如何在MQ中实现支持任意延迟的消息?
什么是定时消息和延迟消息?
- 定时消息:Producer 将消息发送到 MQ 服务端,但并不期望这条消息立马投递,而是推迟到在当前时间点之后的某一个时间投递到 Consumer 进行消费,该消息即定时消息。
- 延迟消息:Producer 将消息发送到 MQ 服务端,但并不期望这条消息立马投递,而是延迟一定时间后才投递到 Consumer 进行消费,该消息即延时消息。
定时消息与延迟消息在代码配置上存在一些差异,但是最终达到的效果相同:消息在发送到 MQ 服务端后并不会立马投递,而是根据消息中的属性延迟固定时间后才投递给消费者。
目前业界MQ对定时消息和延迟消息的支持情况

上图是阿里云上对业界MQ功能的对比,其中开源产品中只有阿里的RocketMQ支持延迟消息,且是固定的18个Level。
固定Level的含义是延迟是特定级别的,比如支持3秒、5秒的Level,那么用户只能发送3秒延迟或者5秒延迟,不能发送8秒延迟的消息。
消息队列RocketMQ的阿里云版本(收费版本)才支持到精确到秒级别的延迟消息(没有特定Level的限制)。

上图是CMQ中对MQ功能的对比,其中标明腾讯的CMQ支持延迟消息,但是没有具体写明支持到什么精度,支持任意时间还是特定的Level。

通过腾讯云上CMQ的API文档可以看到有一个秒级别的delaySeconds,应该是支持任意级别的延迟,即和收费版本的RocketMQ一致。
总结
- 开源版本中,只有RocketMQ支持延迟消息,且只支持18个特定级别的延迟
- 付费版本中,阿里云和腾讯云上的MQ产品都支持精度为秒级别的延迟消息
(真是有钱能使鬼推磨啊,有钱就能发任意延迟的消息了,没钱最多只能发特定Level了)
任意延迟的消息难点在哪里?
开源版本没有支持任意延迟的消息,我想可能有以下几个原因:
- 任意延迟的消息的需求不强烈
- 可能是一个比较有技术含量的点,不愿意开源
需求不强
对支持任意延迟的需求确实不强,因为:
- 延迟并不是MQ场景的核心功能,业务单独做一个替代方案的成本不大
- 业务上一般对延迟的需求都是固定的,比如下单后半小时check是否付款,发货后7天check是否收货
在我司(前东家),MQ上线一年多后才有业务方希望我能支持延迟消息,且不要求任意延迟,只要求和RocketMQ开源版本一致,支持一些业务上的级别即可。
不愿意开源
为了差异化(好在云上卖钱),只能降开源版本的功能进行阉割,所以开源版本的RocketMQ变成了只支持特定Level的延迟。
难点在哪里?
既然业务有需求,我们肯定也要去支持。
首先,我们先划清楚定义和边界:
在我们的系统范围内,支持任意延迟的消息指的是:
- 精度支持到秒级别
- 最大支持30天的延迟
本着对自己的高要求,我们并不满足于开源RocketMQ的18个Level的方案。那么,如果我们自己要去实现一个支持任意延迟的消息队列,难点在哪里呢?
- 排序
- 消息存储
首先,支持任意延迟意味着消息是需要在服务端进行排序的。
比如用户先发了一条延迟1分钟的消息,一秒后发了一条延迟3秒的消息,显然延迟3秒的消息需要先被投递出去。那么服务端在收到消息后需要对消息进行排序后再投递出去。
在MQ中,为了保证可靠性,消息是需要落盘的,且对性能和延迟的要求,决定了在服务端对消息进行排序是完全不可接受的。
其次,目前MQ的方案中都是基于WAL的方式实现的(RocketMQ、Kafka),日志文件会被过期删除,一般会保留最近一段时间的数据。
支持任意级别的延迟,那么需要保存最近30天的消息。
阿里内部 1000+ 核心应用使用,每天流转几千亿条消息,经过双11交易、商品等核心链路真实场景的验证,稳定可靠。
考虑一下一天几千亿的消息,保存30天的话需要堆多少服务器,显然是无法做到的。
知己知彼
虽然决定自己做,但是依旧需要先了解开源的实现,那么就只能看看RocketMQ开源版本中,支持18个Level是怎么实现的,希望能从中得到一些灵感。
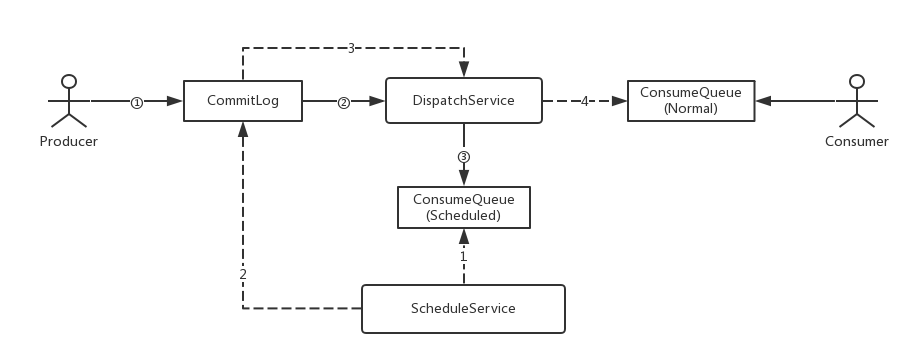
上图是通过RocketMQ源码分析后简化一个实现原理方案示意图。
分为两个部分:
- 消息的写入
- 消息的Schedule
消息写入中:
- 在写入CommitLog之前,如果是延迟消息,替换掉消息的Topic和queueId(被替换为延迟消息特定的Topic,queueId则为延迟级别对应的id)
- 消息写入CommitLog之后,提交dispatchRequest到DispatchService
- 因为在第①步中Topic和QueueId被替换了,所以写入的ConsumeQueue实际上非真正消息应该所属的ConsumeQueue,而是写入到ScheduledConsumeQueue中(这个特定的Queue存放不会被消费)
Schedule过程中:
- 给每个Level设置定时器,从ScheduledConsumeQueue中读取信息
- 如果ScheduledConsumeQueue中的元素已近到时,那么从CommitLog中读取消息内容,恢复成正常的消息内容写入CommitLog
- 写入CommitLog后提交dispatchRequest给DispatchService
- 因为在写入CommitLog前已经恢复了Topic等属性,所以此时DispatchService会将消息投递到正确的ConsumeQueue中
回顾一下这个方案,最大的优点就是没有了排序:
- 先发一条level是5s的消息,再发一条level是3s的消息,因为他们会属于不同的ScheduleQueue所以投递顺序能保持正确
- 如果先后发两条level相同的消息,那么他们的处于同一个ConsumeQueue且保持发送顺序
- 因为level数固定,每个level的有自己独立的定时器,开销也不会很大
- ScheduledConsumeQueue其实是一个普通的ConsumeQueue,所以可靠性等都可以按照原系统的M-S结构等得到保障
但是这个方案也有一些问题:
- 固定了Level,不够灵活,最多只能支持18个Level
- 业务是会变的,但是Level需要提前划分,不支持修改
- 如果要支持30天的延迟,CommitLog的量会很大,这块怎么处理没有看到
站在巨人的肩膀上
总结RocketMQ的方案,通过划分Level的方式,将排序操作转换为了O(1)的ConsumeQueue 的append操作。
我们去支持任意延迟的消息,必然也需要通过类似的方式避免掉排序。
此时我们想到了TimeWheel:《Hashed and Hierarchical Timing Wheels: Data Structures for the Efficient Implementation of a Timer Facility 》
Netty中也是用TimeWheel来优化I/O超时的操作。
TimeWheel
TimeWheel的大致原理如下:
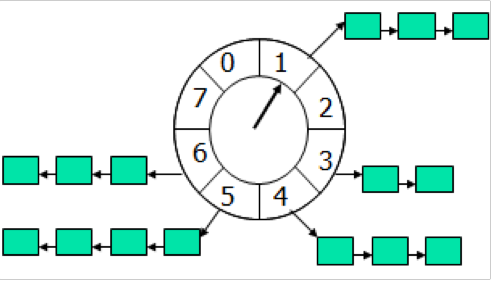
- 箭头按照一定方向固定频率移动(如手表指针),每一次跳动称为一个tick。ticksPerWheel表示一个定时轮上的tick数。
如每次tick为1秒,ticksPerWheel为60,那么这就和现实中的秒针走动完全一致。
TimeWheel应用到延迟消息中
无论定时消息还是延迟消息,最终都是投递后延迟一段时间对用户可见。
假设这个延迟时间为X秒,那么X%(ticksPerWheel * tick)可以计算出X所属的TimeWheel中位置。
这里存在一个问题,以上图为例,TimeWheel的size为8,那么延迟1秒和9秒的消息都处在一个链表中。如果用户先发了延迟9秒的消息再发了延迟1秒的消息,他们在一个链表中所以延迟1秒的消息会需要等待延迟9秒的消息先投递。显然这是不能接受的,那么如何解决这个问题?
排序
显然,如果对TimeWheel一个tick中的元素进行排序显然就解决了上面的问题。但是显而易见的是排序是不可能的。
扩大时间轮
最直观的方式,我们能不能通过扩大时间轮的方式避免延迟9和延迟1落到一个tick位置上?
假设支持30天,精度为1秒,那么ticksPerWheel=30 * 24 * 60 * 60,这样每一个tick上的延迟都是一致的,不存在上述的问题(类似于将RocketMQ的Level提升到了30 * 24 * 60 * 60个)。但是TimeWheel需要被加载到内存操作,这显然是无法接受的。
多级时间轮
单个TimeWheel无法支持,那么能否显示中的时针、分针的形式,构建多级时间轮来解决呢?
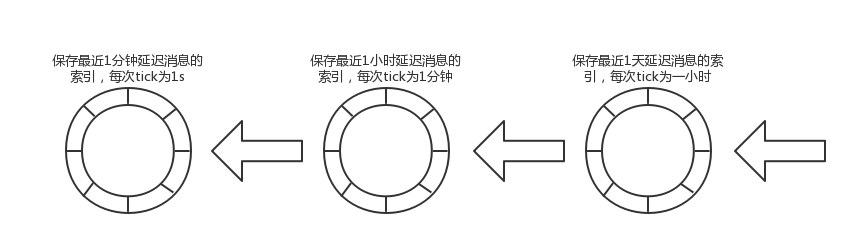
多级时间轮解决了上述的问题,但是又引入了新的问题:
- 在整点(tick指向0的位置)需要加载大量的数据会导致延迟,比如第二个时间轮到整点需要加载未来一天的数据
- 时间轮需要载入到内存,这个开销是不可接受的
延迟加载
多级定时轮的问题在于需要加载大量数据到内存,那么能否优化一下将这里的数据延迟加载到内存来解决内存开销的问题呢?
在多级定时轮的方案中,显然对于未来一小时或者未来一天的数据可以不加载到内存,而可以只加载延迟时间临近的消息。
进一步优化,可以将数据按照固定延迟间隔划分,那么每次加载的数据量是大致相同的,不会出tick约大的定时轮需要加载越多的数据,那么方案如下:
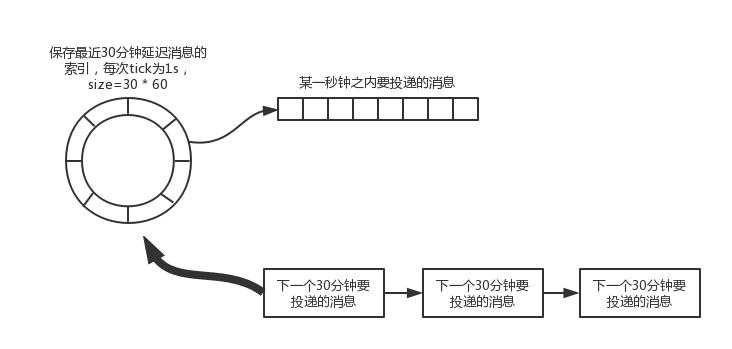
基于上述的方案,那么TimeWheel中存储未来30分钟需要投递的消息的索引,索引为一个long型,那么数据量为:30 * 60 * 8 * TPS,相对来说内存开销是可以接受的,比如TPS为1w那么大概开销为200M+。
之后的数据按照每30分钟一个块的形式写入文件,那么每个整点时的操作就是计算一下将30分钟的消息Hash到对应的TimeWheel上,那么排序问题就解决了。
到此为止就只剩下一个问题,如何保存30天的数据?
CommitLog保存超长延迟的数据
CommitLog是有时效性的,比如在我们只保存最近7天的消息,过期数据将被删除。对于延迟消息,可能需要30天之后投递,显然是不能被删除的。
那么我们怎么保存延迟消息呢?
直观的方法就是将延迟消息从CommitLog中剥离出来,独立存储以保存更长的时间。
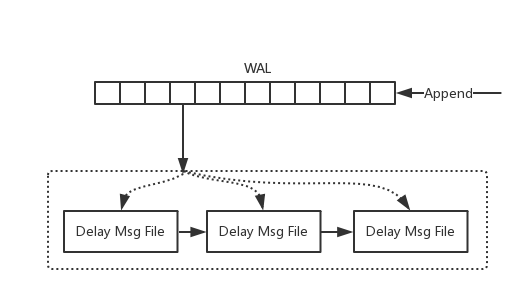
通过DispatchService将WAL中的延迟消息写入到独立的文件中。这些文件按照延迟时间组成一个链表。
链表长度为最大延迟时间/每个文件保存的时间长度。
那么WAL可以按照正常的策略进行过期删除,Delay Msg File则在一个文件投递完之后进行删除。
唯一的问题是这里会有Delay Msg File带来的随机写问题,但是这个对系统整体性能不会有很大影响,在可接受范围内。
BOUNS
结合TimeWheel和CommitLog保存超长延迟数据的方案,加上一些优化手段,基本就完成了支持任意延迟时间的方案:
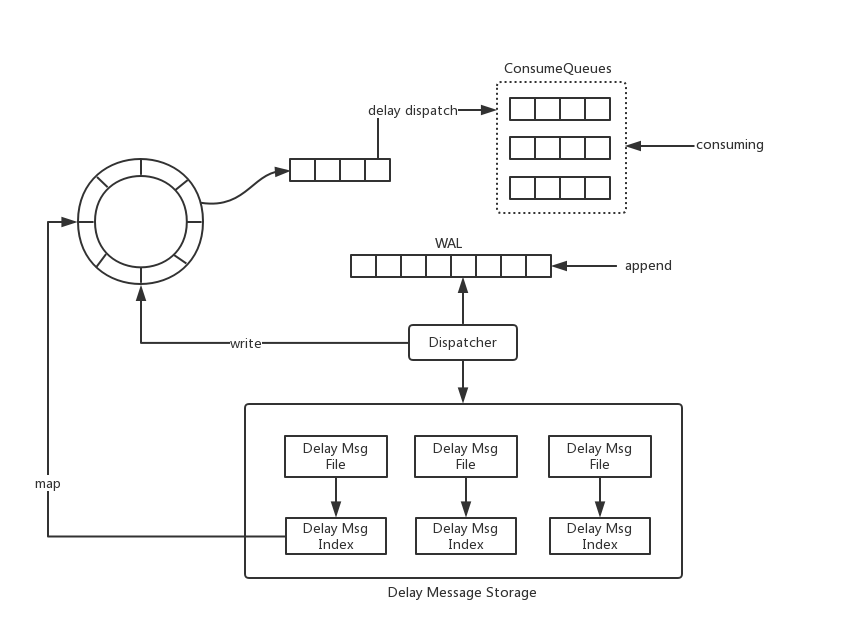
- 消息写入WAL
- Dispatcher处理延迟消息
- 延迟消息一定时间的直接写入TimeWheel
- 延迟超过一定时间写入DelayMessageStorage
- DelayMessageStorage对DelayMsgFile构建一层索引,这样在映射到TimeWheel时只需要做一次Hash操作
- 通过TimeWheel将消息投递到ConsumeQueue中完成对Consumer的可见
通过这个方案解决了最初提出来的任意延迟消息的两个难点:
- 消息的排序问题
- 超长延迟消息的存储问题
最后
本文从延迟消息的概念出发,了解业界的支持情况,确定延迟消息的难点和支持边界,最后通过一步步推导完成了一个相对来说从内存开销和性能上都可以满足期望的方案。
对本文有任何问题欢迎通过公公众号留言或添加我的微信交流。

原创文章,转载请注明: 转载自并发编程网 – ifeve.com本文链接地址: 如何在MQ中实现支持任意延迟的消息?

 (8 votes, average: 4.25 out of 5)
(8 votes, average: 4.25 out of 5)

暂无评论