理解Storm的内部消息缓冲机制
原文链接 作者:Michael G. Noll 译者:lendo
这篇文章是Apache Kafka的作者之一Michael G. Noll写的,他的博客地址在[这里]。
Storm工作进程(Worker processes)的内部消息机制
在以下各章节中,我会交替地使用消息(message)和元组(tuple)两个关键字。
本文中当我提到“内部消息”时,它指的是发生在Storm的单个工作进程内部的消息通信,这类通信只在Storm集群的单台主机(节点)上展开。Storm使用由LMAX Disruptor提供的很多消息队列来完成通信,LMAX Disruptor是一个高性能的线程间消息通信库。
- Storm工作进程内部的通信(同一个Storm工作节点(主机)的线程之间):LMAX Disruptor
- 工作进程之间的通信(通过网络的工作节点(主机)之间):ZeroMQ或者Netty
- 计算拓扑之间的通信:Storm并不原生支持,需要自己实现和维护,可以使用消息系统,比如:Kafka,RabbitMQ和数据库等等。
图片说明
在下一节讨论具体细节前,我们先来看看如下这幅图(参考原图):
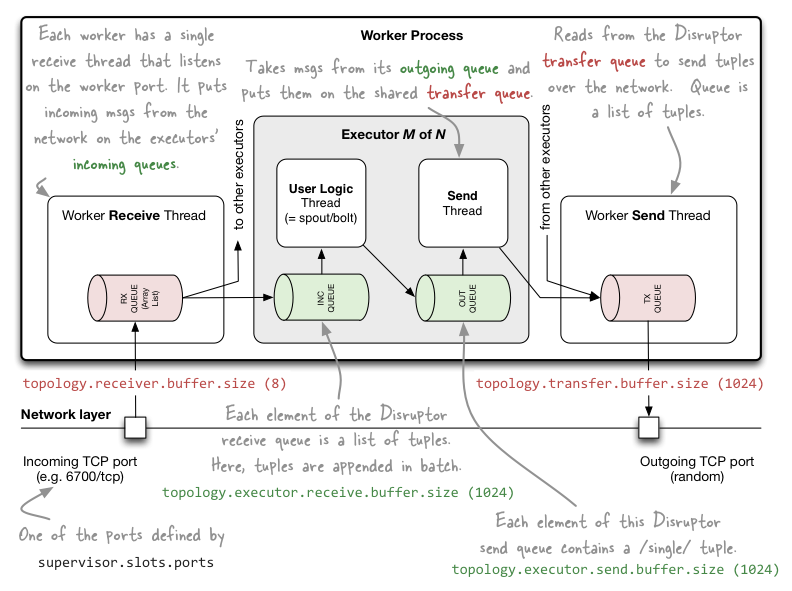
详细描述
现在我们对Storm的工作进程内部的消息机制有了一定了解,接下来可以深入讨论细节了。
工作进程(Worker processes)
- “topology.receiver.buffer.size”参数是工作进程中的接收线程批量向执行线程的输入队列发送数据时的缓冲区内消息数的最大值(接收线程从网络读取消息),此参数如果设置过大可能会造成一些问题(心跳线程挂掉然后吞吐率直线下降),默认值是8条消息,设置的值必须是2的幂(N次方),这是为了兼容LMAX Disruptor组件。
// 示例: 通过Java API配置
Config conf = new Config();
conf.put(Config.TOPOLOGY_RECEIVER_BUFFER_SIZE, 16); // 默认值为8topology.receiver.buffer.size参数不是配置LMAX Disruptor队列的大小,它是配置的一个ArrayList的长度,这个List用来作为输入消息的缓冲,它不需要被多个线程访问,它仅仅是工作进程所专有的,但是因为这个List的元素最终被用来填充基于Disruptor的队列(执行器输入对列),所以这个参数必须是2的幂,参考backtype.storm.messaging.loader.clj的launch-receive-thread!详细信息。
- 使用“topology.transfer.buffer.size”参数配置的transfer缓冲区中的每一个元素实际上是一个tuple的列表,多个Executor中的消息发送线程将批量地把消息从outgoing发送到多个Executor共享的transfer缓冲区(Executor中包含用户逻辑线程和消息发送线程),transfer缓冲区的大小默认是1024个元素。
// 示例: 通过JavaAPI配置
conf.put(Config.TOPOLOGY_TRANSFER_BUFFER_SIZE, 32); // 默认值为1024
执行器(Executors)
- topology.executor.receive.buffer.size,该参数是执行器的输入消息队列的配置参数,队列的每个元素是一个tuple列表,tuple被批量地加入到队列元素中,此参数的默认配置是1024个元素,修改配置时的值必须是2的幂(适配于LMAX Disruptor)。
// 示例: 通过Java API配置
conf.put(Config.TOPOLOGY_EXECUTOR_RECEIVE_BUFFER_SIZE, 16384); // 批量加入tuple; 默认值是1024 - topology.executor.send.buffer.size,该参数是执行器输入消息队列的配置参数,这个队列的每个元素是一个单独的tuple,默认值为1024,修改配置时的值必须是2的幂(适配于LMAX Disruptor)。
// 示例: 通过Java API配置
conf.put(Config.TOPOLOGY_EXECUTOR_SEND_BUFFER_SIZE, 16384); // 单独的tuple; 默认值是1024
更进一步
如何配置Storm的内部消息缓冲
如何配置Storm的parallelism(并行)参数(实际上就是配置集群中工作进程数,各个Spout和Bolt的实例数和线程数)
搞明白Storm的拓扑内部在做什么
Sending Metrics From Storm to Graphite
Installing and Running Graphite via RPM and Supervisord
ooyala放在Github上的metrics_storm项目也是值得参考的(但我还没有用过这个工具)。
性能优化的建议
[code]
conf.put(Config.TOPOLOGY_RECEIVER_BUFFER_SIZE, 8);
conf.put(Config.TOPOLOGY_TRANSFER_BUFFER_SIZE, 32);
conf.put(Config.TOPOLOGY_EXECUTOR_RECEIVE_BUFFER_SIZE, 16384);
conf.put(Config.TOPOLOGY_EXECUTOR_SEND_BUFFER_SIZE, 16384);
[/code]
原创文章,转载请注明: 转载自并发编程网 – ifeve.com本文链接地址: 理解Storm的内部消息缓冲机制





暂无评论