一文带你彻底了解Java异步编程
随着RxJava、Reactor等异步框架的流行,异步编程受到了越来越多的关注,尤其是在IO密集型的业务场景中,相比传统的同步开发模式,异步编程的优势越来越明显。
那到底什么是异步编程?异步化真正的好处又是什么?如何选择适合自己团队的异步技术?在实施异步框架落地的过程中有哪些需要注意的地方?
本文从以下几个方面结合真实项目异步改造经验对异步编程进行分析,希望能给大家一些客观认识:
- 使用RxJava异步改造后的效果
- 什么是异步编程?异步实现原理
- 异步技术选型参考
- 异步化真正的好处是什么?
- 异步化落地的难点及解决方案
- 扩展:异步其他解决方案-协程
使用RxJava异步改造后的效果
下图是我们后端java项目使用RxJava改造成异步前后的RT(响应时长)效果对比:
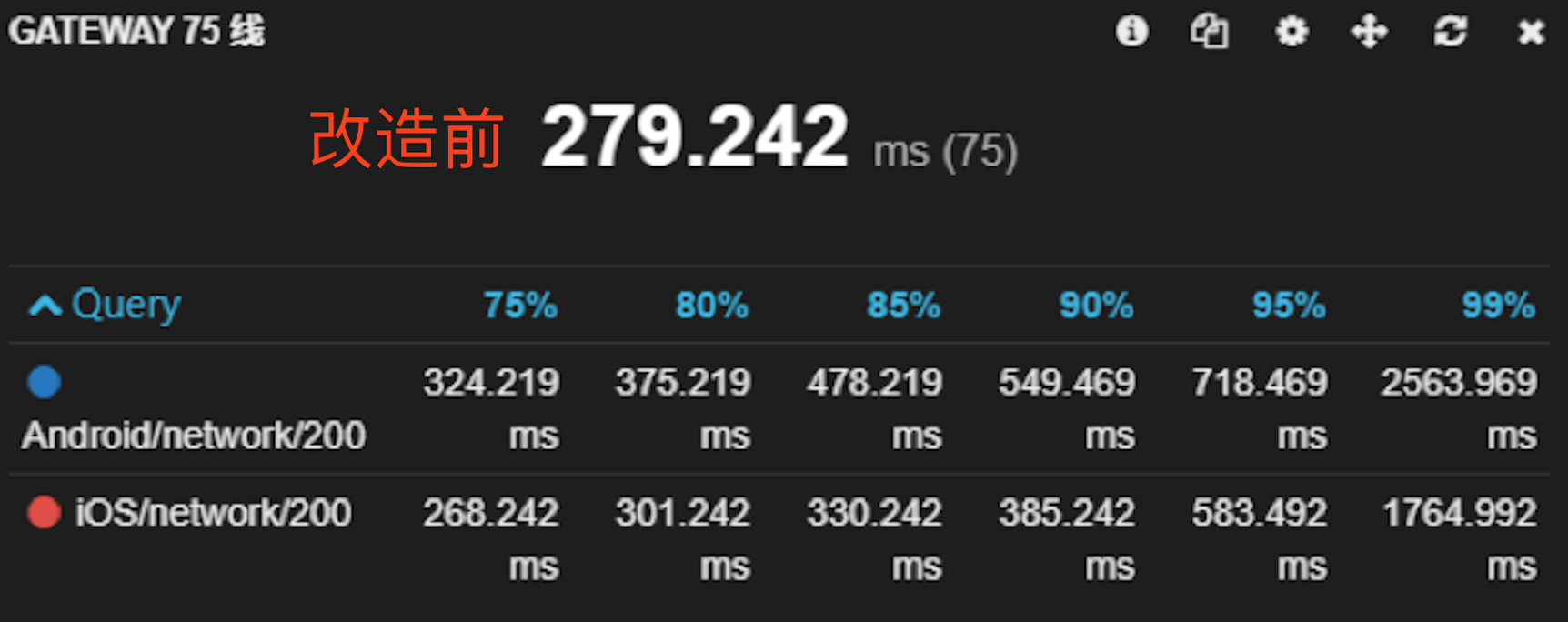
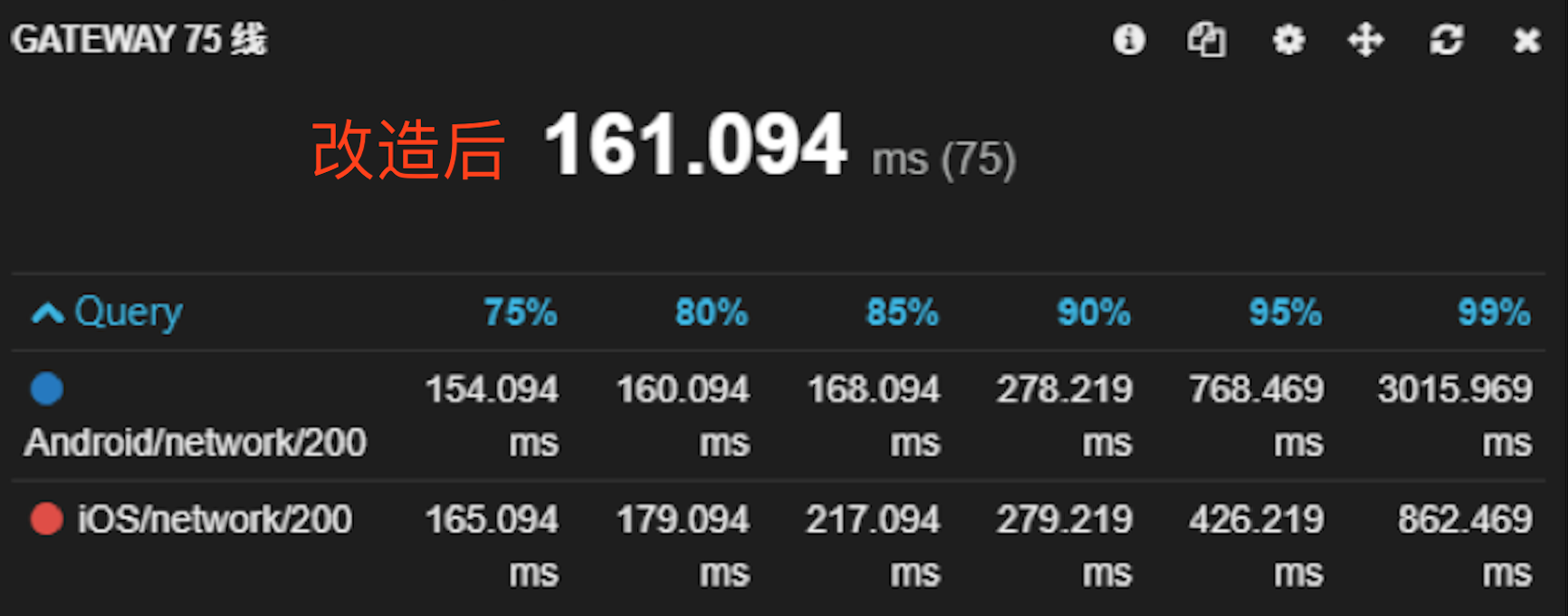
统计数据基于App端的gateway,以75线为准,还有80、85、90、99线,从图中可以看出改成异步后接口整体的平均响应时长降低了40%左右。
(响应时间是以发送请求到收到后端接口响应数据的时长,上图改造的这个后端java接口内部流程比较复杂,因为公司都是微服务架构,该接口内部又调用了6个其他服务的接口,最后把这些接口的数据汇总在一起返回给前端)
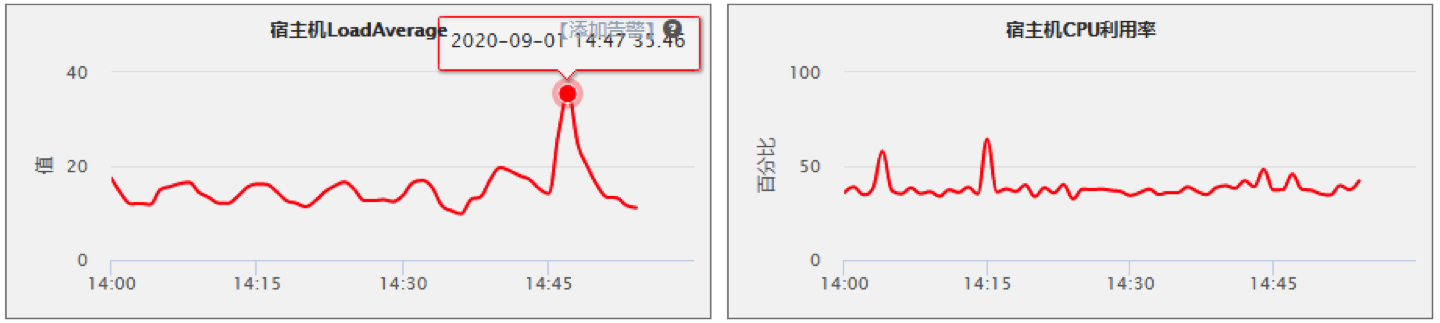
这张图是同步接口和改造成异步接口前后的CPU负载情况对比
改造前cpu load : 35.46
改造后cpu load : 14.25
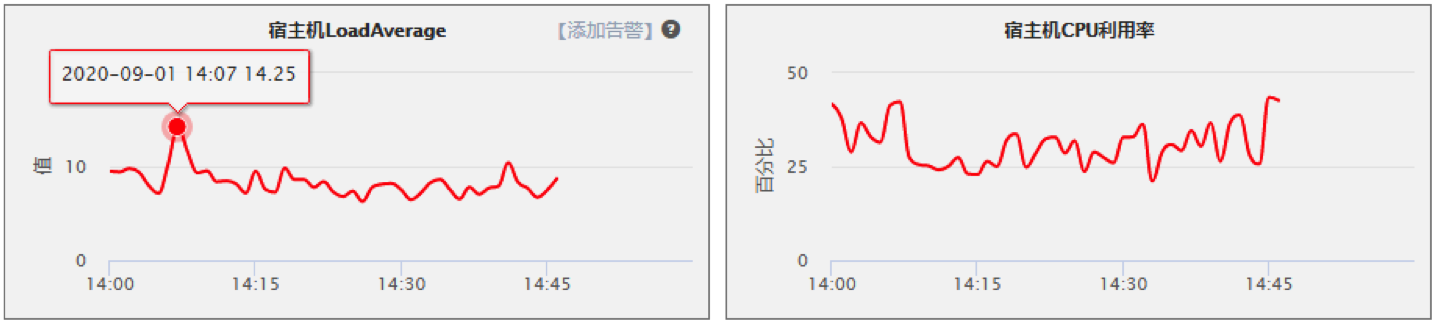
改成异步后CPU的负载情况也有明显下降,但CPU使用率并无影响(一般情况下异步化后cpu的利用率会有所提高,但要看具体的业务场景)
CPU LoadAverage是指:一段时间内处于可运行状态和不可中断状态的进程平均数量。(可运行分为正在运行进程和正在等待CPU的进程;不可中断则是它正在做某些工作不能被中断比如等待磁盘IO、网络IO等)
而我们的服务业务场景大部分都是IO密集型业务,功能实现很多需要依赖底层接口,会进行频繁的IO操作。
下图是2019年在全球架构师峰会上阿里分享的异步化改造后的RT和QPS效果:
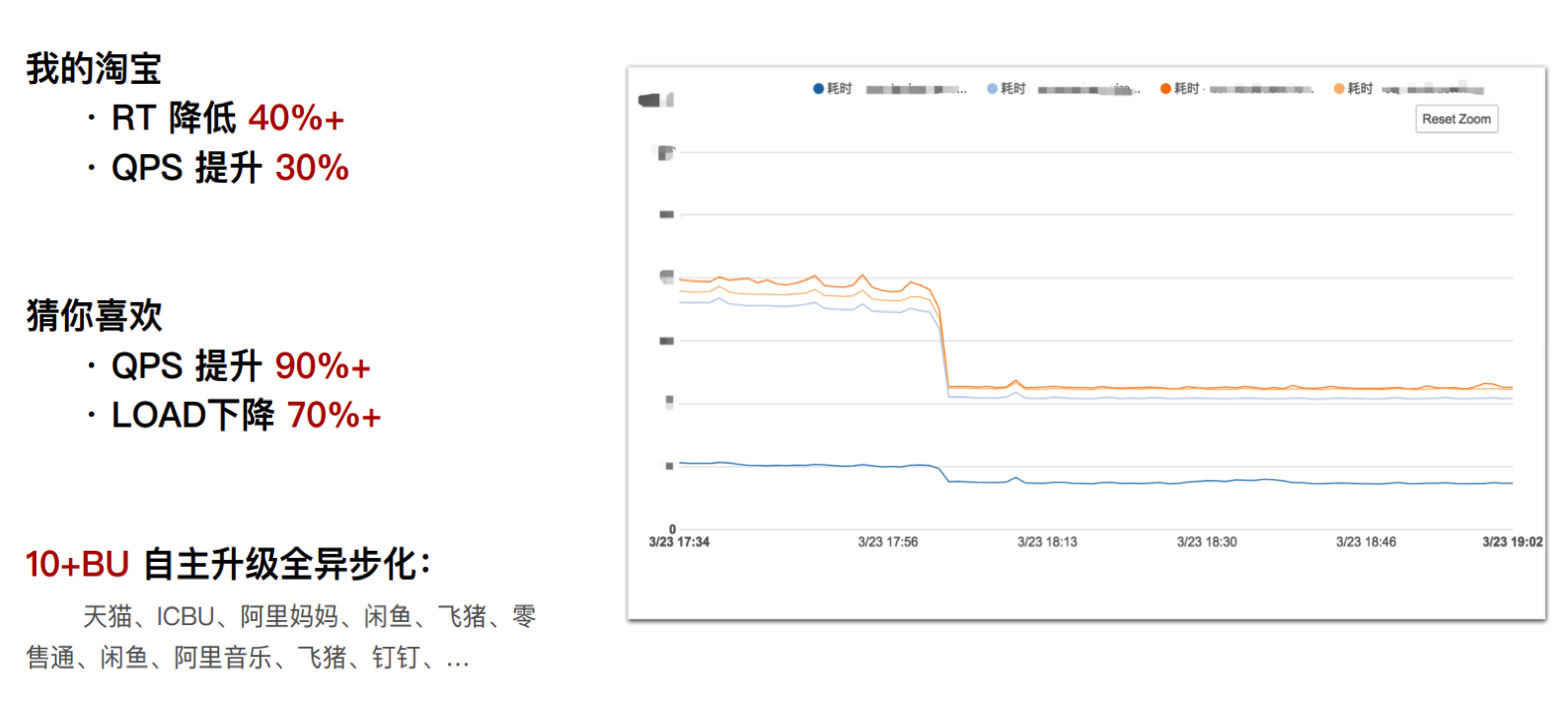
(图片来源:淘宝应用架构升级——反应式架构的探索与实践)
什么是异步编程?
响应式编程 + NIO
1. 异步和同步的区别:
我们先从I/O的角度看下同步模式下接口A调用接口B的交互流程:
下图是传统的同步模式下io线程的交互流程,可以看出io是阻塞的,即bio的运行模式
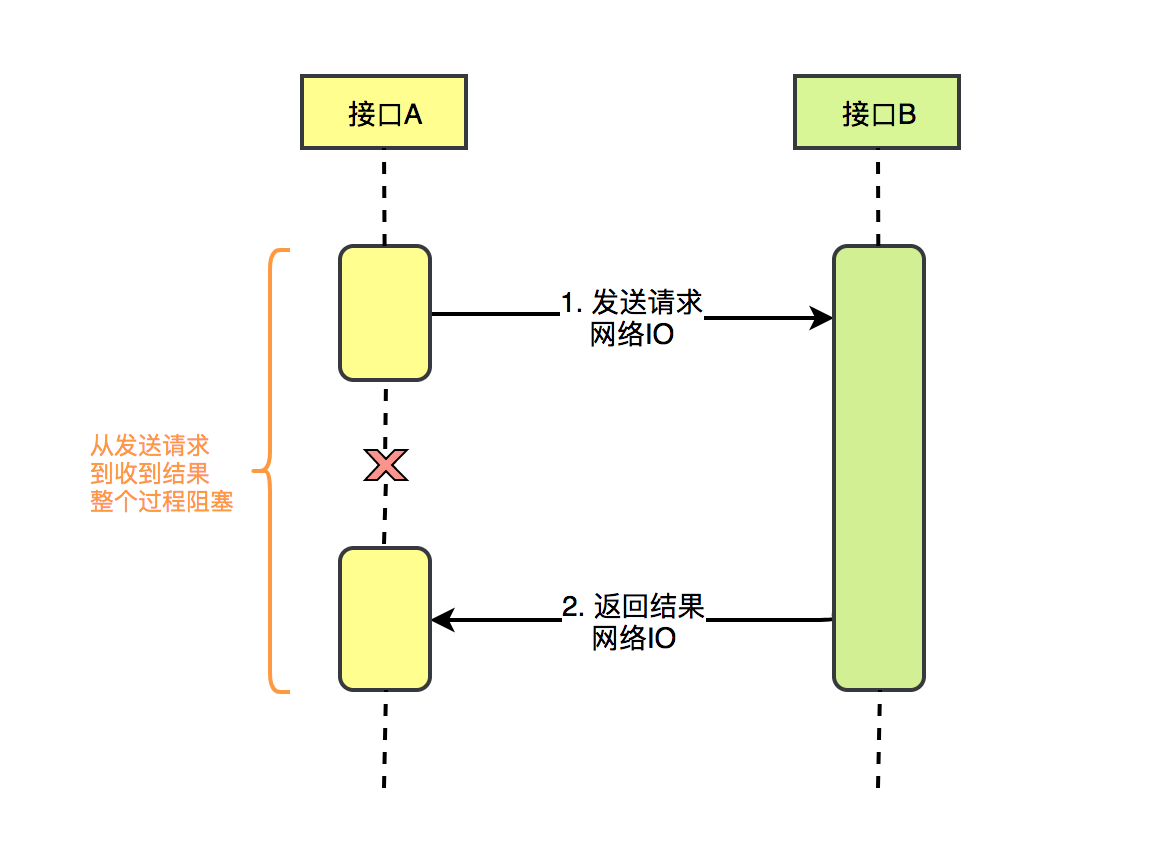
接口A发起调用接口B后,这段时间什么事情也不能做,主线程阻塞一直等到接口B数据返回,然后才能进行其他操作,可想而知如果接口A调用的接口不止B的话(A->B->C->D->E。。。),那么等待的时间也是递增的,而且这期间CPU也要一直占用着,白白浪费资源,也就是上图看到的 cpu load 高的原因。
而且还有一个隐患就是如果调用的其他服务中的接口比如C超时,或接口C挂掉了,那么对调用方服务A来说,剩余的接口比如D、E都会无限等待下去。。。
其实大部分情况下我们收到数据后内部的处理逻辑耗时都很短,这个可以通过埋点执行时间统计,大部分时间都浪费在了IO等待上。
下面这个视频演示了同步模式下我们线上环境真实的接口调用情况,即接口调用的线程执行和变化情况,(使用的工具是JDK自带的jvisual来监控线程变化情况)
这里先交代下大致背景:服务端api接口A内部一共调用了6个其他服务的接口,大致交互是这样的:
A接口(B -> C -> D -> E -> F -> G)返回聚合数据
背景:使用Jemter测试工具压测100个线程并发请求接口,以观察线程的运行情况(可以全屏观看):
http-nio-8080-exec*开头的是tomcat线程池中的线程,即前端请求我们后端接口时要通过tomcat服务器接收和转发的线程,因为我们后端api接口内部又调用了其他服务的6个接口(B、C、D、E、F、G),同步模式下需要等待上一个接口返回数据才能继续调用下一个接口,所以可以从视频中看出,大部分的http线程耗时都在8秒以上(绿色线条代表线程是”运行中”状态,8秒包括等待接口返回的时间和我们内部逻辑处理的总时间,因为是本地环境测试,受机器和网络影响较大)
然后我们再看下异步模式的交互流程,即nio方式:
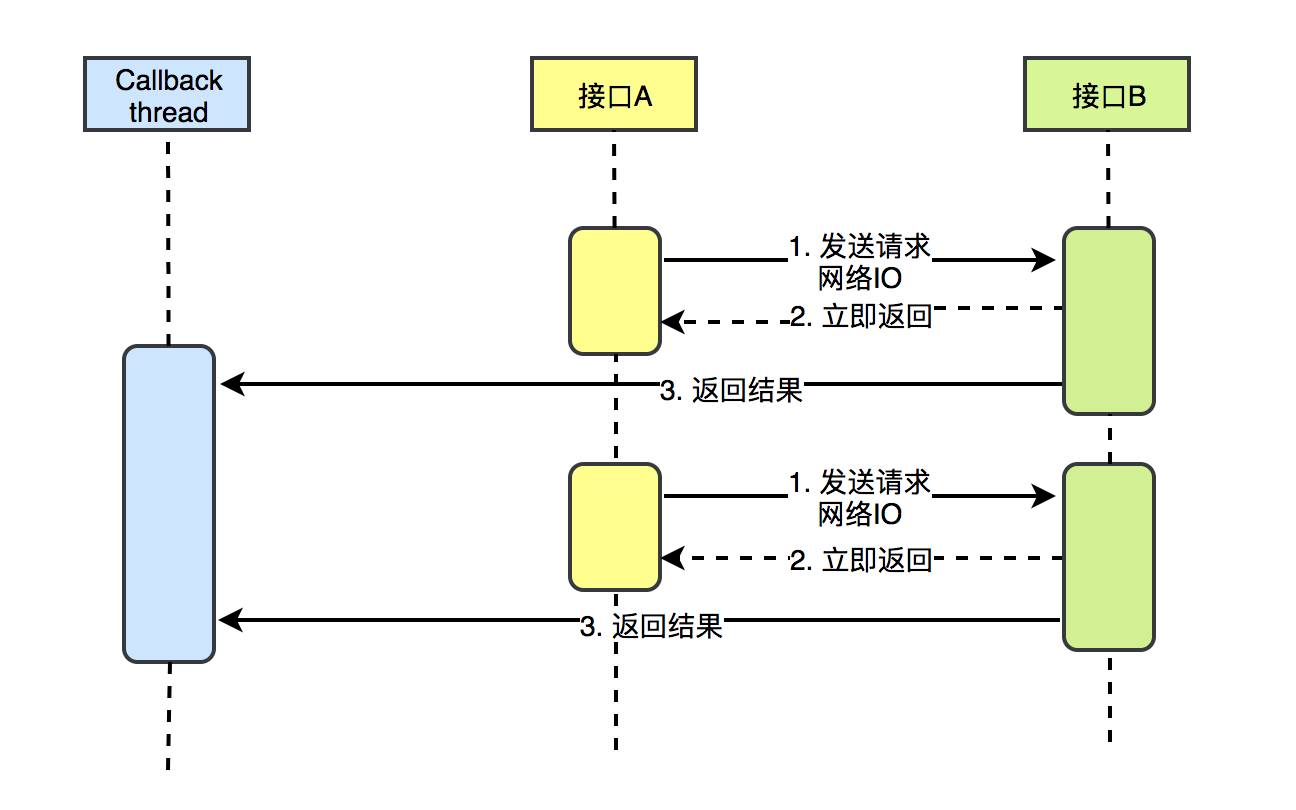
大致流程就是接口A发起调用接口B的请求后就立即返回,而不用阻塞等待接口B响应,这样的好处是http-nio-8080-exec*线程可以马上得到复用,接着处理下一个前端请求的任务,如果接口B处理完返回数据后,会有一个回调线程池处理真正的响应,即这种模式下我们的业务流程是http线程只处理请求,回调线程处理接口响应。
这个视频演示了异步模式下接口A的线程执行情况,同样也是使用Jemter测试工具压测100个线程并发请求接口,以观察线程的运行情况(可以全屏观看):
模拟的条件和同步模式一样,同样是100个线程并发请求接口,但这次http-nio-8080-exec*开头的线程只处理请求任务,而不再等待全部的接口返回,所以http的线程运行时间普遍都很短(大部分在1.8秒左右完成),AsfThread-executor-*是我们系统封装的回调线程池,处理底层接口的真正响应数据。
演示视频中的AsfThread-executor-*的回调线程只创建了30多个,而请求的http线程有100个,也就是说这30多个回调线程处理了接口B的100次响应(其实应该是600次,因为接口B内部又调用了6个其他接口,这6次也都是在异步线程里处理响应的),因为每个接口返回的时间不一样,加上网络传输的时间,所以可以利用这个时间差充分复用线程即cpu资源,视频中回调线程AsfThread-executor-*的绿色运行状态是多段的,表示复用了多次,也就是少量回调线程处理了全部(600次)的响应,这正是IO多路复用的机制。
nio模式下虽然http-nio-8080-exec*线程和回调线程AsfThread-executor-*的运行时间都很短,但是从http线程开始到asf回调处理完返回给前端结果的时间和bio即同步模式下的时间差异不大(在相同的逻辑流程下),并不是nio模式下服务响应的整体时间就会缩短,而是会提升CPU的利用率,因为CPU不再会阻塞等待(不可中断状态减少),这样CPU就能有更多的资源来处理其他的请求任务,相同单位时间内能处理更多的任务,所以nio模式带来的好处是:
- 提升QPS(用更少的线程资源实现更高的并发能力)
- 降低CPU负荷,提高利用率
2. Nio原理
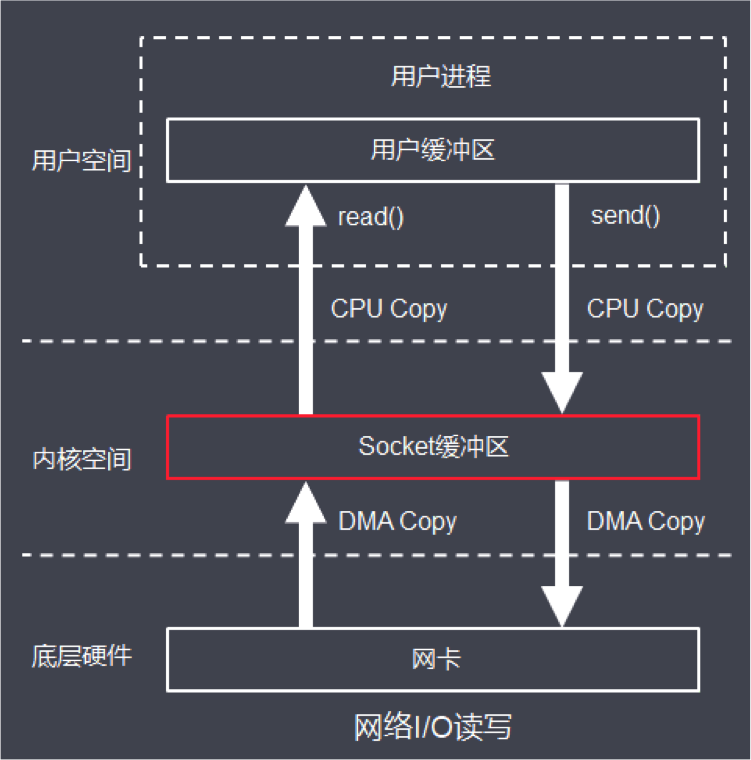
结合上面的接口交互图可知,接口B通过网络返回数据给调用方(接口A)这一过程,对应底层实现就是网卡接收到返回数据后,通过自身的DMA(直接内存访问)将数据拷贝到内核缓冲区,这一步不需要CPU参与操作,也就是把原先CPU等待的事情交给了底层网卡去处理,这样CPU就可以专注于我们的应用程序即接口内部的逻辑运算。
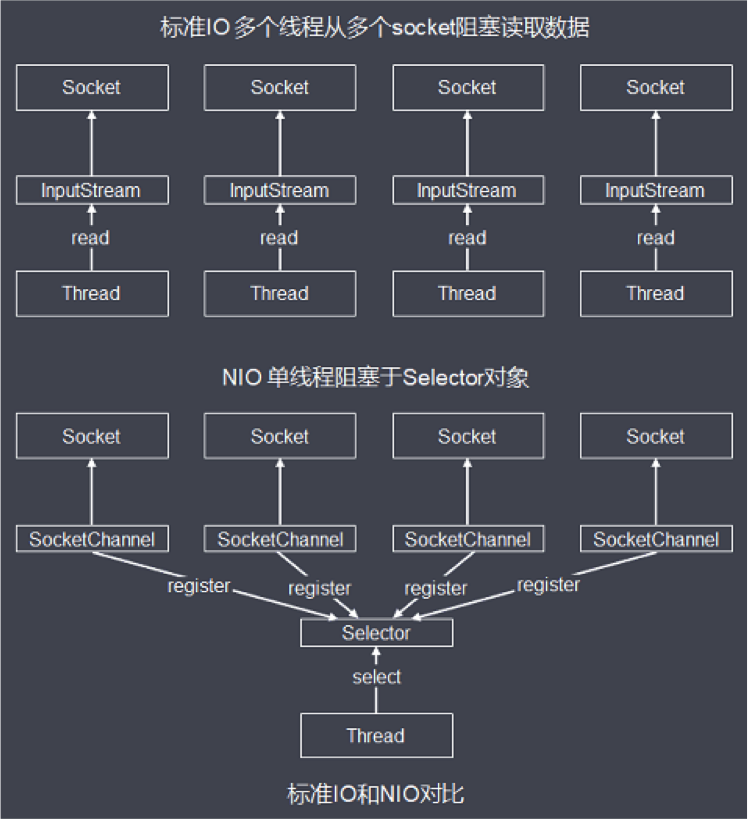
3. Nio In Java

nio在java里的实现主要是上图中的几个核心组件:channel、buffer、selector,这些组件组合起来即实现了上面所讲的多路复用机制,如下图所示:
响应式编程
1. 什么是响应式编程?它和传统的编程方式有什么区别?
响应式可以简单的理解为收到某个事件或通知后采取的一系列动作,如上文中所说的响应操作系统的网络数据通知,然后以回调的方式处理数据。
传统的命令式编程主要由:顺序、分支、循环 等控制流来完成不同的行为
响应式编程的特点是:
- 以逻辑为中心转换为以数据为中心
- 从命令式到声明式的转换
2. Java.Util.Concurrent.Future
在Java使用nio后无法立即拿到真实的数据,而且先得到一个”future“,可以理解为邮戳或快递单,为了获悉真正的数据我们需要不停的通过快递单号查询快递进度,所以 J.U.C 中的 Future 是Java对异步编程的第一个解决方案,通常和线程池结合使用,伪代码形式如下:
ExecutorService executor = Executors.newCachedThreadPool(); // 线程池
Future<String> future = executor.submit(() ->{
Thread.sleep(200); // 模拟接口调用,耗时200ms
return "hello world";
});
// 在输出下面异步结果时主线程可以不阻塞的做其他事情
// TODO 其他业务逻辑
System.out.println("异步结果:"+future.get()); //主线程获取异步结果
Future的缺点很明显:
- 无法方便得知任务何时完成
- 无法方便获得任务结果
- 在主线程获得任务结果会导致主线程阻塞
3. ListenableFuture
Google并发包下的listenableFuture对Java原生的future做了扩展,顾名思义就是使用监听器模式实现的回调机制,所以叫可监听的future。
Futures.addCallback(listenableFuture, new FutureCallback<String>() {
@Override
public void onSuccess(String result) {
System.out.println("异步结果:" + result);
}
@Override
public void onFailure(Throwable t) {
t.printStackTrace();
}
}, executor);
回调机制的最大问题是:Callback Hell(回调地狱)
试想如果调用的接口多了,而且接口之间有依赖的话,最终写出来的代码可能就是下面这个样子:
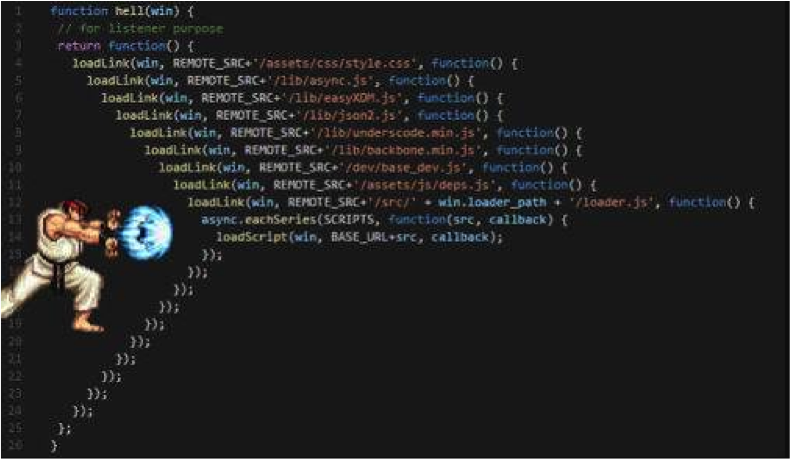
- 代码的字面形式和其所表达的业务含义不匹配
- 业务的先后关系在代码层面变成了包含和被包含的关系
- 大量使用 Callback 机制,使应该是先后的业务逻辑在代码形式上表现为层层嵌套,这会导致代码难以理解和维护。
那么如何解决 Callback Hell 问题呢?
响应式编程
其实主要是以下两种解决方式:
- 事件驱动机制
- 链式调用(Lambda)
4. CompletableFuture
Java8里的CompletableFuture和Java9的Flow Api勉强算是上面问题的解决方案:
CompletableFuture<String> f1 = CompletableFuture.supplyAsync(() ->
"hello"
);
// f2依赖f1的结果做转换
CompletableFuture<String> f2 = f1.thenApplyAsync(t ->
t + " world"
);
System.out.println("异步结果:" + f2.get());
但CompletableFuture处理简单的任务可以使用,但并不是一个完整的反应式编程解决方案,在服务调用复杂的情况下,存在服务编排、上下文传递、柔性限流(背压)方面的不足
如果使用CompletableFuture面对这些问题可能需要自己额外造一些轮子,Java9的Flow虽然是基于 Reactive Streams 规范实现的,但没有RxJava、Project Reactor这些异步框架丰富和强大和完整的解决方案。
当然如果接口逻辑比较简单,完全可以使用listenableFuture或CompletableFuture,关于他们的详细用法可参考之前的一篇文章:Java异步编程指南
5. Reactive Streams
在网飞推出RxJava1.0并在Android端普及流行开后,响应式编程的规范也呼之欲出:
包括后来的RxJava2.0、Project Reactor都是基于Reactive Streams规范实现的。
关于他们和listenableFuture、 CompletableFuture的区别通过下面的例子大家应该就会清楚。
比如下面的基于回调的代码示例:获取用户的5个收藏列表功能
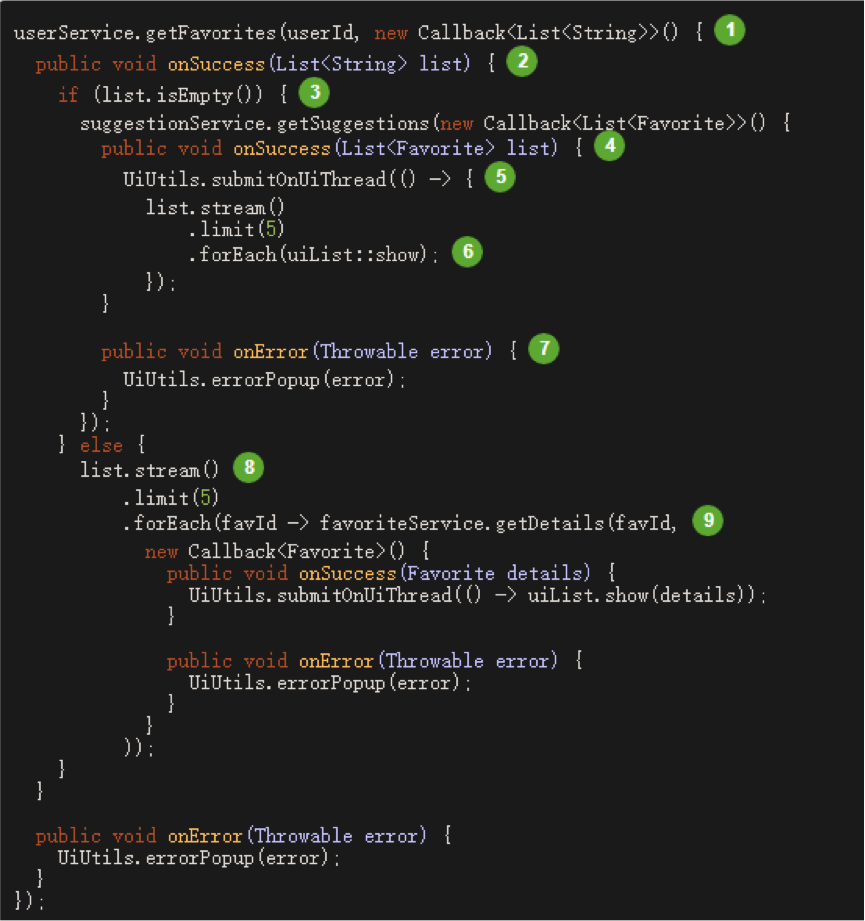
图中标注序号的步骤对应如下:
- 根据uid调用用户收藏列表接口
userService.getFavorites - 成功的回调逻辑
- 如果用户收藏列表为空
- 调用推荐服务
suggestionService.getSuggestions - 推荐服务成功后的回调逻辑
- 取前5条推荐并展示(
Java8 Stream api) - 推荐服务失败的回调,展示错误信息
- 如果用户收藏列表有数据返回
- 取前5条循环调用详情接口
favoriteService.getDetails成功回调则展示详情,失败回调则展示错误信息
可以看出主要逻辑都是在回调函数(onSuccess()、onError())中处理的,在可读性和后期维护成本上比较大。
基于Reactive Streams规范实现的响应式编程解决方案如下:
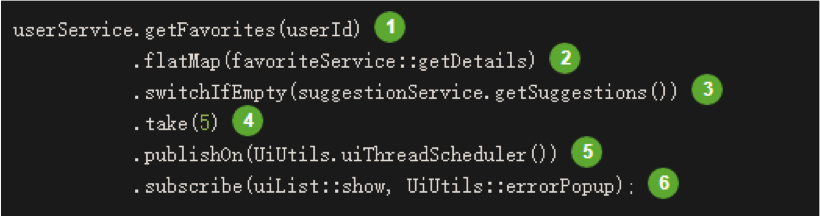
- 调用用户收藏列表接口
- 压平数据流调用详情接口
- 如果收藏列表为空调用推荐接口
- 取前5条
- 切换成异步线程处理上述声明接口返回结果)
- 成功则展示正常数据,错误展示错误信息
可以看出因为这些异步框架提供了丰富的api,所以我们可以把主要精力放在数据的流转上,而不是原来的逻辑控制上。这也是异步编程带来的思想上的转变。
下图是RxJava的operator api:
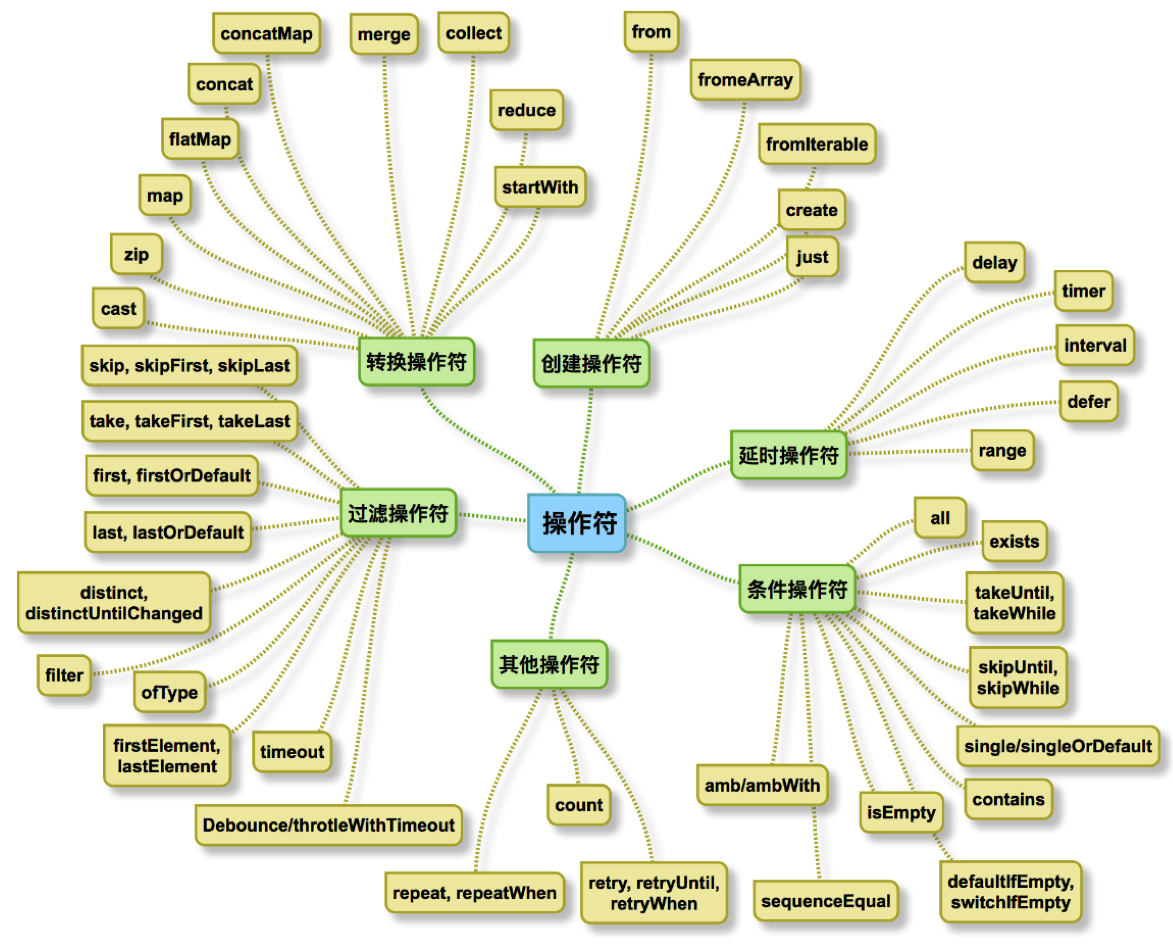
(如果这些操作符满足不了你的需求,你也可以自定义操作符)
所以说异步最吸引人的地方在于资源的充分利用,不把资源浪费在等待的时间上(nio),代价是增加了程序的复杂度,而Reactive Program封装了这些复杂性,使其变得简单。
所以我们无论使用哪种异步框架,尽量使用框架提供的api,而不是像上图那种基于回调业务的代码,把业务逻辑都写在onSuccess、onError等回调方法里,这样无法发挥异步框架的真正作用:
Codes Like Sync,Works Like Async
即以同步的方式编码,达到异步的效果与性能,兼顾可维护性与可伸缩性。
异步框架技术选型
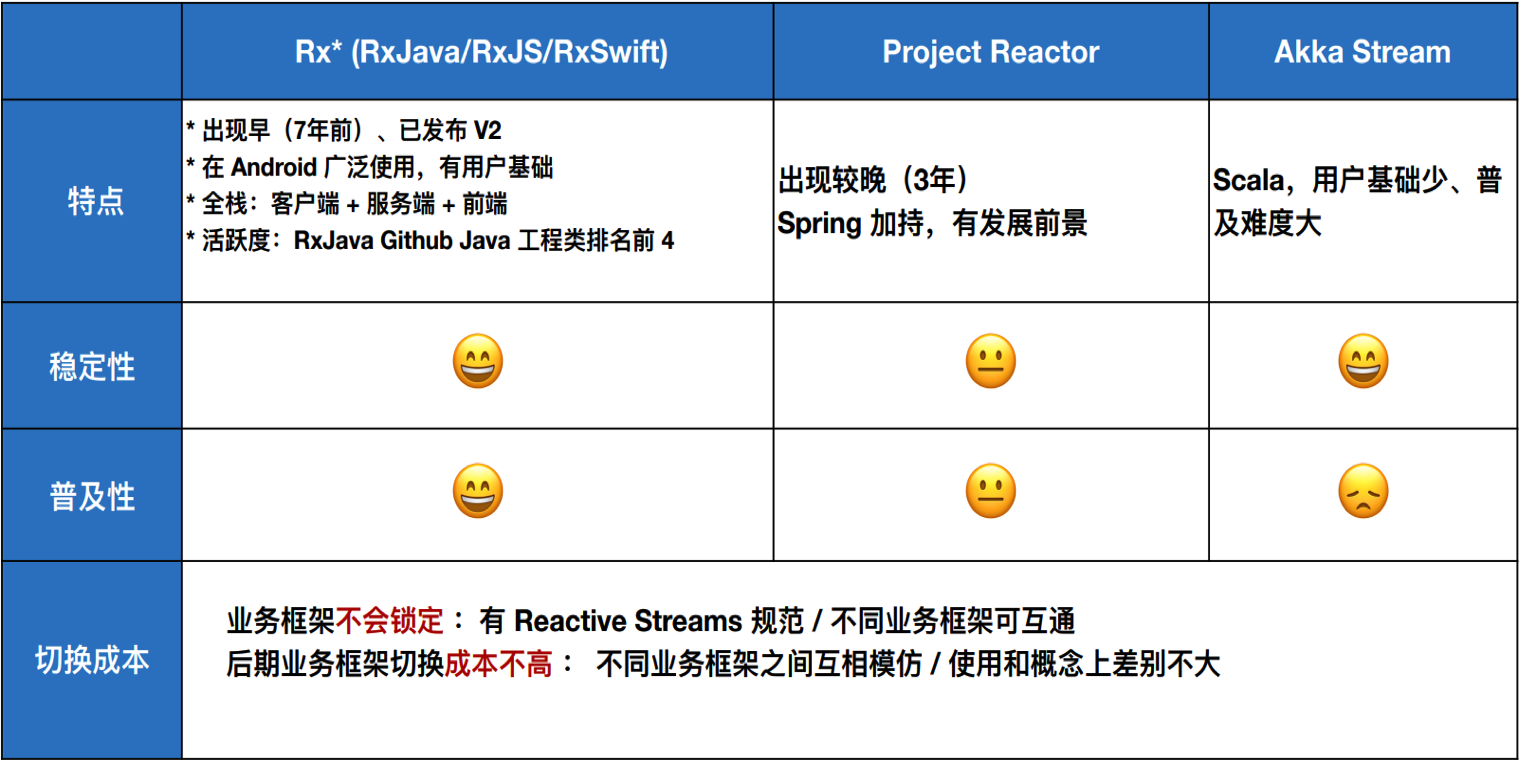
(图片来源:淘宝应用架构升级——反应式架构的探索与实践)
上面这张图也是阿里在2019年的深圳全球架构师峰会上分享的PPT截图(文章末尾有链接),供大家参考,选型标准主要是基于稳定性、普及性、成本这3点考虑
如果是我个人更愿意选择Project Reactor作为首选异步框架,(具体差异网上很多分析,大家可以自行百度谷歌),还有一点是因为Netflix的尿性,推出的开源产品渐渐都不维护了,而且Project Reactor提供了reactor-adapter组件,可以方便的和RxJava的api转换。
其实还有Vert.x也算异步框架 (底层使用netty实现nio, 最新版已支持reactive stream规范)
异步化真正的好处
Scalability
伸缩性主要体现在以下两个方面:
- elastic 弹性
- resilient 容错性
(异步化在平时不会明显降低 RT、提高 QPS,文章开头的数据也是在大促这种流量高峰下的体现出的异步效果)
从架构和应用等更高纬度看待异步带来的好处则会提升系统的两大能力:弹性 和 容错性
前者反映了系统应对压力的表现,后者反映了系统应对故障的表现
1. 容错性
像RxJava,Reactor这些异步框架处理回调数据时一般会切换线程上下文,其实就是使用不同的线程池来隔离不同的数据流处理逻辑,下图说明了这一特性的好处:
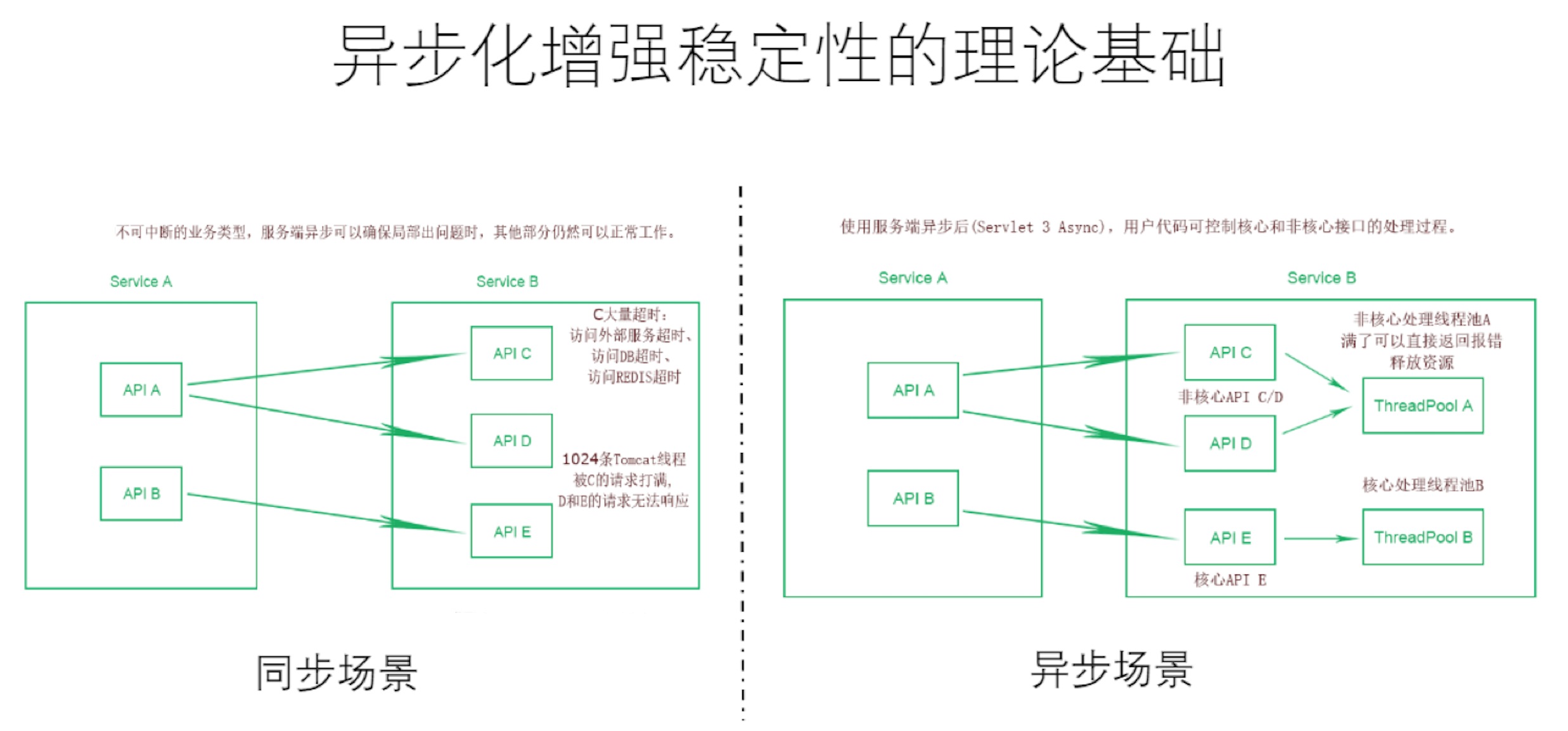
即利用异步框架支持线程池切换的特性实现服务/接口隔离,进而提高系统的高可用。
2. 弹性
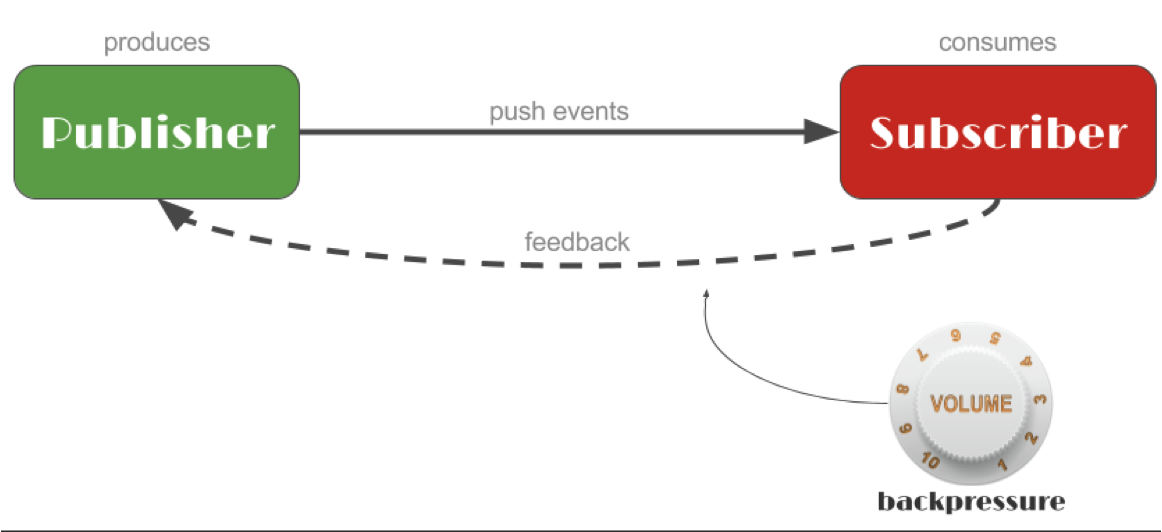
back-pressure是一种重要的反馈机制,相比于传统的熔断限流等方式,是一种更加柔性的自适应限流。使得系统得以优雅地响应负载,而不是在负载下崩溃。
异步化落地的难点及解决方案
还是先看下淘宝总结的异步改造中难点问题:
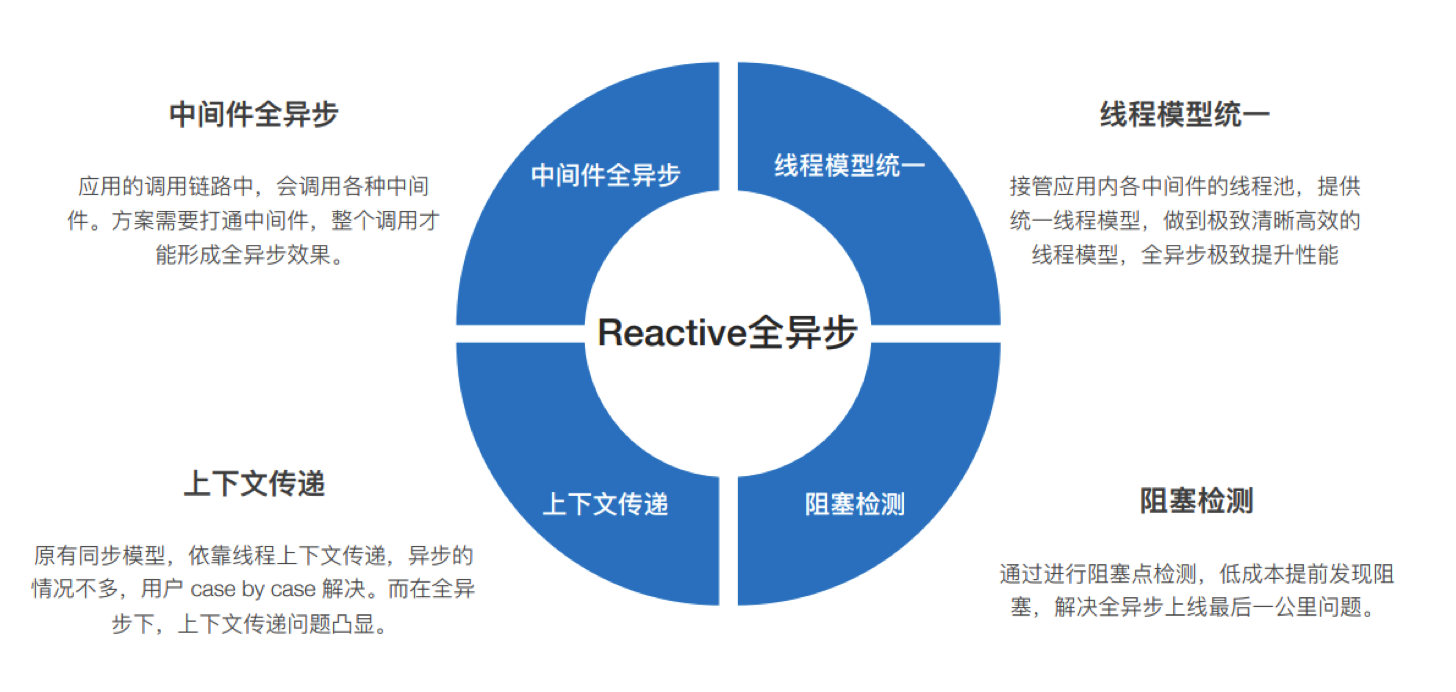
(图片来源:淘宝应用架构升级——反应式架构的探索与实践)
中间件全异步牵涉到到公司中台化战略或框架部门的支持,包括公司内部常用的中间件比如MQ、redis、dal等,超出了本文讨论的范围,感兴趣的可以看下文章末尾的参考资料。
线程模型统一的背景在上一节异步化好处时有提到过,其实主要还是对线程池的管理,做好服务隔离,线程池设置和注意事项可以参考之前的两篇文章:Java踩坑记系列之线程池 、线程池ForkJoinPool简介
这里主要说下上下文传递和阻塞检测的问题:
1. 上下文传递
改造成异步服务后,不能再使用ThreadLocal传递上下文context,因为异步框架比如RxJava一般在收到通知后会先调用observeOn()方法切换成另外一个线程处理回调,比如我们在请求接口时在ThreadLocal的context里设置了一个值,在回调线程里从context里取不到这个值的,因为此时已经不是同一个ThreadLocal了,所以需要我们手动在切换上下文的时候传递context从一个线程到另一个线程环境,伪代码如下:
Context context = ThreadLocalUtils.get(); // 获取当前线程的上下文 single.observeOn(scheduler).doOnEvent((data, error) -> ThreadLocalUtils.set(context)); // 切换线程后在doOnEvent里重新给新的线程赋值context
在observeOn()方法切换成另外一个线程后调用doOnEvent方法将原来的context赋给新的线程ThreadLocal
注意:这里的代码只是提供一种解决思路,实际在使用前和使用后还要考虑清空ThreadLocal,因为线程有可能会回收到线程池下次复用,而不是立即清理,这样就会污染上下文环境。
可以将传递上下文的方法封装成公共方法,不需要每次都手动切换。
2. 阻塞检测
阻塞检测主要是要能及时发现我们某个异步任务长时间阻塞的发生,比如异步线程执行时间过长进而影响整个接口的响应,原来同步场景下我们的日志都是串行记录到ES或Cat上的,现在改成异步后,每次处理接口数据的逻辑可能在不同的线程中完成,这样记录的日志就需要我们主动去合并(依据具体的业务场景而定),如果日志无法关联起来,对我们排查问题会增加很多难度。所幸的是随着异步的流行,现在很多日志和监控系统都已支持异步了。
Project Reactor 自己也有阻塞检测功能,可以参考这篇文章:BlockHound
3. 其他问题
除了上面提到的两个问题外,还有一些比如RxJava2.0之后不支持返回null,如果我们原来的代码或编程习惯所致返回结果有null的情况,可以考虑使用java8的Optional.ofNullable()包装一下,然后返回的RxJava类型是这样的:Single<Optional>,其他异步框架如果有类似的问题同理。
异步其他解决方案:纤程/协程
- Quasar
- Kilim
- Kotlin
- Open JDK Loom
- AJDK wisp2
协程并不是什么新技术,它在很多语言中都有实现,比如 Python、Lua、Go 都支持协程。
协程与线程不同之处在于,线程由内核调度,而协程的调度是进程自身完成的。这样就可以不受操作系统对线程数量的限制,一个线程内部可以创建成千上万个协程。因为上文讲到的异步技术都是基于线程的操作和封装,Java中的线程概念对应的就是操作系统的线程。
1. Quasar、Kilim
开源的Java轻量级线程(协程)框架,通过利用Java instrument技术对字节码进行修改,使方法挂起前后可以保存和恢复JVM栈帧,方法内部已执行到的字节码位置也通过增加状态机的方式记录,在下次恢复执行可直接跳转至最新位置。
2. Kotlin
Kotlin Coroutine 协程库,因为 Kotlin 的运行依赖于 JVM,不能对 JVM 进行修改,因此Kotlin不能在底层支持协程。同时Kotlin 是一门编程语言,需要在语言层面支持协程,所以Kotlin 对协程支持最核心的部分是在编译器中完成,这一点其实和Quasar、Kilim实现原理类似,都是在编译期通过修改字节码的方式实现协程
3. Project Loom
Project Loom 发起的原因是因为长期以来Java 的线程是与操作系统的线程一一对应的,这限制了 Java 平台并发能力提升,Project Loom 是从 JVM 层面对多线程技术进行彻底的改变。
OpenJDK 在2018年创建了 Loom 项目,目标是在JVM上实现轻量级的线程,并解除JVM线程与内核线程的映射。其实 Loom 项目的核心开发人员正是从Quasar项目过来的,目的也很明确,就是要将这项技术集成到底层JVM里,所以Quasar项目目前已经不维护了。。。
4. AJDK Wisp2
Alibaba Dragonwell 是阿里巴巴的 Open JDK 发行版,提供长期支持。dragonwell8已开源协程功能(之前的版本是不支持的),开启jvm命令:-XX:+UseWisp2 即支持协程。
总结
- Future 在异步方面支持有限
- Callback 在编排能力方面有 Callback Hell 的短板
- Project Loom 最新支持的Open JDK版本是16,目前还在测试中
- AJDK wisp2 需要换掉整个JVM,需要考虑改动成本和收益比
所以目前实现异步化比较成熟的方案是 Reactive Streams
以上是老K对异步编程的理解,如有问题欢迎指正。
另外开发人员也不要将自己局限在某种特定技术上,对各种技术都保持开放的态度是开发人员技能不断提高的前提。只会简单说某某语言、某某技术比其它技术更好的人永远不会成为出色的产品[狗头]。
From Reactive, More Than Reactive
文章来源:http://javakk.com/563.html
参考资料
全球架构师峰会:(第二天-淘宝应用架构升级——反应式架构的探索与实践)
https://archsummit.infoq.cn/2019/shenzhen/schedule
Project Reactor:https://projectreactor.io/
RxJava:http://reactivex.io/
openjdk loom:http://jdk.java.net/loom/
wiki:https://wiki.openjdk.java.net/display/loom/Main
github:https://github.com/openjdk/loom
阿里 jdk:https://github.com/alibaba/dragonwell8
原创文章,转载请注明: 转载自并发编程网 – ifeve.com本文链接地址: 一文带你彻底了解Java异步编程

 (9 votes, average: 4.67 out of 5)
(9 votes, average: 4.67 out of 5)

图文并茂,博主用心了,谢谢分享,对我很有帮助。赞!推荐博主使用一个好用的接口管理工具-ApiPost,谢谢博主啦