讨喜的隔离可变性(六)多角色协作
声明:本文是《Java虚拟机并发编程》的第五章,感谢华章出版社授权并发编程网站发布此文,禁止以任何形式转载此文。
在使用基于角色的编程模型时,只有当多个角色互相协作、同心协力解决问题时,我们才能真正从中获益并感受到其中的乐趣。为了更好地利用并发的威力,我们通常需要把问题拆分成若干个子问题。不同的角色可以负责不同的子问题,而我们则需要对角色之间的通信进行协调。下面我们将通过重写计算目录大小的例子来学习如何在进行多角色协作。
在4.2节中,我们写了一个计算给定目录下所有文件大小的程序。在那个例子中,我们启动了100个线程,每个线程都负责扫描不同的子目录,并在最后异步地将所有计算结果累加在一起。而本节中我们将看到一些通过AtomicLong和队列来实现上述功能的方法,同时我们还会把这些方法归纳起来以备你以后处理共享可变性问题之用。
使用带有角色的隔离可变性方法可以使我们在解决并发问题时省去不少麻烦。与本书第4章所介绍的处理共享可变性的方案相比,我们在本节所介绍的方法可以无需为换取线程安全而牺牲性能。此外,正如我们即将看到的那样,作为使用角色编程模型的专属福利,我们可以在角色内部以同步方式写代码,而这也将使得代码更加简洁明了。
首先,我们需要为计算目录大小问题创建一个设计方案——我们可以使用图 8‑3中定义的两类角色。我们将会把可变状态都隔离保存到名为SizeCollector的角色中。该角色通过接收消息来记录需要被扫描的目录、保存目录大小的当前值以及给FileProcessor角色提供需要进行扫描的目录。而主程序代码则负责让所有角色跑起来。此外,我们还将创建100个FileProcessor角色用于遍历给定目录下的文件/目录。
下面我们还是用Akka先在Java中实现这一设计,随后再用Scala进行重写。
在Java中进行多角色协作
下面让我们先定义一下SizeCollector类所要接收的消息:
[code]
class RequestAFile {}
class FileSize {
public final long size;
public FileSize(final long fileSize) { size = fileSize; }
}
class FileToProcess {
public final String fileName;
public FileToProcess(final String name) { fileName = name; }
}
[/code]
上面这两种消息都是由不可变类型定义的。每个FileProcessor都将通过RequestAFile类型的消息来将自己加入到SizeCollector的等待队列当中。FileSize消息内携带有FileProcessor所统计的子目录大小的数据,并由FileProcessor在统计结束之后返回给SizeCollector。最后,FileToProcess消息持有需要进行遍历的子目录名称,该消息是由SizeCollector作为对RequestAFile请求的应答返回给FileProcessor的。
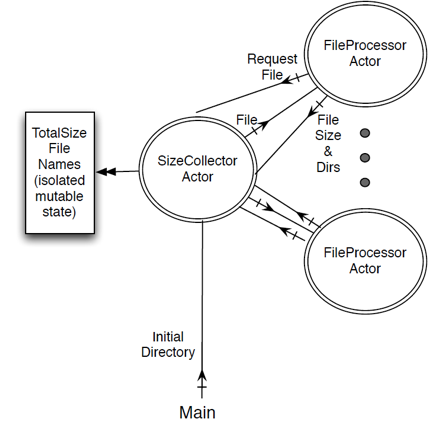 |
|
图 8‑3 使用角色解决计算目录大小问题的设计方案 |
FileProcessor主要负责遍历给定目录并返回该目录下所有文件的大小以及其下所有子目录的名称。在完成当前任务之后,FileProcessor会发送RequestAFile消息给SizeCollector,以便使其知道他们已经做好接下一单目录遍历任务的准备了。此外,这些FileProcessor还需要事先向SizeCollector注册,以便可以收到第一个目录遍历的任务。此外,由于preStart()函数会在每次角色启动之前被调用,所以最适合做这件事的地方莫过于该函数了。下面就让我们一起来实现FileProcessor,请千万别忘了要令其构造函参接受一个指向SizeCollector的引用。
[code 1=”class” 2=”FileProcessor” 3=”extends” 4=”UntypedActor” 5=”{” 6=”private” 7=”final” 8=”ActorRef” 9=”sizeCollector;” 10=”public” 11=”FileProcessor(final” 12=”ActorRef” 13=”theSizeCollector)” 14=”{” sizecollector=”theSizeCollector;” 15=”}” 16=”@Override” 17=”public” 18=”void” 19=”preStart()” 20=”{” 21=”registerToGetFile();” 22=”}” 23=”public” 24=”void” 25=”registerToGetFile()” 26=”{” 27=”sizeCollector.sendOneWay(new” 28=”RequestAFile(),” 29=”getContext());” 30=”}” 31=”public” 32=”void” 33=”onReceive(final” 34=”Object” 35=”message)” 36=”{” 37=”FileToProcess” filetoprocess=”(FileToProcess)” 38=”message;” 39=”final” 40=”File” file=”new” 41=”java.io.File(fileToProcess.fileName);” 42=”long” size=”file.length();” 43=”if(file.isFile())” 44=”{” 45=”}” 46=”else” 47=”{” 48=”File[” language=”java”] children = file.listFiles();
if (children != null)
for(File child : children)
if (child.isFile())
size += child.length();
else
sizeCollector.sendOneWay(new FileToProcess(child.getPath()));
}
sizeCollector.sendOneWay(new FileSize(size));
registerToGetFile();
}
}
[/code]
在registerToGetFile()函数中,FileProcessor会向SizeCollector发送一个RequestAFile消息,同时getContext()函数则会把一个指向自身的引用也一并发送给SizeCollector角色的实例(译注:此处原文有误)。SizeCollector将会把这个引用加入到空闲可用FileProcessor队列中以备需要执行遍历目录任务时使用。
我们稍后将会看到,SizeCollector类将通过发送一个FileToProcess消息来指令FileProcessor去遍历指定目录。而FileProcessor的onReceive()函数将负责响应这个消息。在onReceive()函数中,我们将给定目录下的所有子目录通过sendOneWay()函数发给SizeCollector。而对于给定目录下的文件,我们会将其大小累加起来并在任务结束前将其发送个给SizeCollector。在任务的结尾,我们需要再次将FileProcessor类注册给SizeCollector以便SizeCollector可以继续为其分配目录遍历任务。
至此,FileProcessor已经基本完成了,下面让我们讨论一下SizeCollector相关的问题。SizeCollector是负责管理隔离可变状态的决策者,它可以让FileProcessor们始终保持满负荷工作状态直至得到最终的统计结果为止。在与其他角色的交互方面,它主要负责处理我们之前曾讨论过的那三类消息。下面让我们先看一下SizeCollector的实现代码,然后逐一讨论SizeCollector针对这三种消息的具体行为:
[code lang=”java”]
class SizeCollector extends UntypedActor {
private final List<String> toProcessFileNames = new ArrayList<String>();
private final List<ActorRef> idleFileProcessors =
new ArrayList<ActorRef>();
private long pendingNumberOfFilesToVisit = 0L;
private long totalSize = 0L;
private long start = System.nanoTime();
public void sendAFileToProcess() {
if(!toProcessFileNames.isEmpty() && !idleFileProcessors.isEmpty())
idleFileProcessors.remove(0).sendOneWay(
new FileToProcess(toProcessFileNames.remove(0)));
}
public void onReceive(final Object message) {
if (message instanceof RequestAFile) {
idleFileProcessors.add(getContext().getSender().get());
sendAFileToProcess();
}
if (message instanceof FileToProcess) {
toProcessFileNames.add(((FileToProcess)(message)).fileName);
pendingNumberOfFilesToVisit += 1;
sendAFileToProcess();
}
if (message instanceof FileSize) {
totalSize += ((FileSize)(message)).size;
pendingNumberOfFilesToVisit -= 1;
if(pendingNumberOfFilesToVisit == 0) {
long end = System.nanoTime();
System.out.println("Total size is " + totalSize);
System.out.println("Time taken is " + (end – start)/1.0e9);
Actors.registry().shutdownAll();
}
}
}
}
[/code]
SizeCollector维护了两个链表,其中一个负责保存待访问目录,而另一个负责保存空闲的FileProcessor。除此之外,SizeCollector还定义了3个long型变量用于记录当前还有多少个待访问的目录、当前已统计的文件大小总数以及统计动作开始的时间戳。
sendAFileToProcess()函数主要用于为空闲的FileProcessor们分配待访问目录。
从代码上看,SizeCollector可以在onReceive()消息处理函数中接受三种类型的消息,而每种消息都有其各自的目的。
当FileProcessor干完手头的活之后,它们会立即向SizeCollector发送一个RequestAFile消息,而SizeCollector则将这些空闲角色的引用保存在其空闲FileProcessor列表中。
FileToProcess是SizeCollector既收且发的一类消息。当需要挑选空闲FileProcessor执行统计任务时,SizeCollector就会在sendAFileToProcess()函数中发出一条这类消息给一个空闲的FileProcessor。而当在遍历过程中发现有子目录时,FileProcessor就会用这类消息把所发现的目录告知SizeCollector,以便SizeCollector可以调度其他FileProcessor来执行该目录的遍历。
最后我们要介绍的一类消息是FileSize,该消息是由FileProcessor发出的,并且其中承载了由FileProcessor所统计出来的给定目录下的文件大小。
每当收到一个待访问目录名的时候,SizeCollector都会将名为pendingNumberOfFilesToVisit的隔离可变计数器加1。而每当收到一个带有某目录文件大小的FileSize消息时,SizeCollector就会将该值计数器减1。一旦发现这个计数器的值变为0,则SizeCollector会输出当前统计到的目录大小和所有操作的总耗时,并关闭所有活动的角色,即结束整个程序的运行。
下面让我们实现总体设计的最后一个板块,即主程序代码:
[code lang=”java”]
public class ConcurrentFileSizeWAkka {
public static void main(final String[] args) {
final ActorRef sizeCollector =
Actors.actorOf(SizeCollector.class).start();
sizeCollector.sendOneWay(new FileToProcess(args[0]));
for(int i = 0; i < 100; i++)
Actors.actorOf(new UntypedActorFactory() {
public UntypedActor create() {
return new FileProcessor(sizeCollector);
}
}).start();
}
}
[/code]
在主函数代码中,我们首先创建了一个SizeCollector的实例,并通过一个FileToProcess消息告诉它所要进行统计的是哪个目录。随后我们创建了一个FileProcessor角色,并由SizeCollector负责协调这些FileProcessor共同来完成统计任务。
下面让我们通过上述示例程序来统计一下/usr目录下的文件大小:
[code]
Total size is 3793911517
Time taken is 8.599308
[/code]
通过将使用隔离可变性的本例与4.2节中使用共享可变性完成相同功能的代码进行比较后我们可以发现,所有这些示例所输出的/usr目录下的文件大小都是相同的,并且彼此间之的性能也相差无几。但基于角色的版本与其他实现版本最大的区别是其实现中不含任何同步相关代码、也没有线程栓(latch)、队列以及AtomicLong这些会惹麻烦的东西。而这一区别所造成的结果是:在保证了性能的基础上,我们既能保持代码逻辑简洁,同时又免去了同步和加锁等烦恼。
在Scala中进行多角色协作
在上面的内容里,我们用Akka角色在Java中实现了统计指定目录下文件大小的程序。我们同样也可以在Scala中实现相同的设计,并且还将比Java版本代码写得更简洁。但Scala的实现版本与Java版本有一个显著区别就是,Scala有case类,而该类可以为创建不可变类型提供表达力极强的语法。正是考虑到这种case表达式非常适用于区分消息类型,所以下面我们将会使用case类来实现消息的分类处理:
[code lang=”scala”]
case object RequestAFile
case class FileSize(size : Long)
case class FileToProcess(fileName : String)
[/code]
Scala版的FileProcessor是从Java到Scala的直接翻译,所以这里面没什么超出我们之前讨论范围的新东西:
[code lang=”scala”]
class FileProcessor(val sizeCollector : ActorRef) extends Actor {
override def preStart = registerToGetFile
def registerToGetFile = { sizeCollector ! RequestAFile }
def receive = {
case FileToProcess(fileName) =>
val file = new java.io.File(fileName)
var size = 0L
if(file.isFile()) {
size = file.length()
} else {
val children = file.listFiles()
if (children != null)
188 • Chapter 8. Favoring Isolated Mutability
for(child <- children)
if (child.isFile())
size += child.length()
else
sizeCollector ! FileToProcess(child.getPath())
}
sizeCollector ! FileSize(size)
registerToGetFile
}
}
[/code]
下面让我们将SizeCollector也翻译成Scala版。由于我们采用了case类作为消息类型,所以Scala的模式匹配用在这里简直是天作之合。此外,这种模式也有助于我们更方便地从合适的消息中提取像文件名和文件大小这样数据内容。
[code lang=”scala”]
class SizeCollector extends Actor {
var toProcessFileNames = List.empty[String]
var fileProcessors = List.empty[ActorRef]
var pendingNumberOfFilesToVisit = 0L
var totalSize = 0L
val start = System.nanoTime()
def sendAFileToProcess() : Unit = {
if(!toProcessFileNames.isEmpty && !fileProcessors.isEmpty) {
fileProcessors.head ! FileToProcess(toProcessFileNames.head)
fileProcessors = fileProcessors.tail
toProcessFileNames = toProcessFileNames.tail
}
}
def receive = {
case RequestAFile =>
fileProcessors = self.getSender().get :: fileProcessors
sendAFileToProcess()
case FileToProcess(fileName) =>
toProcessFileNames = fileName :: toProcessFileNames
pendingNumberOfFilesToVisit += 1
sendAFileToProcess()
case FileSize(size) =>
totalSize += size
pendingNumberOfFilesToVisit -= 1
if(pendingNumberOfFilesToVisit == 0) {
val end = System.nanoTime()
println("Total size is " + totalSize)
println("Time taken is " + (end – start)/1.0e9)
Actors.registry.shutdownAll
}
}
}
[/code]
最后,我们还需要将主代码从Java翻译成Scala,而这一次仍然是一个直译的过程。
[code lang=”scala”]
object ConcurrentFileSizeWAkka {
def main(args : Array[String]) : Unit = {
val sizeCollector = Actor.actorOf[SizeCollector].start()
sizeCollector ! FileToProcess(args(0))
for(i <- 1 to 100)
Actor.actorOf(new FileProcessor(sizeCollector)).start()
}
}
[/code]
下面让我们运行Scala版的示例程序统计/usr目录的大小,程序性能和文件大小的统计结果如下所示:
[code]
Total size is 3793911517
Time taken is 8.321386
[/code]
原创文章,转载请注明: 转载自并发编程网 – ifeve.com本文链接地址: 讨喜的隔离可变性(六)多角色协作





暂无评论