可扩展的快速读写锁
原文链接(需翻墙) ,译文链接, 译者:中麦-张军 ,校对:梁海舰
介绍
读写锁是一种允许多个线程并发地访问一个或一组资源的并发结构,这意味着在实践中如果你有一个或一组几乎是以只读方式访问时,可以考虑使用读写锁(后文统称为RWLocks)来保护它们;
Java在java.util.concurrent.locks.ReentrantReadWriteLock中提供了一个很好的RWLocks,是由Doug Lea创建,它有很多特性如:重入,公平锁,锁降级等;
如果你是一个无法摆脱PThreads的C开发者,你可以使用pthread_rwlock_t及相关函数:
int pthread_rwlock_destroy(pthread_rwlock_t *);
int pthread_rwlock_init(pthread_rwlock_t *, const pthread_rwlockattr_t *);
int pthread_rwlock_rdlock(pthread_rwlock_t *);
int pthread_rwlock_tryrdlock(pthread_rwlock_t *);
int pthread_rwlock_trywrlock(pthread_rwlock_t *);
int pthread_rwlock_unlock(pthread_rwlock_t *);
int pthread_rwlock_wrlock(pthread_rwlock_t *);它们同样拥有丰富的特性如:重入及优先级继承(这里不再展开,那是另外一篇的主题);
如果你有一个非线程安全的数据结构,主要是读,很少写,用RWLocks保护它通常是一个好方法,至少比用一个简单互斥(Mutex)要好。根据经验,一般的数据结构90%的访问是读,9%是插入,1%是删除,这使得我们更应该考虑使用读写锁;
那些决定在大量竞争环境下使用RWLocks的人,要注意安全哦;要知道,大部分RWLock使用一个变量来保存当前进行读操作的线程数,导致在单一变量上产生大量的争用,我们把这个变量称作read_counter,当lock()和unlock()之间的计算足够长时,相比锁机制本身,在read_counter上的争用低,应用不会有性能损失;如果相反,在lock()和unlock()之间处理时间很短,会有在read_counter上产生大量竞争的风险,因为有多个线程试图读写同一高速缓存行,即read_counter在内存中的地址;
如果你认为一个高速缓存行被一个4核处理器上的所有线程激烈的争夺是不好的,那么等到你程序跑在一个64核处理器上看看性能有多大提升;
我不是一个热衷批评什么的人,除非我们有一个替代方案,因此,这篇文章的其余部分将描述一个可扩展的快速RWLock:)
如果你不想浪费时间,可以直接跳到ScalableRWLock.java查看源码;
算法
成员变量定义
我们开始定义一个readers_states数组,其中的每项可由不同的读线程拥有,还定义一个write_state变量,将由试图做写操作的线程共享;
private AtomicIntegerArray readers_states; private char[] pad1; private AtomicInteger write_state;
我们在readers_states和write_state之间增加一些填充以确保readers_states数组中最后一项不会跟write_state变量共享同一个高速缓存行;
数组readers_states中每项的可用状态值如下:
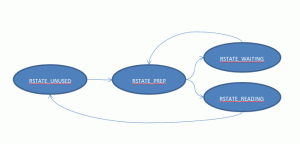
RSTATE_UNUSED: 该线程拥有该项但没试图访问由RWLock所保护的资源;
RSTATE_PREP: 该线程拥有该项即将试图获取只读锁;
RSTATE_WAITING: 该线程试图获取只读锁但发现有线程已经在写模式下获得锁并在或将要做写操作,该线程可能将处于放弃/休眠状态;
RSTATE_READING: 该线程在只读模式下获取锁并在访问由RWLock所保护的资源。
private final int RSTATE_UNUSED = 0; // -> RSTATE_PREP private final int RSTATE_WAITING = 1; // -> RSTATE_PREP private final int RSTATE_PREP = 2; // -> RSTATE_WAITING or -> STATE_READING private final int RSTATE_READING = 3; // -> RSTATE_UNUSED
注意到RSTATE_PREP的数值要比RSTATE_WAITING大,这源于后面我们将会看到的一个代码优化,同时,下面是读线程的状态转换图:
同一时间只有一个或没有写线程访问锁,所以,我们使用单个变量来保存状态,它只有如下两个状态值:
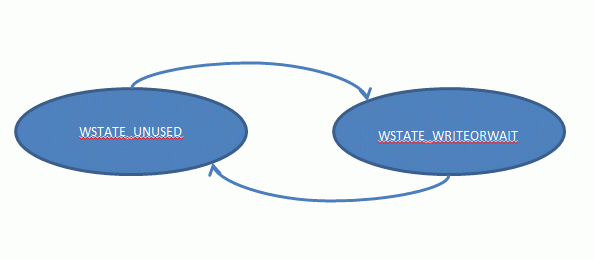
private final int WSTATE_UNUSED = 0; // -> WSTATE_WRITEORWAIT private final int WSTATE_WRITEORWAIT = 1; // -> WSTATE_UNUSED
WSTATE_WRITEORWAIT意味着一个线程已经获取写模式下的锁,尽管仍然需要扫描readers_states等待所有的读操作完成。写线程的状态转换图很简单:
接下来,我们需要一个thread-local变量tid,用来存放分配给当前线程在readers_states数组中的下标:
private transient final ThreadLocal tid; private final ReentrantLock mutex; private AtomicInteger num_assigned; private long[] assigned_threads; // Protected by mutex
构造函数
现在我们来写构造函数,首先为readers_states分配一个大小为MAX_NUM_THREADS*CACHE_PADD的数组,这里使用乘法因子CACHE_PADD是因我们要确保数组中的每一项都有自己的高速缓存行,这也意味着我们留了很多空白空间,但当多个线程同时读时在高速缓存行级别不会有争用;
/**
* Default constructor.
*/
ScalableRWLock() {
// States of the Readers, one per thread
readers_states = new AtomicIntegerArray(MAX_NUM_THREADS*CACHE_PADD);
for (int i = 0; i < MAX_NUM_THREADS*CACHE_PADD; i+=CACHE_PADD) {
readers_states.set(i, RSTATE_UNUSED);
}
pad1 = new char[CACHE_LINE];
pad1[3] = 42;
writer_state = new AtomicInteger(0);
// This is AtomicInteger because it will be read outside of the mutex
num_assigned = new AtomicInteger(0);
assigned_threads = new long[MAX_NUM_THREADS];
for (int i = 0; i < MAX_NUM_THREADS; i++)
assigned_threads[i] = -1;
}
数组assigned_threads的项都被初始化为-1意味着它们是空闲的,稍后将会被threadInit()用Thread.currentThread().getId()的返回值来填充;
线程初始化和清理
我们创建threadInit()函数来查找和分配一个readers_states数组(和assigned_threads数组)中的空闲项,并将其数组下标保存在tid中。值得注意的是,实际分配空闲项时由ReentrantLock来保护,这在性能上来说很好,因为每个线程只做一次;
public void threadInit() {
if (num_assigned.get() >= MAX_NUM_THREADS) {
System.out.println("ERROR: MAX_NUM_THREADS exceeded");
return;
}
mutex.lock();
for (int i = 0; i < MAX_NUM_THREADS; i++) {
if (assigned_threads[i] == -1) {
assigned_threads[i] = Thread.currentThread().getId();
tid.set(i);
num_assigned.incrementAndGet();
break;
}
}
mutex.unlock();
}
注意num_assigned通过使用incrementAndGet()以原子的方式递增且有完整的内存屏障,之所以这样是因为其后续被访问时没有对mutex加锁;
在线程退出前,必须调用threadCleanup()来释放所占用的readers_states和assigned_threads数组项,好让其他新建线程可以使用:
public void threadCleanup() {
mutex.lock();
assigned_threads[tid.get()] = -1;
// Search the highest non-occupied entry and set the num_assigned to it
for (int i = MAX_NUM_THREADS-1; i > 0; i--) {
if (assigned_threads[i] != -1) {
num_assigned.set(i+1);
break;
}
}
mutex.unlock();
}
这里有个不太明显的优化:我们在这里从后往前查找assigned_threads中的空闲项,但threadInit()在进行分配时是从前到后查找第一个可用项,据我所知,没有简单的方法来改善这一点,但能使用num_assigned作为被搜索的最大起始项,可参见writeLock()中的遍历来了解这样做背后的原因;
读锁
事情开始变得有趣,我们来看看只读锁机制。
开始我们设置线程的readers_states数组项为RSTATE_PREP,这会提示可能的写线程,该线程将要启动一个读操作,或者说,该线程看到一个写线程将要启动并等待它完成;如果一个写线程已经启动,或者将要启动,write_state将设被为1,读线程将变为RSTATE_WAITING状态并通过yield()放弃运行,直到writer_state变成 WSTATE_WRITEORWAIT状态;
public void readLock() {
int local_tid = tid.get()*CACHE_PADD;
readers_states.set(local_tid, RSTATE_PREP);
if (writer_state.get() > 0) {
// There is a Writer waiting or working, we must yield()
while (writer_state.get() > 0) {
readers_states.set(local_tid, RSTATE_WAITING);
while(writer_state.get() > 0) Thread.yield();
readers_states.set(local_tid, RSTATE_PREP);
}
}
// Read-Lock obtained
readers_states.set(local_tid, RSTATE_READING);
}
解锁只需将当前读线程恢复到RSTATE_UNUSED状态,这可通过.set()来完成,甚至通过.lazySet()来完成,但延迟设置可能会使一个写线程继续等待;
public void readUnlock() {
int local_tid = tid.get()*CACHE_PADD;
readers_states.set(local_tid, RSTATE_UNUSED);
}
结果
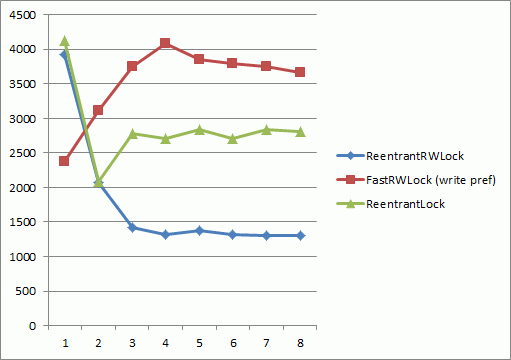
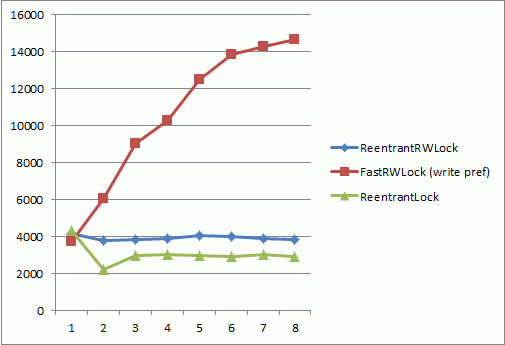
下面的测量在8线程Intel酷睿i7处理器上进行,横轴是在只读模式下并发访问64字节数组的线程数,纵轴表示每milisecond的平均操作数(越高越好);
1/5是写操作
1/10是写操作

1/100是写操作
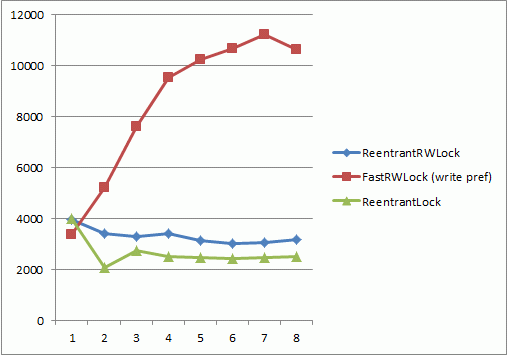
没有写只有读
总结
我们已经展示了可以设计一个能扩展线程数的读写锁。如果写操作相对读操作的比例大于1/10,应该考虑到在低争用的情况下会有性能损失,另一方面讲,如果真是一个低争用的环境,你也不需要担心读写锁(rw-locks)的效率;
在实践中,这种解决方案具备相当的潜力用于代替传统的rwlocks。
优点
- 大量的并发线程时具有可扩展性;
- 实现不是太复杂;
- 速度快,即使在只有读的低争用情况下。
缺点
- 每个线程和每个ScalableRWLock实例都需要调用threadInit()和threadCleanup(), 这将会成为问题如果你的应用程序创建/销毁大量的线程用来访问由FastRWLock(译者注:FastRWLock应该是ScalableRWLock,这里讨论的是ScalableRWLock,全文也未提到FastRWLock)保护的资源或代码;
- 大量写的情况下比ReentrantReadWriteLock等传统RWLocks慢。
文件:
Source code
Test-suite jar
Test-suite source code
原创文章,转载请注明: 转载自并发编程网 – ifeve.com本文链接地址: 可扩展的快速读写锁

 (1 votes, average: 4.00 out of 5)
(1 votes, average: 4.00 out of 5)

传统读写锁的优化解决方案。