颠覆大数据分析之实时分析的应用
颠覆大数据分析之实时分析的应用
译者:吴京润 购书
在这一节,我们将看到构建两个应用的步骤:一个工业日志分类系统和一个互联网流量过滤应用。
工业日志分类
随新旧生产工程系统的自动化以及电子工程的发展,大量的机器之间(M2M)的数据正在被生成出来。机器之间的数据可以来自多个不同的源头,包 括无线传感器,电子消费设备,安全应用,还有智能家居设备。举个例子,2004年的地震和随后的海啸造就了由海洋传感器构成的海啸预警系统。自2011年的日本东北地区的地震以来,日本已经沿火车轨道安装了许多传感器,帮助探测不寻常的地震活动以便及时关闭火车运行。GE和其它大电子/电气公司拥有巨量的车间生产日志和其它的M2M数据。Splunk、Sumo Logic、Logscape,还有XpoLog是一些专注于M2M数据分析的公司。
括无线传感器,电子消费设备,安全应用,还有智能家居设备。举个例子,2004年的地震和随后的海啸造就了由海洋传感器构成的海啸预警系统。自2011年的日本东北地区的地震以来,日本已经沿火车轨道安装了许多传感器,帮助探测不寻常的地震活动以便及时关闭火车运行。GE和其它大电子/电气公司拥有巨量的车间生产日志和其它的M2M数据。Splunk、Sumo Logic、Logscape,还有XpoLog是一些专注于M2M数据分析的公司。
这一切是如何组合在一起的:机器对机器的故障分析
这个用例来自电子制造公司。车间里的不同设备,接收输入,执行测试,以非结构化文本形式发送日志,记录测试运行的结果。日志基本上获取了每次测试的参数和它们的值以及输出的结果——这么做的意图就是确认测试是通过还是失败。为便于读者理解要处理和分析什么,下面给出日志文件样本。
识别错误的老办法是把数据传递给一个专家创建的复杂的正则表达式。新方法是用机器学习算法代替正则表达式——由算法学习故障根源的模式。
这个系统的架构见图4.2。为了便于理解,来自机器的输入数据发布到Kafka集群。Kafka是一个高速分布式发布-订阅系统(Kreps等 2011)。Kafka的主要组件是生产者、代理、消费者(译者注:原文分别是:producer broker consumer)。它为一个集群中多代理节点,以及多生产者、消费者节点提供了灵活性。生产者向一个主题发布数据。一个名为代理的Kafka服务器储存着这些消息,允许消费者订阅并异步消费它们。

图4.2 工业日志分类系统架构
Kafka的一个有趣前提是顺序磁盘访问比重复的随机访问内存更快。这样就允许他们把缓存在内存的数据/消息保存到磁盘,从而容忍故障。如果一个代理(broker)从故障中恢复后,消费者能够继续消费保存在磁盘上的消息。即使消费者崩溃了,它也可以发现(译者注:原文是come up)、倒带、重新消费数据。这是通过Kafka所使用的拉取模型得以实现的,消费者从代理拉取数据——它们可以按照自己的节奏进行。这种模型与其它消费系统有所不同,例如那些基于JMS的实现(HornerQ就是这样一个系统)。在我们的系统中,这很有用,因为消费者是一个Storm的Kafka spout。Kafka spout只会以Storm能够处理的速度消费数据(在它上面运行机器学习算法)。Kafka也通过无状态的设计提供容错机制——所有的组件只用Zookeeper集群或磁盘维护状态。这样就允许组件从临时故障中恢复。Kafka还提供数据在集群中的分片选项。
Kafka另一个有趣的地方是它的维护消息顺序的能力——在时间敏感的上下文环境中这一点就变的很重要。这一点保证了Storm不会乱序处理消息——Storm的Kafka spout将会从生产者按顺序接收消息。还可以在生产者和代理之间插入一个负载均衡器,根据负载环境将消息发送给合适的代理。
我们已经为Storm实现了一个Kafka spout,用来消费数据流。这些数据由Storm bolt接收并处理。我们为机器学习算法的训练部分实现了一个分离bolt,以及运行时的分类部分。训练算法是串行的,它的并行化是一个正交问题,现在我们可以忽略它。它必须理解完成了算法学习模式(完成了训练),它就能够用于分类。在线分类算法运行于一个Storm bolt——我们已经配置了Storm为输入流的每个元组使用分离线程。每个元组表示一组从输入流注入的值,这些值将按照“失败的“或”通过的“分类。我们还配置Storm以分布式模式运行并确保能够在集群的任意节点上高度每个线程。
机器学习(译者注:这一节学术性质太强,术语太多,可能翻译的不够好)
当前的机器学习算法实现了最小二乘法(LS)SVM的二类分类——使用了一个整体上可以扩展为多类分类。训练阶段的目的是最小化下述标准:
![]()
数据点的各自类别为n1,n2,总数为n(=n1+n2)。质心向量表示为c1,c2,c;协方差矩阵为Sd*d;正规化参数记为C。闭合形式解如下:
标准向量
![]()
偏差为
![]()
标准矢量和偏差是训练向量——那些训练算法的输出以及捕捉模式的训练数据。它们以下列方式用于在线分类器:
![]() (一类)
(一类)
![]() (其它分类)
(其它分类)
互联网流量过滤器
这个应用与之前的那个非常相似。因此我们只讨论它的显著特征并给出简要说明。架构如图4.3。
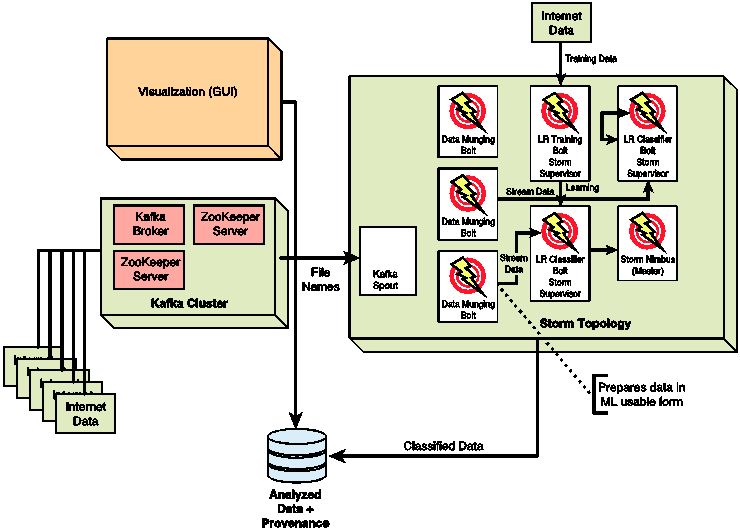
图4.3 互联网流分类系统架构
该架构的突出特性归因于独特的自然语言处理需要。(页面可以是英语或其它语言,比如阿拉伯语或印度语。)因此必须有一个单独的用作数据修改的Storm bolt。一个叫做斯坦福自然语言处理工具的开源项目(NLP),可在这里提供帮助,只需要对输入数据格式做上些调整。数据必须被广泛并行化——在实时的机器学习中,必须在精度和吞吐量之间做出权衡。权衡的产生归因于可能为了提高精度而为算法增加的参数,而更多的参数又增加了算法运行时间。因此,为了达到高精度而又不影响系统吞吐量,数据准备时间就要被大幅缩减——又因此,数据修改bolt就要做出微调。与之相似,即使分类算法(一种SVM)也需要并行化并高效实现。
Storm的替代品
能够运行时实现机器学习算法的分布式流式系统的选择并不多——Hadoop不合格的原因很简单,基于它执行分布于内存中的操作很困难。把一个批处理系统改成一个流式处理系统或者把一个单一系统改成一个流处理和批处理兼务的高效系统是一项艰巨的任务。合理的选择只有Akka、Yahoo的S4(Neumeyer等. 2010)和Storm。这样一个系统的需求如下:
- 长期的输入速率高于输入
- 必须在内存中存储队列化的数据
- 必须允许并行的数据处理
Akka尚处于成为一个企业级选择的起步和造势阶段。有趣的是,它率先提出了基于角色的模型(由Agha 1986)。然而,就现在而言,相比于Akka,Storm似乎更成熟且拥有更多的生产用例。
S4系统类似于Akka,也是基于角色的模型实现,但是更加强大而复杂。S4系统包括处理元素(PE),PE之间可以通过生产或消费事件实现互相通讯,不过不能访问其它PE的状态。一个S4流定义为一个键值对(Storm流是元组)。PE消费流,计算中间值,还可能会分发输出流。处理节点(PN)是PE的逻辑主机。事件由它们的关键属性通过哈希函数路由到PN。与Storm类似,帮助PE发送/接收事件的交互层构建于ZooKeeper之上。S4不能处理因故障丢失的消息,因为实现它的假设之一是:因故障丢失的消息是可容忍的。
来自谷歌的Dremel(Melnik等 2010)或它的开源实现Apache Drill也被称做实时查询系统。读者可能疑惑我们为什么不用它或者不把它与Storm/S4比较一番。需要理解的是,Storm/S4是可能用来实现近实时机器学习算法的流式处理引擎,然而Dremel和Drill是实时查询系统。如果有运行类SQL实时查询功能的系统,Dremel/Drill就相当合适。Drill由MapR支持。Cloudera也有它自己的Dremel实现,叫做Imala。
原创文章,转载请注明: 转载自并发编程网 – ifeve.com本文链接地址: 颠覆大数据分析之实时分析的应用




暂无评论