:驮马还是英雄?
本章将给读者一个概述的认识,了解如何避免锁所带来的问题。
1.1. 生存(staying alive)
由于锁被控诉造成死锁和饥饿,因此对于共享内存并行程序的开发者来说,最重要的考虑之一是保持程序的运行。下面的章节将涵盖死锁、活锁、饥饿、不公平和低效率。
1.1.1. 死锁
死锁发生在一组线程持有至少一把锁时又等待该组线程中某个成员释放它持有的另一把锁时。
如果缺乏外界干预,死锁会一直持续。除了持有锁的线程释放,没有线程可以获取到该锁,但是持有锁的线程在等待获取该锁的线程释放其他锁之前,又无法释放该锁。
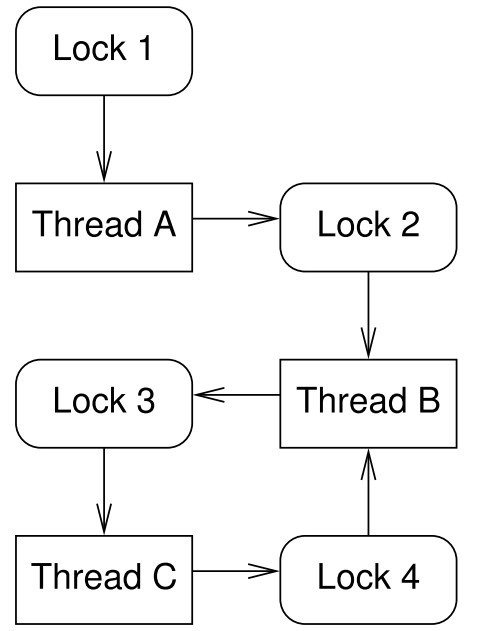
图1.3:死锁循环
我们可以用有向图来表示死锁,节点代表锁和线程,如图1.3所示。从锁指向线程的箭头表示线程持有了该锁,比如,线程B持有锁2和锁4。从线程到锁的箭头表示线程在等待这把锁,比如,线程B等待锁3释放。
死锁场景必然包含至少一个以上的死锁循环。在图1.3中,死锁循环是线程B、锁3、线程C、锁4,然后又回到线程B。
小问题1.1: 但是死锁的定义只说了每个线程持有至少一把锁,然后等待同样的线程释放持有的另一把锁。你怎么知道这里有一个循环?
虽然有一些软件环境,比如数据库系统,可以修复已有的死锁,但是这种方法要么需要杀掉其中一个线程,要么强制从某个线程中偷走一把锁。杀线程和强制偷锁对于事务交易是可以的,但是对内核和应用程序这种层次的锁来说问题多多。
因此,内核和应用程序需要避免死锁。避免死锁主要有三种方法,等级锁,条件锁,一次一把锁的设计。
等级锁为锁编号,禁止乱序获取锁。在图1.3中我们可以用数字为锁编号,这样如果线程已经获取来编号相同或者更高的锁,就不允许再获取这把锁。线程B侵犯了锁的等级,因为它在持有锁4时又试图获取锁3,因此导致死锁的发生。
再一次强调,使用等级锁要为锁编号,禁止乱序获取锁。在大型程序中,最好用工具来检查锁的等级[Cor06]。
[code lang=”c”]
spin_lock(&lock2);
layer_2_processing(pkt);
nextlayer = layer_1(pkt);
spin_lock(&nextlayer->lock1);
layer_1_processing(pkt);
spin_unlock(&lock2);
spin_unlock(&nextlayer->lock1);
[/code]
图1.4:协议分层与死锁
但是假设锁没有合理的等级。这在真实世界完全会发生,比如,在分层的网络协议栈中,报文流是双向的。当报文从一层发送到另一层时,锁完全有可能是被其他层持有的。考虑到报文可以在协议栈中上下传送,图1.4有一个死锁的秘诀。当报文在协议栈中从上往下发送时,必须逆序获取下一层的锁。而报文在协议栈中从下往上发送时,是按顺序获取锁,图1.4中第4行的获取锁操作将导致死锁。
[code lang=”c”]
retry:
spin_lock(&lock2);
layer_2_processing(pkt);
nextlayer = layer_1(pkt);
if (!spin_trylock(&nextlayer->lock1)) {
spin_unlock(&lock2);
spin_lock(&nextlayer->lock1);
spin_lock((&lock2);
if (layer_1(pkt) != nextlayer) {
spin_unlock(&nextlayer->lock1);
spin_unlock((&lock2);
goto retry;
}
}
layer_1_processing(pkt);
spin_unlock(&lock2);
spin_unlock(&nextlayer->lock1);
[/code]
图1.5:通过条件锁来避免死锁
在本例中避免死锁的办法是强加一套锁的等级,但是在有需要时又可以有条件地乱序获取锁,如图1.5所示。与图1.4中无条件的获取层1的锁不同,第5行用spin_trylock()有条件地获取锁。该原语在锁可用时立即获取锁,在锁不可用时不获取锁,返回0。
如果spin_trylock()成功,第15行进行层1的处理工作。否则,第6行释放锁,第7行和第8行用正确的顺序获取锁。不幸的是,系统中可能有多块网络设备(比如Ethernet和WiFi),这样layer_1()函数必须进行路由选择。这种选择随时都可能改变,特别是系统可移动时。所以第9行必须重新检查路由选择,如果发生改变,必须释放锁重新来过。
小问题1.2: 图1.4到1.5的转变能否推广到其他场景?
小问题1.3:为了避免死锁,图1.5带来的复杂性也是值得的吧?
在某些情况下,避免锁嵌套是可以的,这样也就避免了死锁。但是,肯定还有一些手段,可以ensure that the needed data structures remain in existence during the time that neither lock is held。第1.3节讨论了其中一种手段,剩下的在第八章叙述。
1.1.2. 活锁
虽然条件锁是一种有效的避免死锁机制,但是有可能被滥用。看看图1.6中优美的对称例子吧。该例中的美遮掩了一个丑陋的活锁。为了发现它,考虑以下事件顺序:
1. 第4行线程1获取锁1,然后调用do_one_thing()。
2. 第18行线程2获取锁2,然后调用do_a_third_thing()。
3. 线程1试图获取锁2,由于线程2已经持有而失败。
4. 线程2试图获取锁1,由于线程1已经持有而失败。
5. 线程1释放锁1,然后跳转到retry。
6. 线程2释放锁2,然后跳转到retry。
7. 上述过程不断重复,活锁华丽登场。
[code lang=”c”]
void thread1(void)
{
retry:
spin_lock(&lock1);
do_one_thing();
if (!spin_trylock(&lock2)) {
spin_unlock(&lock1);
goto retry;
}
do_another_thing();
spin_unlock(&lock2);
spin_unlock(&lock1);
}
void thread2(void)
{
retry:
spin_lock(&lock2);
do_a_third_thing();
if (!spin_trylock(&lock1)) {
spin_unlock(&lock2);
goto retry;
}
do_a_fourth_thing();
spin_unlock(&lock1);
spin_unlock(&lock2);
}
[/code]
图1.6:滥用条件锁
小问题1.4: 图1.6中的活锁该如何避免?
饥饿与活锁十分类似。换句话说,活锁是饥饿的一种极端形式,所有线程都饥饿了。
1.1.3. 不公平
N/A
1.1.4. 低效率
N/A
11.2. 锁的类型
锁有多少种类型,说出来一定让你大吃一惊,远超过本小节能描述的范围之外。下列章节讨论了互斥锁(第1.2.1节)、读写锁(第1.2.2节)和multi-role锁(第1.2.3节)。
1.2.1. 互斥锁
N/A
1.2.2. 读写锁
N/A
1.2.3. Beyond Reader-Writer Locks
VAXCluster六态锁。
1.3. 基于锁的存在担保(existence guarantee)
并行编程中的一种关键挑战是提供存在担保(existence guarantee)[GKAS99],这样才能正确解决这个问题:尝试删除一个对象的同时又有其他人尝试并发地访问该对象。存在担保对于数据元素被该元素中的锁或者引用计数保护这种情况极其有用。无法提供这种担保的代码容易埋藏隐含的竞态,如图1.7所示。
[code lang=”c”]
int delete(int key)
{
int b;
struct element *p;
b = hashfunction(key);
p = hashtable[b];
if (p == NULL || p->key != key)
return 0;
spin_lock(&p->lock);
hashtable[b] = NULL;
spin_unlock(&p->lock);
kfree(p);
return 1;
}
[/code]
图1.7:没有存在担保的每数据元素锁
小问题1.5: 如果图1.7第8行中我们想删除的元素不是列表中第一个元素怎么办?
小问题1.6: 图1.7会出现什么竞态条件?
[code lang=”c”]
int delete(int key)
{
int b;
struct element *p;
spinlock_t *sp;
b = hashfunction(key);
sp = &locktable[b];
spin_lock(sp);
p = hashtable[b];
if (p == NULL || p->key != key) {
spin_unlock(sp);
return 0;
}
hashtable[b] = NULL;
spin_unlock(sp);
kfree(p);
return 1;
}
[/code]
图1.8:带有基于锁的存在担保的每数据元素锁
解决本例问题的办法是使用一个全局锁的哈希集合,这样每个哈希桶都有自己的锁,如图1.8所示。该方法允许在获取指向数据元素的指针(第10行)之前获取合适的锁(第9行)。虽然该方法在数据包含在单个可分割的数据结构比如图中所示的哈希表时工作的不错,但是如果有某个数据元素可以是多个哈希表的成员,或者更复杂的数据结构比如树和图时,就会有问题了。这些问题还是可以解决的,事实上,这些解决办法组成来基于锁的软件事务性内存实现[ST95][DSS06]。第八章将描述提供存在担保的简单方法。
原创文章,转载请注明: 转载自并发编程网 – ifeve.com本文链接地址: 深入理解并行编程-锁




文中的第十一章是指?
原文图书的第十一章