颠覆大数据分析之Storm的设计模式
颠覆大数据分析之Storm的设计模式
译者:吴京润 购书
我们将要学习如何实现基于Storm的一些通用设计模式。设计模式,我们也称之为软件工程意识,是在给定上下文环境中,针对觉设计问题的可重用的 通常解决方案。(Gamma et al. 1995)。它们是分布式远程过程调用(DRPCs),持续计算,以及机器学习。
通常解决方案。(Gamma et al. 1995)。它们是分布式远程过程调用(DRPCs),持续计算,以及机器学习。
分布式远程过程调用
过程调用为单机运行的程序提供了一个传输控制与数据的灵巧机制。把这一概念扩展到分布式系统中,出现了远程过程调用(RPC)——过程调用的概念可以跨越网络边界。客户机发起一次RPC时发生了下述事件顺序:
- 调用环境要么挂起要么忙等待。
- 参数被编组并通过网络传输到目的机、服务器或被调用者,也就是程序将要执行的地方。
- 参数被整理后,程序在远程节点执行。
- 远程节点的程序执行结束时,结果被传回客户机或源。
- 客户端程序就像刚从一个本地过程调用返回一样继续执行。
实现RPC时要解决的典型问题包括:(1)参数编组与解组,(2)调用语义或在不同地址空间的参数传递语义,(3)在客户端与服务器之间的控制与数据传输协议,还有(4)绑定或如何发现一个服务提供者,以及如何从客户端连接它。
类似Cedar这样的系统这几个问题通过五个组件实现:(1)客户端程序,(2)存根或客户端代理,(3)RPC运行时,后来被称做中间件,(4)服务端存根,还有(5)服务器(以服务的方式提供过程调用)。这一分层模式从用户的通讯细节抽象出来。从之前的第二点也可以看出来,客户端存根实现了参数编组,而RPC运行时负责向服务器传输请求并收集执行后的结果。服务器存根负责服务端的参数解组以及向RPC客户端回传结果。
最早的RPC系统包括施乐的Cebar系统(比勒尔和纳尔逊 1984);同样来自施乐的Courier系统(施乐 1981);以及由Barabara Liskov开发的。SunRPC是广泛应用的开源RPC系统。它可以构建与UDP或TCP协议之上,并提供“至少一次”的语义(程序至少被执行一次)。它还使用SUN的外部数据表示(XDR)作为客户端和服务器之间的数据交换格式。它通过一个被称作port_mapper的程序绑定,通过rpcgen程序生成客户端与服务器存根/代理。
DRPC提供了一个在Storm之上的分布式RPC实现。基本概念是高度运算密集型的程序可以从RPC的分布式实现中获益,因为计算过程分布到整个Storm集群了。集群通过一个DRPC服务器协调DRPC请求。DRPC服务器接收来自客户端的RPC请求,并把它们分到Storm集群,由集群节点并行的执行程序;DRPC服务器接收来自Storm集群的结果,并用它们响应客户端。图4.1是一个简单的示意图。
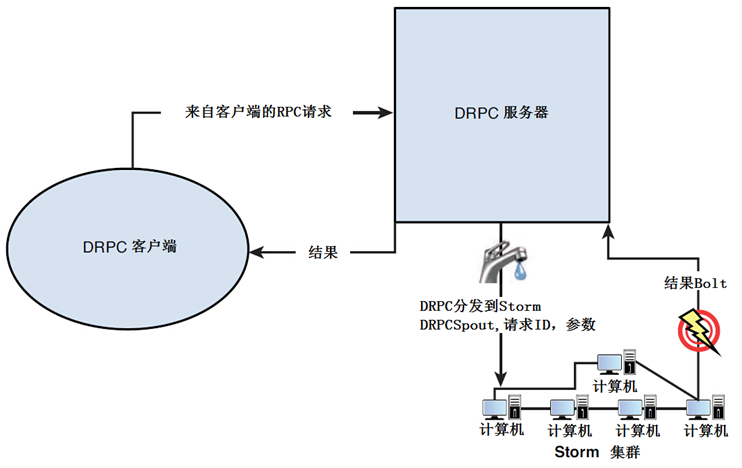
图4.1 DRPC服务器与Storm集群的连接
实现了RPC功能的拓扑使用DRPCSpout从DRPC服务器拉取函数调用数据流。DRPC服务器为每一次函数调用提供惟一性ID。叫做ReturnResults的bolt连接DRPC服务器并为特定的请求ID返回结果。DRPC服务器匹配等待这一结果的客户端请求ID,解除客户端阻塞,回传结果。
Storm提供了一个内建类,LinearDRPCTopologyBuilder,自动化大部分前置任务,包括设置spout,使用ReturnResults bolt返回结果,在元组分组之间为bolts提供有限的聚合功能。下面是使用这个类的代码片段:
[code lang=”java”]
public static class StringReverserBolt extends BaseBasicBolt {
public void execute(Tuple current_tuple, BasicOutputCollector collector){
String incoming_s = current_tuple.getString(1);
collector.emit(new Values(current_tuple.getValue(0),
new StringBuffer(incoming_s))).reverse().toString());
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id","result"));
}
public static void main(String[] args) throws Exception {
LinearDRPCTopologyBuilder drpc_top = new LinearDRPCTopologyBuilder("exclamation");
drpc_top.addBolt(new ExclaimBolt(),3);
//..
}
}
[/code]
Storm允许像启动Nimbus一样启动DRPC服务器:
bin/storm drpc
DRPC服务器的位置通过参数drpc.servers在storm.yaml指定。最终,stringReverser DRPC拓扑可以像任意其它拓扑一样使用下述命令启动:
[code lang=”bash”]
storm jar path/to/allmycode.jar impetus.open.StringReverse stringToBeReversed
[/code]
显然从名字来看,LinearDRPCTopologyBuilder类只有在输入数据是线性步骤/操作序列的情况下工作。对于更复杂的DRPC场景bolt组合,我们可以使用CoordinatedBolt类并实现一个自定义的拓扑构建器。
Trident:基于Storm的实时聚合
在简要解释之前,Trident为Storm生态系统提供严格一致的一性语义,类似于Pig Latin(译者注:一种操作Map-Reduce的语言)。Trident允许诸如聚合、过滤、连接、分组等数据流操作。下面的代码是使用TridentTopology的一个简单的例子:
[code lang=”java”]
TridentTopology topology = new TridentTopology();
TridentState wordCounts = topology.newStream("input1",spout)
.each(new Fields("sentence"), new Split(), new Fields("word"))
.groupBy(new Fields("word"))
.persistentAggregate(MemcachedState.transactional(serverLocations),
new Count(), new Fields("count"));
MemcachedState.transactional();
[/code]
上述代码说明了使用Trident的精髓——第一行创建拓扑的一个新实例。第二行,调用newStream方法从名为“input1”的spout读取数据。这个spout我们假设之前已经定义过了,它可以是一个KafkaSpout或者是之前提到过的Twitter fire hose(译者注:Twitter对自己的API的称呼,这是我根据百度搜索的结果推断出来的)。第三行调用Split(),把构成句子的单词分割出来,单词计数(单词计数是一个聚合功能)保存在一个Memcached域中。
原创文章,转载请注明: 转载自并发编程网 – ifeve.com本文链接地址: 颠覆大数据分析之Storm的设计模式





暂无评论