《kafka中文手册》-快速开始
- 1.1 Introduction
- Kafka™ is a distributed streaming platform. What exactly does that mean? Kafka是一个分布式数据流处理系统, 这意味着什么呢?
- Topics and Logs 主题和日志
- Distribution 分布式
- Producers 生产者
- Consumers 消费者
- Guarantees 保障
- Kafka as a Messaging System kafka当作消息系统
- Kafka as a Storage System kafka当作储存系统
- Kafka for Stream Processing kafka作为数据流处理
- Putting the Pieces Together 把各个块整合起来
- 1.2 Use Cases 用例
- 1.3 Quick Start 快速开始
- 1.4 Ecosystem
- 1.5 Upgrading From Previous Versions
1.1 Introduction
Kafka™ is a distributed streaming platform. What exactly does that mean? Kafka是一个分布式数据流处理系统, 这意味着什么呢?
We think of a streaming platform as having three key capabilities:我们回想下流数据处理系统的三个关键能力指标
- It lets you publish and subscribe to streams of records. In this respect it is similar to a message queue or enterprise messaging system.系统具备发布和订阅流数据的能力, 在这方面, 它类似于消息队列或企业消息总线
- It lets you store streams of records in a fault-tolerant way.系统具备在存储数据时具备容错能力
- It lets you process streams of records as they occur.系统具备在数据流触发时进行实时处理
What is Kafka good for?那kafka适用在哪些地方?
It gets used for two broad classes of application: 它适用于这两类应用
- Building real-time streaming data pipelines that reliably get data between systems or applications 在系统或应用间需要相互进行数据流交互处理的实时系统
- Building real-time streaming applications that transform or react to the streams of data 需要对数据流中的数据进行转换或及时处理的实时系统
To understand how Kafka does these things, let’s dive in and explore Kafka’s capabilities from the bottom up. 为了了解Kafka做了哪些事情, 我们开始从下往上分析kafka的能力
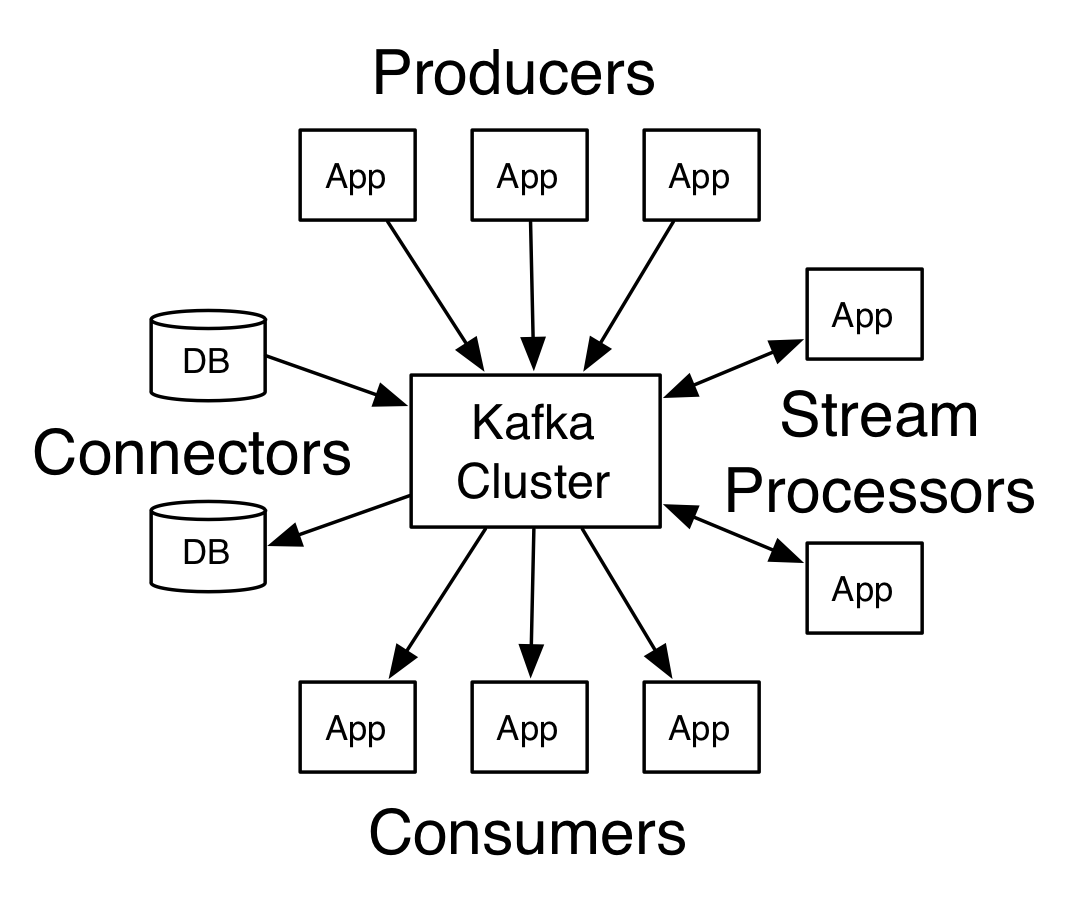
First a few concepts: 首先先了解这几个概念
- Kafka is run as a cluster on one or more servers. kafka是一个可以跑在一台或多台服务器上的集群
- The Kafka cluster stores streams of records in categories called topics. Kafka集群存储不同的数据流以topic形式进行划分
- Each record consists of a key, a value, and a timestamp. 每条数据流中的每条记录包含key, value, timestamp三个属性
Kafka has four core APIs: Kafka拥有4个核心的api
- The Producer API allows an application to publish a stream records to one or more Kafka topics. Producer API 用于让应用发布流数据到Kafka的topic中
- The Consumer API allows an application to subscribe to one or more topics and process the stream of records produced to them. Consumer API 用于让应用订阅一个或多个topic后, 获取数据流进行处理
- The Streams API allows an application to act as a stream processor, consuming an input stream from one or more topics and producing an output stream to one or more output topics, effectively transforming the input streams to output streams. Streams API 用于让应用传教流处理器, 流处理器的输入可以是一个或多个topic, 并输出数据流结果到一个或多个topic中, 它提供一种有效的数据流处理方式
- The Connector API allows building and running reusable producers or consumers that connect Kafka topics to existing applications or data systems. For example, a connector to a relational database might capture every change to a table. Connector API 用于为现在的应用或数据系统提供可重用的生产者或消费者, 他们连接到kafka的topic进行数据交互. 例如, 创建一个到关系型数据库连接器, 用于捕获对某张表的所有数据变更
In Kafka the communication between the clients and the servers is done with a simple, high-performance, language agnostic TCP protocol. This protocol is versioned and maintains backwards compatibility with older version. We provide a Java client for Kafka, but clients are available in many languages. Kafka 基于简单、高效的tcp协议完成服务器端和客户端的通讯, 该协议是受版本控制的, 并可以兼容老版本. 我们有提供java的kafka客户端, 但也提供了很多其他语言的客户端
Topics and Logs 主题和日志
Let’s first dive into the core abstraction Kafka provides for a stream of records—the topic.首先我们考察下kafka提供的核心数据流结构– topic(主题)
A topic is a category or feed name to which records are published. Topics in Kafka are always multi-subscriber; that is, a topic can have zero, one, or many consumers that subscribe to the data written to it. topic是一个分类栏目,由于记录一类数据发布的位置. topic在kafka中通常都有多个订阅者, 也就是说一个topic在写入数据后, 可以零个, 一个, 或多个订阅者进行消费
For each topic, the Kafka cluster maintains a partitioned log that looks like this: 针对每个topic队列, kafka集群构建一组这样的分区日志:
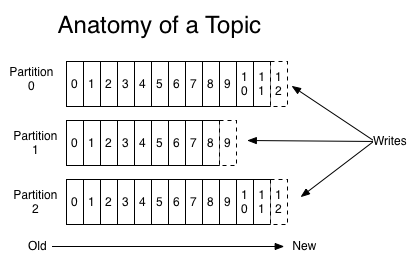 Each partition is an ordered, immutable sequence of records that is continually appended to—a structured commit log. The records in the partitions are each assigned a sequential id number called the offset that uniquely identifies each record within the partition.
Each partition is an ordered, immutable sequence of records that is continually appended to—a structured commit log. The records in the partitions are each assigned a sequential id number called the offset that uniquely identifies each record within the partition.
每个日志分区都是有序, 不可变, 持续提交的结构化日志, 每条记录提交到日志分区时, 都分配一个有序的位移对象offset, 用以唯一区分记数据在分区的位置
The Kafka cluster retains all published records—whether or not they have been consumed—using a configurable retention period. For example, if the retention policy is set to two days, then for the two days after a record is published, it is available for consumption, after which it will be discarded to free up space. Kafka’s performance is effectively constant with respect to data size so storing data for a long time is not a problem.
无论发布到Kafka的数据是否有被消费, 都会保留所有已经发布的记录, Kafka使用可配置的数据保存周期策略, 例如, 如果保存策略设置为两天, 则两天前发布的数据可以被订阅者消费, 过了两天后, 数据占用的空间就会被删除并回收. 在存储数据上, kafka提供高效的O(1)性能处理算法, 所以保存长期时间不是一个问题
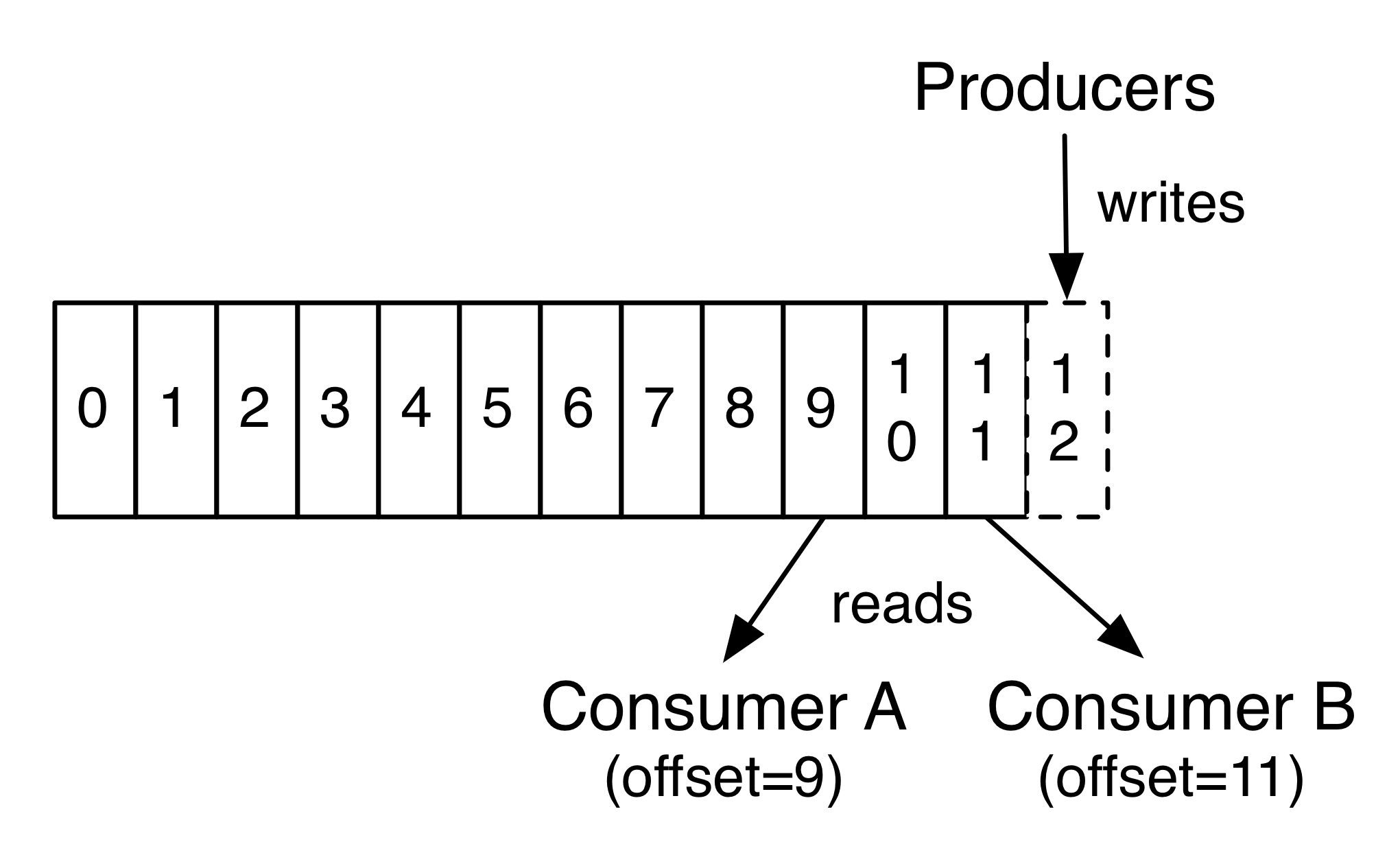 In fact, the only metadata retained on a per-consumer basis is the offset or position of that consumer in the log. This offset is controlled by the consumer: normally a consumer will advance its offset linearly as it reads records, but, in fact, since the position is controlled by the consumer it can consume records in any order it likes. For example a consumer can reset to an older offset to reprocess data from the past or skip ahead to the most recent record and start consuming from “now”.
In fact, the only metadata retained on a per-consumer basis is the offset or position of that consumer in the log. This offset is controlled by the consumer: normally a consumer will advance its offset linearly as it reads records, but, in fact, since the position is controlled by the consumer it can consume records in any order it likes. For example a consumer can reset to an older offset to reprocess data from the past or skip ahead to the most recent record and start consuming from “now”.
实际上, 每个消费者唯一保存的元数据信息就是消费者当前消费日志的位移位置. 位移位置是被消费者控制, 正常情况下, 如果消费者读取记录后, 位移位置往前移动. 但是事实上, 由于位移位置是消费者控制的, 所以消费者可以按照任何他喜欢的次序进行消费, 例如, 消费者可以重置位移到之前的位置以便重新处理数据, 或者跳过头部从当前最新的位置进行消费
This combination of features means that Kafka consumers are very cheap—they can come and go without much impact on the cluster or on other consumers. For example, you can use our command line tools to “tail” the contents of any topic without changing what is consumed by any existing consumers.
这些特性表明Kafka消费者消费的代价是十分小的, 消费者可以随时消费或停止, 而对集群或其他消费者没有太多的影响, 例如你可以使用命令行工具, 像”tail”工具那样读取topic的内容, 而对其它消费者没有影响
The partitions in the log serve several purposes. First, they allow the log to scale beyond a size that will fit on a single server. Each individual partition must fit on the servers that host it, but a topic may have many partitions so it can handle an arbitrary amount of data. Second they act as the unit of parallelism—more on that in a bit.
分区在日志中有几个目的, 首先, 它能扩大日志在单个服务器里面的大小, 每个分区大小必须适应它从属的服务器的规定的大小, 但是一个topic可以有任意很多个分区, 这样topic就能存储任意大小的数据量, 另一方面, 分区还和并发有关系, 这个后面会讲到
Distribution 分布式
The partitions of the log are distributed over the servers in the Kafka cluster with each server handling data and requests for a share of the partitions. Each partition is replicated across a configurable number of servers for fault tolerance.
kafka的日志分区机制跨越整个kafka日志集群, 每个服务器使用一组公用的分区进行数据处理, 每个分区可以在集群中配置副本数
Each partition has one server which acts as the “leader” and zero or more servers which act as “followers”. The leader handles all read and write requests for the partition while the followers passively replicate the leader. If the leader fails, one of the followers will automatically become the new leader. Each server acts as a leader for some of its partitions and a follower for others so load is well balanced within the cluster.
每个分区都有一台服务器是主的, 另外零台或多台是从服务器, 主服务器责所有分区的读写请求, 从服务器被动从主分区同步数据. 如果主服务器分区的失败了, 那么备服务器的分区就会自动变成主的. 每台服务器的所有分区中, 只有部分会作为主分区, 另外部分作为从分区, 这样可以在集群中对个个服务器做负载均摊
Producers 生产者
Producers publish data to the topics of their choice. The producer is responsible for choosing which record to assign to which partition within the topic. This can be done in a round-robin fashion simply to balance load or it can be done according to some semantic partition function (say based on some key in the record). More on the use of partitioning in a second!
生产者发布消息到他们选择的topic中, 生产者负责选择记录要发布到topic的那个分区中, 这个可以简单通过轮询的方式进行负载均摊, 或者可以通过特定的分区选择函数(基于记录特定键值), 更多分区的用法后面马上介绍
Consumers 消费者
Consumers label themselves with a consumer group name, and each record published to a topic is delivered to one consumer instance within each subscribing consumer group. Consumer instances can be in separate processes or on separate machines.
消费者使用消费组进行标记, 发布到topic里面的每条记录, 至少会被消费组里面一个消费者实例进行消费. 消费者实例可以是不同的进程, 分布在不同的机器上
If all the consumer instances have the same consumer group, then the records will effectively be load balanced over the consumer instances.
如果所有的消费者属于同一消费组, 则记录会有效地分摊到每一个消费者上, 也就是说每个消费者只会处理部分记录
If all the consumer instances have different consumer groups, then each record will be broadcast to all the consumer processes.
如果所有的消费者都属于不同的消费组, 则记录会被广播到所有的消费者上, 也就说每个消费者会处理所有记录
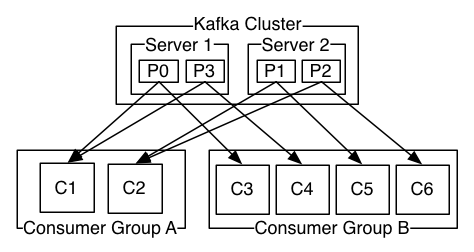 A two server Kafka cluster hosting four partitions (P0-P3) with two consumer groups. Consumer group A has two consumer instances and group B has four.
A two server Kafka cluster hosting four partitions (P0-P3) with two consumer groups. Consumer group A has two consumer instances and group B has four.
图为一个2个服务器的kafka集群, 拥有4个分区, 2个消费组, 消费组A有2个消费者, 消费组B有4个消费者
More commonly, however, we have found that topics have a small number of consumer groups, one for each “logical subscriber”. Each group is composed of many consumer instances for scalability and fault tolerance. This is nothing more than publish-subscribe semantics where the subscriber is a cluster of consumers instead of a single process.
在大多数情况下, 一般一个topic值需要少量的消费者组, 一个消费组对应于一个逻辑上的消费者. 每个消费组一般包含多个实例用于容错和水平扩展. 这仅仅是发布订阅语义,其中订阅者是消费者群集,而不是单个进程.
The way consumption is implemented in Kafka is by dividing up the partitions in the log over the consumer instances so that each instance is the exclusive consumer of a “fair share” of partitions at any point in time. This process of maintaining membership in the group is handled by the Kafka protocol dynamically. If new instances join the group they will take over some partitions from other members of the group; if an instance dies, its partitions will be distributed to the remaining instances.
在kafka中实现日志消费的方式, 是把日志分区后分配到不同的消费者实例上, 所以每个实例在某个时间点都是”公平共享”式独占每个分区. 在这个处理过程中, 维持组内的成员是由kafka协议动态决定的, 如果有新的实例加入组中, 则会从组中的其他成员分配一些分区给新成员, 如果某个实例销毁了, 则它负责的分区也会分配给组内的其它成员
Kafka only provides a total order over records within a partition, not between different partitions in a topic. Per-partition ordering combined with the ability to partition data by key is sufficient for most applications. However, if you require a total order over records this can be achieved with a topic that has only one partition, though this will mean only one consumer process per consumer group.
kafka值提供在一个日志分区里面顺序消费的能力, 在同一topic的不同分区里面是没有保证的. 由于记录可以结合键值做分区, 这样的分区顺序一般可以满足各个应用的需求了, 但是如果你要求topic下的所有记录都要按照次序进行消费, 则可以考虑一个topic值创建一个分区, 这样意味着你这个topic只能让一个消费者消费
Guarantees 保障
At a high-level Kafka gives the following guarantees: 在一个高可用能的kafka集群有如下的保证:
- Messages sent by a producer to a particular topic partition will be appended in the order they are sent. That is, if a record M1 is sent by the same producer as a record M2, and M1 is sent first, then M1 will have a lower offset than M2 and appear earlier in the log.
- 被同一个发布者发送到特定的日志分区后, 会按照他们发送的顺序进行添加, 例如 记录M1 和记录M2 都被同一个提供者发送, M1比较早发送, 则M1的位移值比M2小, 并记录在比较早的日志位置
- A consumer instance sees records in the order they are stored in the log.
- 消费者实例按照日志记录的顺序进行读取
- For a topic with replication factor N, we will tolerate up to N-1 server failures without losing any records committed to the log.
- 如果topic有N个副本, 则可以容忍N-1台服务器宕机时, 提交的记录不会丢失
More details on these guarantees are given in the design section of the documentation.
更多关于kafka能提供的特性会在设计这个章节讲到
Kafka as a Messaging System kafka当作消息系统
How does Kafka’s notion of streams compare to a traditional enterprise messaging system?
kafka的流概念和传统的企业消息系统有什么不一样呢?
Messaging traditionally has two models: queuing and publish-subscribe. In a queue, a pool of consumers may read from a server and each record goes to one of them; in publish-subscribe the record is broadcast to all consumers. Each of these two models has a strength and a weakness. The strength of queuing is that it allows you to divide up the processing of data over multiple consumer instances, which lets you scale your processing. Unfortunately, queues aren’t multi-subscriber—once one process reads the data it’s gone. Publish-subscribe allows you broadcast data to multiple processes, but has no way of scaling processing since every message goes to every subscriber.
传统的消息系统有两种模型, 队列模型和发布订阅模型, 在订阅模型中, 一群消费者从服务器读取记录, 每条记录会分发到其中一个消费者中, 在发布和订阅模型中, 记录分发给所有的消费者. 这两种模型都有各自的优缺点, 队列的优点是它允许你把数据处理提交到多个消费者实例中, 适用于数据处理的水平扩展, 但是队列不是多订阅的, 一旦其中的一个消费者读取了记录, 则记录就算处理过了. 在发布订阅模型中允许你广播到记录到不同的订阅者上, 但是这种方式没法对不同的订阅者进行负载均摊
The consumer group concept in Kafka generalizes these two concepts. As with a queue the consumer group allows you to divide up processing over a collection of processes (the members of the consumer group). As with publish-subscribe, Kafka allows you to broadcast messages to multiple consumer groups.
kafka的消费组产生源于对着两种概念的融合,在队列模型中, 它允许你把记录分摊在同一个消费组的不同处理者身上, 在订阅和发布模型中, 它允许你把消费广播到不同的消费组中
The advantage of Kafka’s model is that every topic has both these properties—it can scale processing and is also multi-subscriber—there is no need to choose one or the other.
kafka这个模型的好处是, 这样每个topic都能同时拥有这样的属性, 既能消费者有水平扩展的处理能力, 又能允许有多个不同的订阅者–不需要让用户选择到底是要使用队列模型还是发布订阅模型
Kafka has stronger ordering guarantees than a traditional messaging system, too.
Kafka也比传统的消息系统有更强的消息顺序保证
A traditional queue retains records in-order on the server, and if multiple consumers consume from the queue then the server hands out records in the order they are stored. However, although the server hands out records in order, the records are delivered asynchronously to consumers, so they may arrive out of order on different consumers. This effectively means the ordering of the records is lost in the presence of parallel consumption. Messaging systems often work around this by having a notion of “exclusive consumer” that allows only one process to consume from a queue, but of course this means that there is no parallelism in processing.
传统的队列在服务器端按顺序保存记录, 如果有多个消费者同时从服务器端读取数据, 则服务器按保存的顺序分发记录. 但是尽管服务器按顺序分发记录, 这些记录使用异步分发到消费者上, 所以记录到不同的消费者时顺序可能是不一致的. 这就是说记录的顺序有可能在记录被并发消费时已经被丢失了, 在消息系统中为了支持顺序消费这种情况经常使用一个概念叫做”独占消费者”, 表示只允许一个消费者去订阅队列, 这也意味了牺牲掉记录并行处理能力
Kafka does it better. By having a notion of parallelism—the partition—within the topics, Kafka is able to provide both ordering guarantees and load balancing over a pool of consumer processes. This is achieved by assigning the partitions in the topic to the consumers in the consumer group so that each partition is consumed by exactly one consumer in the group. By doing this we ensure that the consumer is the only reader of that partition and consumes the data in order. Since there are many partitions this still balances the load over many consumer instances. Note however that there cannot be more consumer instances in a consumer group than partitions.
kafka在这点上做得更好些, 通过对日志提出分区的概念, kafka保证了记录处理的顺序和对一组消费者实例进行负载分摊的水平扩展能力. 通过把topic中的分区唯一指定消费者分组中的某个消费者, 这样可以保证仅且只有这样的一个消费者实例从这个分区读取数据, 并按顺序进行消费. 这样topic中的多个分区就可以分摊到多个消费者实例上, 当然消费者的数量不能比分区数量多, 否则有些消费者将分配不到分区.
Kafka as a Storage System kafka当作储存系统
Any message queue that allows publishing messages decoupled from consuming them is effectively acting as a storage system for the in-flight messages. What is different about Kafka is that it is a very good storage system.
作为存储系统, 任意消息队列都允许发布到消息队列中, 并能高效消费这些消息记录, kafka不同的地方是它是一个很好的存储系统
Data written to Kafka is written to disk and replicated for fault-tolerance. Kafka allows producers to wait on acknowledgement so that a write isn’t considered complete until it is fully replicated and guaranteed to persist even if the server written to fails.
数据写入kafka时被写入到磁盘, 并复制到其他服务器上进行容错, kafka允许生产者只有在消息已经复制完, 并存储后才得到写成功的通知, 否则就认为失败.
The disk structures Kafka uses scale well—Kafka will perform the same whether you have 50 KB or 50 TB of persistent data on the server.
磁盘结构kafka也很有效率利用了–无论你存储的是50KB或50TB的数据在kafka上, kafka都会有同样的性能
As a result of taking storage seriously and allowing the clients to control their read position, you can think of Kafka as a kind of special purpose distributed filesystem dedicated to high-performance, low-latency commit log storage, replication, and propagation.
对于那些需要认真考虑存储性能, 并允许客户端自主控制读取位置的, 你可以把kafka当作是一种特殊的分布式文件系统, 并致力于高性能, 低延迟提交日志存储, 复制和传播.
Kafka for Stream Processing kafka作为数据流处理
It isn’t enough to just read, write, and store streams of data, the purpose is to enable real-time processing of streams.
仅仅读取、写入和存储数据流是不够的,最终的目的是使流实时处理.。
In Kafka a stream processor is anything that takes continual streams of data from input topics, performs some processing on this input, and produces continual streams of data to output topics.
kafka的流数据处理器是持续从输入的topic读取连续的数据流, 进行数据处理, 转换, 后产生连续的数据流输出到topic中
For example, a retail application might take in input streams of sales and shipments, and output a stream of reorders and price adjustments computed off this data.
例如,一个零售的应用可能需要在获取销售和出货量的输入流, 在计算分析了之后, 重新输出价格调整的记录
It is possible to do simple processing directly using the producer and consumer APIs. However for more complex transformations Kafka provides a fully integrated Streams API. This allows building applications that do non-trivial processing that compute aggregations off of streams or join streams together.
通常情况下可以直接使用提供者或消费者的api方法做些简单的处理. 但是kafka通过stream api 也提供一些更复杂的数据转换处理机制, stream api可以让应用计算流的聚合或流的归
This facility helps solve the hard problems this type of application faces: handling out-of-order data, reprocessing input as code changes, performing stateful computations, etc.
这些功能有助于解决一些应用上的难题: 处理无序的数据, 在编码修改后从新处理输入数据, 执行有状态的计算等
The streams API builds on the core primitives Kafka provides: it uses the producer and consumer APIs for input, uses Kafka for stateful storage, and uses the same group mechanism for fault tolerance among the stream processor instances.
流的api基于kafka的核心基本功能上构建的: 它使用生产者和消费者提供的api作为输入输出, 使用kafka作为状态存储, 使用一样的分组机制在不同的流处理器上进行容错
Putting the Pieces Together 把各个块整合起来
This combination of messaging, storage, and stream processing may seem unusual but it is essential to Kafka’s role as a streaming platform.
组合消息, 存储, 流处理这些看起来不太平常, 但是这些仍然是kafka的作流处理平台的主要功能
A distributed file system like HDFS allows storing static files for batch processing. Effectively a system like this allows storing and processing historical data from the past.
像hdfs分布式文件处理系统, 允许存储静态数据用于批处理, 能使得系统在处理和分析过往的历史数据时更为有效
A traditional enterprise messaging system allows processing future messages that will arrive after you subscribe. Applications built in this way process future data as it arrives.
像传统的消息系统, 允许处理在你订阅之前的信息, 像这样的应用可以处理之前到达的数据
Kafka combines both of these capabilities, and the combination is critical both for Kafka usage as a platform for streaming applications as well as for streaming data pipelines.
kafka整合和所有这些功能, 这些组合包括把kafka平台当作一个流处理应用, 或者是作为流处理的管道
By combining storage and low-latency subscriptions, streaming applications can treat both past and future data the same way. That is a single application can process historical, stored data but rather than ending when it reaches the last record it can keep processing as future data arrives. This is a generalized notion of stream processing that subsumes batch processing as well as message-driven applications.
通过组合数据存储和低订阅开销, 流处理应用可以平等对待之前到达记录或即将到达的记录, 这就是一个应用可以处理历史存储的数据, 也可以在读到最后记录后, 保持等待未来的数据进行处理. 这是流处理,包括批处理以及消息驱动的应用的一个广义的概念
Likewise for streaming data pipelines the combination of subscription to real-time events make it possible to use Kafka for very low-latency pipelines; but the ability to store data reliably make it possible to use it for critical data where the delivery of data must be guaranteed or for integration with offline systems that load data only periodically or may go down for extended periods of time for maintenance. The stream processing facilities make it possible to transform data as it arrives.
同样的像流处理管道, 使用kafka在实时事件系统能实现比较低的延迟管道; 在kafka的存储能力, 使得一些离线系统, 如定时加载数据, 或者维护宕机时数据分发能力更有保障性. 流处理功能在数据到达时进行数据转换处理
For more information on the guarantees, apis, and capabilities Kafka provides see the rest of the documentation.
更多关于kafka提供的功能, 服务和api, 可以查看后文
1.2 Use Cases 用例
Here is a description of a few of the popular use cases for Apache Kafka™. For an overview of a number of these areas in action, see this blog post.
这里提供者一些常用的Kafak使用场景, 更多这些领域的详细说明可以参考这里, this blog post.
Messaging 消息通讯
Kafka works well as a replacement for a more traditional message broker. Message brokers are used for a variety of reasons (to decouple processing from data producers, to buffer unprocessed messages, etc). In comparison to most messaging systems Kafka has better throughput, built-in partitioning, replication, and fault-tolerance which makes it a good solution for large scale message processing applications.
Kafka 可以很好替代传统的消息服务器, 消息服务器的使用有多方面的原因(比如, 可以从生产者上解耦出数据处理, 缓冲未处理的数据), 相比其它消息系统, kafka有更好的吞吐量, 分区机制, 复制和容错能力, 更能适用于大规模的在线数据处理
In our experience messaging uses are often comparatively low-throughput, but may require low end-to-end latency and often depend on the strong durability guarantees Kafka provides.
从经验来看, 消息系统一般吞吐量都比较小, 更多的是要求更低的端到端的延迟, 这些功能都可以依赖于kafka的高可保障
In this domain Kafka is comparable to traditional messaging systems such as ActiveMQ or RabbitMQ.
在这个领域上, kafka可以类比于传统的消息系统, 如: ActiveMQ or RabbitMQ.
Website Activity Tracking 网页日志跟踪
The original use case for Kafka was to be able to rebuild a user activity tracking pipeline as a set of real-time publish-subscribe feeds. This means site activity (page views, searches, or other actions users may take) is published to central topics with one topic per activity type. These feeds are available for subscription for a range of use cases including real-time processing, real-time monitoring, and loading into Hadoop or offline data warehousing systems for offline processing and reporting.
kafka最通常一种使用方式是通过构建用户活动跟踪管道作为实时发布和订阅反馈队列. 页面操作(查看, 检索或任何用户操作)都可以按活动类型发送的不同的topic上, 这些反馈信息, 有助于构建一个实时处理, 实时监控, 或加载到hadoop集群, 构建数据仓库用于离线处理和分析
Activity tracking is often very high volume as many activity messages are generated for each user page view.
由于每个用户页面访问都要记录, 活动日志跟踪一般会有大量的访问消息被记录
Metrics 度量
Kafka is often used for operational monitoring data. This involves aggregating statistics from distributed applications to produce centralized feeds of operational data.
Kafak还经常用于运行监控数据的存储, 这涉及到对分布式应用的运行数的及时汇总统计
Log Aggregation 日志汇聚
Many people use Kafka as a replacement for a log aggregation solution. Log aggregation typically collects physical log files off servers and puts them in a central place (a file server or HDFS perhaps) for processing. Kafka abstracts away the details of files and gives a cleaner abstraction of log or event data as a stream of messages. This allows for lower-latency processing and easier support for multiple data sources and distributed data consumption. In comparison to log-centric systems like Scribe or Flume, Kafka offers equally good performance, stronger durability guarantees due to replication, and much lower end-to-end latency.
很多人使用kafka作为日志汇总的替代品. 典型的情况下, 日志汇总从物理机上采集回来并忖道中央存储中心(如hdfs分布式文件系统)后等待处理, kafka将文件的细节抽象出来,并将日志或事件数据清理和转换成消息流. 这方便与地延迟的数据处理, 更容易支持多个数据源, 和分布式的数据消费. 比起典型的日志中心系统如Scribe或者flume 系统, kafka提供等同更好的性能, 更强大的复制保证和更低的端到端的延迟
Stream Processing 流处理
Many users of Kafka process data in processing pipelines consisting of multiple stages, where raw input data is consumed from Kafka topics and then aggregated, enriched, or otherwise transformed into new topics for further consumption or follow-up processing. For example, a processing pipeline for recommending news articles might crawl article content from RSS feeds and publish it to an “articles” topic; further processing might normalize or deduplicate this content and published the cleansed article content to a new topic; a final processing stage might attempt to recommend this content to users. Such processing pipelines create graphs of real-time data flows based on the individual topics. Starting in 0.10.0.0, a light-weight but powerful stream processing library called Kafka Streams is available in Apache Kafka to perform such data processing as described above. Apart from Kafka Streams, alternative open source stream processing tools include Apache Storm and Apache Samza.
更多的kafka用户在处理数据时一般都是多流程多步骤的, 原始数据从kafka的topic里面被读取, 然后汇总, 分析 然后转换到新的topic中进行后续的消费处理. 例如, 文章推荐处理管道肯能从RSS feeds里面抓取文章内容, 然后发布到文章这个topic中, 后面在继续规范化处理,除去重复后发布到另外一个新的topic中去, 一个最终的步骤可能是把文章内容推荐给用户, 像这样的实时系统流数据处理管道基于各个独立的topic, 从0.10.0.0开始, kafak提供一个轻量级, 但是非常强大的流处理api叫做 Kafka Streams , 可以处理上述描述的任务情景. 除了kafka的流机制外, 可选择开源项目有e Apache Storm 和 Apache Samza.
Event Sourcing 事件源
Event sourcing is a style of application design where state changes are logged as a time-ordered sequence of records. Kafka’s support for very large stored log data makes it an excellent backend for an application built in this style.
时间记录是应用在状态变化时按时间顺序依次记录状态变化日志的一种设计风格. kafka很适合作为这种风格的后端服务器
Commit Log 提交日志
Kafka can serve as a kind of external commit-log for a distributed system. The log helps replicate data between nodes and acts as a re-syncing mechanism for failed nodes to restore their data. The log compaction feature in Kafka helps support this usage. In this usage Kafka is similar to Apache BookKeeperproject.
Kafka适用于分布式系统的外部提交日志, 这些日志方便于在节点间进行复制, 并在服务器故障是提供重新同步机能. kafka的日志压缩特性有利于这方面的使用, 这个特性有点儿像Apache BookKeeper 这个项目
1.3 Quick Start 快速开始
This tutorial assumes you are starting fresh and have no existing Kafka™ or ZooKeeper data. Since Kafka console scripts are different for Unix-based and Windows platforms, on Windows platforms use bin\windows\ instead of bin/, and change the script extension to .bat.
该入门指南假定你对kafka和zookeeper是个新手, kafka的控制台脚步window和unix系统不一样, 如果在window系统, 请使用 bin\windows\目录下的脚本, 而不是使用bin/, 下的脚本
Step 1: Download the code
Download the 0.10.1.0 release and un-tar it. 下载 0.10.1.0 版本并解压
> tar -xzf kafka_2.11-0.10.1.0.tgz > cd kafka_2.11-0.10.1.0
Step 2: Start the server
Kafka uses ZooKeeper so you need to first start a ZooKeeper server if you don’t already have one. You can use the convenience script packaged with kafka to get a quick-and-dirty single-node ZooKeeper instance.
由于kafka使用ZooKeepe服务器, 如果你没有zookeeper服务器需要先启动一个, 你可以使用kafka已经打包好的快捷脚本用于创建一个单个节点的zookeeper实例
> bin/zookeeper-server-start.sh config/zookeeper.properties [2013-04-22 15:01:37,495] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig) ...
Now start the Kafka server: 现在可以启动kafka服务器
> bin/kafka-server-start.sh config/server.properties [2013-04-22 15:01:47,028] INFO Verifying properties (kafka.utils.VerifiableProperties) [2013-04-22 15:01:47,051] INFO Property socket.send.buffer.bytes is overridden to 1048576 (kafka.utils.VerifiableProperties) ...
Step 3: Create a topic
Let’s create a topic named “test” with a single partition and only one replica: 创建一个只有一个分区和一个副本的topic叫做”test”,
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
We can now see that topic if we run the list topic command: 如果使用查看topic查看命令, 我们就可以看到所有topic列表
> bin/kafka-topics.sh --list --zookeeper localhost:2181 test
Alternatively, instead of manually creating topics you can also configure your brokers to auto-create topics when a non-existent topic is published to.
还有一种可选的方式, 如果不想手动创建topic, 你可以配置服务器在消息发时, 自动创建topic对象
Step 4: Send some messages
Kafka comes with a command line client that will take input from a file or from standard input and send it out as messages to the Kafka cluster. By default, each line will be sent as a separate message.
kafka自带的命令行终端脚本, 可以从文件或标准输入读取行输入, 并发送消息到kafka集群, 默认每行数据当作一条独立的消息进行发送
Run the producer and then type a few messages into the console to send to the server.
运行发布者终端脚步, 然后从终端输入一些消息后发送到服务器
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test This is a message This is another message
Step 5: Start a consumer
Kafka also has a command line consumer that will dump out messages to standard output.
kafka也自带一个消费者命令行终端脚本, 可以把消息打印到终端上
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning This is a message This is another message
If you have each of the above commands running in a different terminal then you should now be able to type messages into the producer terminal and see them appear in the consumer terminal.
如果上面的两个命令跑在不同的终端上, 则从提供者终端输入消息, 会在消费者终端展现出来
All of the command line tools have additional options; running the command with no arguments will display usage information documenting them in more detail.
上面的命令都需要而外的命令行参数, 如果只输入命令不带任何参数, 则会提示更多关于该命令的使用说明
Step 6: Setting up a multi-broker cluster
So far we have been running against a single broker, but that’s no fun. For Kafka, a single broker is just a cluster of size one, so nothing much changes other than starting a few more broker instances. But just to get feel for it, let’s expand our cluster to three nodes (still all on our local machine).
到现在为止, 我们只跑了当个服务器实例, 但是这个不好玩, 对于kafka来说, 单个服务器实例意味着这个集群只有一个成员, 如果要启动多个实例也不需要做太多的变化. 现在来感受下, 把我们的集群扩展到3个机器(在同一台物理机上)
First we make a config file for each of the brokers (on Windows use the copy command instead):
所需我们给每个不同的服务器复制一份不同的配置文件
> cp config/server.properties config/server-1.properties > cp config/server.properties config/server-2.properties
Now edit these new files and set the following properties:现在重新配置这些新的文件
config/server-1.properties:
broker.id=1
listeners=PLAINTEXT://:9093
log.dir=/tmp/kafka-logs-1
config/server-2.properties:
broker.id=2
listeners=PLAINTEXT://:9094
log.dir=/tmp/kafka-logs-2
The broker.id property is the unique and permanent name of each node in the cluster. We have to override the port and log directory only because we are running these all on the same machine and we want to keep the brokers from all trying to register on the same port or overwrite each other’s data.
broker.id 属性对于集群中的每个服务器实例都必须是唯一的且不变的, 我们重新了端口号和日志目录, 是因为我们实例都是跑在同一台物理机器上, 需要使用不同的端口和目录来防止冲突
We already have Zookeeper and our single node started, so we just need to start the two new nodes:
我们已经有了Zookeeper服务器, 而且已经有启动一个实例, 现在我们再启动2个实例
> bin/kafka-server-start.sh config/server-1.properties & ... > bin/kafka-server-start.sh config/server-2.properties & ...
Now create a new topic with a replication factor of three: 现在可以创建一个topic包含3个副本
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic
Okay but now that we have a cluster how can we know which broker is doing what? To see that run the “describe topics” command:
Ok, 现在如果我们怎么知道那个实例在负责什么? 可以通过 “describe topics”命令查看
> bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs: Topic: my-replicated-topic Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
Here is an explanation of output. The first line gives a summary of all the partitions, each additional line gives information about one partition. Since we have only one partition for this topic there is only one line.
这里解析下输出信息, 第一行是所有的分区汇总, 每行分区的详细信息, 因为我们只有一个分区, 所以只有一行
- “leader” is the node responsible for all reads and writes for the given partition. Each node will be the leader for a randomly selected portion of the partitions.
- “leader”表示这个实例负责响应指定分区的读写请求, 每个实例都有可能被随机选择为部分分区的leader负责人
- “replicas” is the list of nodes that replicate the log for this partition regardless of whether they are the leader or even if they are currently alive.
- “replicas” 表示当前分区分发的所有副本所在的所有实例列表, 不管这个实例是否有存活
- “isr” is the set of “in-sync” replicas. This is the subset of the replicas list that is currently alive and caught-up to the leader.
- “isr” 表示存储当前分区的日志都已经同步到leader的服务器的实例集合
Note that in my example node 1 is the leader for the only partition of the topic. 注意我这个例子只有实例1是主服务器, 因为topic只有一个分区
We can run the same command on the original topic we created to see where it is: 我们可以运行同样的命令在原来创建的topic上
> bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test Topic:test PartitionCount:1 ReplicationFactor:1 Configs: Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
So there is no surprise there—the original topic has no replicas and is on server 0, the only server in our cluster when we created it.
意料之中, 原来的topic没有副本, 而且由实例0负责, 实例0是我们集群最初创建时的唯一实例
Let’s publish a few messages to our new topic: 我们发布点消息到新的主题上
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my-replicated-topic ... my test message 1 my test message 2 ^C
Now let’s consume these messages: 现在我们开始消费这些消息
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic my-replicated-topic ... my test message 1 my test message 2 ^C
Now let’s test out fault-tolerance. Broker 1 was acting as the leader so let’s kill it: 现在,让我们测试下容错能力, 实例1现在是主服务器, 我们现在把它kill掉
> ps aux | grep server-1.properties 7564 ttys002 0:15.91 /System/Library/Frameworks/JavaVM.framework/Versions/1.8/Home/bin/java... > kill -9 7564
On Windows use:
> wmic process get processid,caption,commandline | find "java.exe" | find "server-1.properties" java.exe java -Xmx1G -Xms1G -server -XX:+UseG1GC ... build\libs\kafka_2.10-0.10.1.0.jar" kafka.Kafka config\server-1.properties 644 > taskkill /pid 644 /f
Leadership has switched to one of the slaves and node 1 is no longer in the in-sync replica set: 主服务器切换到原来的两个从服务器里面, 原来的实例1也不在同步副本里面了
> bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs: Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 1,2,0 Isr: 2,0
But the messages are still available for consumption even though the leader that took the writes originally is down: 但是消息还是可以消费, 尽管原来接受消息的主服务器已经宕机了
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic my-replicated-topic ... my test message 1 my test message 2 ^C
Step 7: Use Kafka Connect to import/export data
Writing data from the console and writing it back to the console is a convenient place to start, but you’ll probably want to use data from other sources or export data from Kafka to other systems. For many systems, instead of writing custom integration code you can use Kafka Connect to import or export data.
从控制太写入和读取数据方便大家开始学习, 但是你可能需要从其他系统导入到kafka或从kafka导出数据到其它系统. 对于很多系统, 你不需要写写特定的整合代码, 只需要使用Kafka Connect提供的功能进行导入导出
Kafka Connect is a tool included with Kafka that imports and exports data to Kafka. It is an extensible tool that runs connectors, which implement the custom logic for interacting with an external system. In this quickstart we’ll see how to run Kafka Connect with simple connectors that import data from a file to a Kafka topic and export data from a Kafka topic to a file.
Kafka Connect工具包含数据的导入和导出, 它可以是一个外部工具connectors, 和外部系统交互实现特定的业务逻辑后. 在下面的例子中我们会看到一个简单的连接器, 从文件中读取数据写入到kafka, 和从kafka的topic中导出数据到文件中去
First, we’ll start by creating some seed data to test with:
首先, 我们先创建一些随机的测试数据
> echo -e "foo\nbar" > test.txt
Next, we’ll start two connectors running in standalone mode, which means they run in a single, local, dedicated process. We provide three configuration files as parameters. The first is always the configuration for the Kafka Connect process, containing common configuration such as the Kafka brokers to connect to and the serialization format for data. The remaining configuration files each specify a connector to create. These files include a unique connector name, the connector class to instantiate, and any other configuration required by the connector.
接下来, 我们启动两个独立连接器, 这意味着它们以单一的,本地的,专用的进程进行运行. 我们以参数的形式提供三个配置文件, 第一个参数是kafka连接器常用的一些配置, 包含kafka连接的服务器器地址, 数据的序列化格式等. 剩下的配置文件各自包含一个要创建的连接器, 这些文件包含一个唯一的连接器名称, 连接器对于的启动类, 还任何连接器需要的其他配置信息
> bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties config/connect-file-sink.properties
These sample configuration files, included with Kafka, use the default local cluster configuration you started earlier and create two connectors: the first is a source connector that reads lines from an input file and produces each to a Kafka topic and the second is a sink connector that reads messages from a Kafka topic and produces each as a line in an output file.
在这些样例包含kafka之前启动的默认本地的集群, 和启动两个连接器, 第一个输入连接器负责从一个文件按行读取数据, 并发布到kafka的topic上去, 第二个是一个输入连接器, 负责从kafka的topic中读取数据, 并按行输出到文件中
During startup you’ll see a number of log messages, including some indicating that the connectors are being instantiated. Once the Kafka Connect process has started, the source connector should start reading lines from test.txt and producing them to the topic connect-test, and the sink connector should start reading messages from the topic connect-test and write them to the file test.sink.txt. We can verify the data has been delivered through the entire pipeline by examining the contents of the output file:
在启动的时候, 你会看到一些日志信息, 包括连接器初始化的启动信息. 一旦kafka连接器启动起来, 源连接器从test.txt 文件中读取行记录, 并发布到connect-test的主题中, 输出连接器开始从connect-test主题中读取数据, 并写入到 test.sink.txt 文件中, 我们可以根据输出文件的内容, 检测这个管道的数据传送是否正常
> cat test.sink.txt foo bar
Note that the data is being stored in the Kafka topic connect-test, so we can also run a console consumer to see the data in the topic (or use custom consumer code to process it):
现在数据已经保存到connect-test主题中, 所以, 我们可以跑一个终端消费者来查看主题中的数据(或者编写特定的消费进行处理)
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic connect-test --from-beginning
{"schema":{"type":"string","optional":false},"payload":"foo"}
{"schema":{"type":"string","optional":false},"payload":"bar"}
...
The connectors continue to process data, so we can add data to the file and see it move through the pipeline:
连接器持续在处理数据, 所以我们可以把数据写入到文件中, 查看到数据是否通过这个管道处理
> echo "Another line" >> test.txt
You should see the line appear in the console consumer output and in the sink file.
你可以看到那些从消费者终端输入的行, 都会写入到输出文件中
Step 8: Use Kafka Streams to process data
Kafka Streams is a client library of Kafka for real-time stream processing and analyzing data stored in Kafka brokers. This quickstart example will demonstrate how to run a streaming application coded in this library. Here is the gist of the WordCountDemo example code (converted to use Java 8 lambda expressions for easy reading).
Kafka Streams 是kafka提供用于对存储到kafka服务器中的数据进行实时分析和数据处理的库. 这里展示了怎么使用该库进行流处理的一个样例, 这里是提供了WorkCountDemo样例的部分代码(为了方便阅读使用java 8 lambda表达式方式)
KTable wordCounts = textLines
// Split each text line, by whitespace, into words.
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
// Ensure the words are available as record keys for the next aggregate operation.
.map((key, value) -> new KeyValue<>(value, value))
// Count the occurrences of each word (record key) and store the results into a table named "Counts".
.countByKey("Counts")
It implements the WordCount algorithm, which computes a word occurrence histogram from the input text. However, unlike other WordCount examples you might have seen before that operate on bounded data, the WordCount demo application behaves slightly differently because it is designed to operate on an infinite, unbounded stream of data. Similar to the bounded variant, it is a stateful algorithm that tracks and updates the counts of words. However, since it must assume potentially unbounded input data, it will periodically output its current state and results while continuing to process more data because it cannot know when it has processed “all” the input data.
这里实现从输入文本中统计单词出现次数的算法. 和其他的有限输入的单词计数算法不一样, 这个样例有点不一样, 因为它的输入流是无限, 没有边界的数据流数据, 类似有边界的输入, 这里包含有状态的算法用于跟踪和更新单词技术. 当然, 由于处理的数据是没有边界的, 处理程序并不知道什么时候已经处理完全部的输入数据, 因此, 它在处理数据的同时, 并定时输出当前的状态和结果,
We will now prepare input data to a Kafka topic, which will subsequently be processed by a Kafka Streams application.
我们现在为流处理应用准备点数据到kafka的主题中
> echo -e "all streams lead to kafka\nhello kafka streams\njoin kafka summit" > file-input.txt
Or on Windows:
> echo all streams lead to kafka> file-input.txt > echo hello kafka streams>> file-input.txt > echo|set /p=join kafka summit>> file-input.txt
Next, we send this input data to the input topic named streams-file-input using the console producer (in practice, stream data will likely be flowing continuously into Kafka where the application will be up and running):
接下来, 我们使用终端生产者把数据输入到streams-file-input主题中(实际生产中, 在应用启动时, 流数据将会持续输入到kafka中)
> bin/kafka-topics.sh --create \
--zookeeper localhost:2181 \
--replication-factor 1 \
--partitions 1 \
--topic streams-file-input
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic streams-file-input < file-input.txt
We can now run the WordCount demo application to process the input data: 现在我们跑下WordCount 样例来处理这些数据.
> bin/kafka-run-class.sh org.apache.kafka.streams.examples.wordcount.WordCountDemo
There won’t be any STDOUT output except log entries as the results are continuously written back into another topic named streams-wordcount-output in Kafka. The demo will run for a few seconds and then, unlike typical stream processing applications, terminate automatically.
We can now inspect the output of the WordCount demo application by reading from its output topic:
这里不会有任何日志输出到标准输出, 然后, 有持续的结果输出到kafka另外一个主题叫做 streams-wordcount-output , 和其它的流处理系统不一样, 样例只会跑几秒钟然后自动停止了. 我们可以从输出主题中读取数据来检测WordCount样例的数据处理结果.
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic streams-wordcount-output \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
with the following output data being printed to the console: 将会有如下的数据输出到控制台上
all 1 lead 1 to 1 hello 1 streams 2 join 1 kafka 3 summit 1
Here, the first column is the Kafka message key, and the second column is the message value, both in in java.lang.String format. Note that the output is actually a continuous stream of updates, where each data record (i.e. each line in the original output above) is an updated count of a single word, aka record key such as “kafka”. For multiple records with the same key, each later record is an update of the previous one.
这里, 第一栏是kafka消息的键值, 第二栏是消息值, 都是使用java.lang.String的格式, 注意, 输出实际是上持续数据流的更新, 每条记录都是对每个单词的持续更新计数, 比如 “kafka”这个单词的记录. 如果多条记录有相同的键, 则每条记录都会更新计数器.
Now you can write more input messages to the streams-file-input topic and observe additional messages added to streams-wordcount-output topic, reflecting updated word counts (e.g., using the console producer and the console consumer, as described above).
You can stop the console consumer via Ctrl-C.
现在, 你可以写入更多的消息到streams-file-input 主题中, 然后观察另外输出到streams-wordcount-output主题中的记录中被更新的单词计数(e.g, 使用前面提到的终端生产者和终端消费者)
1.4 Ecosystem
There are a plethora of tools that integrate with Kafka outside the main distribution. The ecosystem page lists many of these, including stream processing systems, Hadoop integration, monitoring, and deployment tools.
在kafka发行的主版本外, 还有大量整合了kafka的工具. 这里 有罗列大量的工具, 包括流的在线处理系统, hadoop整合, 监控 和部署工具
1.5 Upgrading From Previous Versions
Upgrading from 0.8.x, 0.9.x or 0.10.0.X to 0.10.1.0
0.10.1.0 has wire protocol changes. By following the recommended rolling upgrade plan below, you guarantee no downtime during the upgrade. However, please notice the Potential breaking changes in 0.10.1.0 before upgrade.
Note: Because new protocols are introduced, it is important to upgrade your Kafka clusters before upgrading your clients (i.e. 0.10.1.x clients only support 0.10.1.x or later brokers while 0.10.1.x brokers also support older clients).
For a rolling upgrade:
- Update server.properties file on all brokers and add the following properties:
- inter.broker.protocol.version=CURRENT_KAFKA_VERSION (e.g. 0.8.2.0, 0.9.0.0 or 0.10.0.0).
- log.message.format.version=CURRENT_KAFKA_VERSION (See potential performance impact following the upgrade for the details on what this configuration does.)
- Upgrade the brokers one at a time: shut down the broker, update the code, and restart it.
- Once the entire cluster is upgraded, bump the protocol version by editing inter.broker.protocol.version and setting it to 0.10.1.0.
- If your previous message format is 0.10.0, change log.message.format.version to 0.10.1 (this is a no-op as the message format is the same for both 0.10.0 and 0.10.1). If your previous message format version is lower than 0.10.0, do not change log.message.format.version yet – this parameter should only change once all consumers have been upgraded to 0.10.0.0 or later.
- Restart the brokers one by one for the new protocol version to take effect.
- If log.message.format.version is still lower than 0.10.0 at this point, wait until all consumers have been upgraded to 0.10.0 or later, then change log.message.format.version to 0.10.1 on each broker and restart them one by one.
Note: If you are willing to accept downtime, you can simply take all the brokers down, update the code and start all of them. They will start with the new protocol by default.
Note: Bumping the protocol version and restarting can be done any time after the brokers were upgraded. It does not have to be immediately after.
Potential breaking changes in 0.10.1.0
- The log retention time is no longer based on last modified time of the log segments. Instead it will be based on the largest timestamp of the messages in a log segment.
- The log rolling time is no longer depending on log segment create time. Instead it is now based on the timestamp in the messages. More specifically. if the timestamp of the first message in the segment is T, the log will be rolled out when a new message has a timestamp greater than or equal to T + log.roll.ms
- The open file handlers of 0.10.0 will increase by ~33% because of the addition of time index files for each segment.
- The time index and offset index share the same index size configuration. Since each time index entry is 1.5x the size of offset index entry. User may need to increase log.index.size.max.bytes to avoid potential frequent log rolling.
- Due to the increased number of index files, on some brokers with large amount the log segments (e.g. >15K), the log loading process during the broker startup could be longer. Based on our experiment, setting the num.recovery.threads.per.data.dir to one may reduce the log loading time.
Notable changes in 0.10.1.0
- The new Java consumer is no longer in beta and we recommend it for all new development. The old Scala consumers are still supported, but they will be deprecated in the next release and will be removed in a future major release.
- The
--new-consumer/--new.consumerswitch is no longer required to use tools like MirrorMaker and the Console Consumer with the new consumer; one simply needs to pass a Kafka broker to connect to instead of the ZooKeeper ensemble. In addition, usage of the Console Consumer with the old consumer has been deprecated and it will be removed in a future major release. - Kafka clusters can now be uniquely identified by a cluster id. It will be automatically generated when a broker is upgraded to 0.10.1.0. The cluster id is available via the kafka.server:type=KafkaServer,name=ClusterId metric and it is part of the Metadata response. Serializers, client interceptors and metric reporters can receive the cluster id by implementing the ClusterResourceListener interface.
- The BrokerState “RunningAsController” (value 4) has been removed. Due to a bug, a broker would only be in this state briefly before transitioning out of it and hence the impact of the removal should be minimal. The recommended way to detect if a given broker is the controller is via the kafka.controller:type=KafkaController,name=ActiveControllerCount metric.
- The new Java Consumer now allows users to search offsets by timestamp on partitions.
- The new Java Consumer now supports heartbeating from a background thread. There is a new configuration
max.poll.interval.mswhich controls the maximum time between poll invocations before the consumer will proactively leave the group (5 minutes by default). The value of the configurationrequest.timeout.msmust always be larger thanmax.poll.interval.msbecause this is the maximum time that a JoinGroup request can block on the server while the consumer is rebalancing, so we have changed its default value to just above 5 minutes. Finally, the default value ofsession.timeout.mshas been adjusted down to 10 seconds, and the default value ofmax.poll.recordshas been changed to 500. - When using an Authorizer and a user doesn’t have Describe authorization on a topic, the broker will no longer return TOPIC_AUTHORIZATION_FAILED errors to requests since this leaks topic names. Instead, the UNKNOWN_TOPIC_OR_PARTITION error code will be returned. This may cause unexpected timeouts or delays when using the producer and consumer since Kafka clients will typically retry automatically on unknown topic errors. You should consult the client logs if you suspect this could be happening.
- Fetch responses have a size limit by default (50 MB for consumers and 10 MB for replication). The existing per partition limits also apply (1 MB for consumers and replication). Note that neither of these limits is an absolute maximum as explained in the next point.
- Consumers and replicas can make progress if a message larger than the response/partition size limit is found. More concretely, if the first message in the first non-empty partition of the fetch is larger than either or both limits, the message will still be returned.
- Overloaded constructors were added to
kafka.api.FetchRequestandkafka.javaapi.FetchRequestto allow the caller to specify the order of the partitions (since order is significant in v3). The previously existing constructors were deprecated and the partitions are shuffled before the request is sent to avoid starvation issues.
New Protocol Versions
- ListOffsetRequest v1 supports accurate offset search based on timestamps.
- MetadataResponse v2 introduces a new field: “cluster_id”.
- FetchRequest v3 supports limiting the response size (in addition to the existing per partition limit), it returns messages bigger than the limits if required to make progress and the order of partitions in the request is now significant.
- JoinGroup v1 introduces a new field: “rebalance_timeout”.
Upgrading from 0.8.x or 0.9.x to 0.10.0.0
0.10.0.0 has potential breaking changes (please review before upgrading) and possible performance impact following the upgrade. By following the recommended rolling upgrade plan below, you guarantee no downtime and no performance impact during and following the upgrade.
Note: Because new protocols are introduced, it is important to upgrade your Kafka clusters before upgrading your clients.
Notes to clients with version 0.9.0.0: Due to a bug introduced in 0.9.0.0, clients that depend on ZooKeeper (old Scala high-level Consumer and MirrorMaker if used with the old consumer) will not work with 0.10.0.x brokers. Therefore, 0.9.0.0 clients should be upgraded to 0.9.0.1 before brokers are upgraded to 0.10.0.x. This step is not necessary for 0.8.X or 0.9.0.1 clients.
For a rolling upgrade:
- Update server.properties file on all brokers and add the following properties:
- inter.broker.protocol.version=CURRENT_KAFKA_VERSION (e.g. 0.8.2 or 0.9.0.0).
- log.message.format.version=CURRENT_KAFKA_VERSION (See potential performance impact following the upgrade for the details on what this configuration does.)
- Upgrade the brokers. This can be done a broker at a time by simply bringing it down, updating the code, and restarting it.
- Once the entire cluster is upgraded, bump the protocol version by editing inter.broker.protocol.version and setting it to 0.10.0.0. NOTE: You shouldn’t touch log.message.format.version yet – this parameter should only change once all consumers have been upgraded to 0.10.0.0
- Restart the brokers one by one for the new protocol version to take effect.
- Once all consumers have been upgraded to 0.10.0, change log.message.format.version to 0.10.0 on each broker and restart them one by one.
Note: If you are willing to accept downtime, you can simply take all the brokers down, update the code and start all of them. They will start with the new protocol by default.
Note: Bumping the protocol version and restarting can be done any time after the brokers were upgraded. It does not have to be immediately after.
Potential performance impact following upgrade to 0.10.0.0
The message format in 0.10.0 includes a new timestamp field and uses relative offsets for compressed messages. The on disk message format can be configured through log.message.format.version in the server.properties file. The default on-disk message format is 0.10.0. If a consumer client is on a version before 0.10.0.0, it only understands message formats before 0.10.0. In this case, the broker is able to convert messages from the 0.10.0 format to an earlier format before sending the response to the consumer on an older version. However, the broker can’t use zero-copy transfer in this case. Reports from the Kafka community on the performance impact have shown CPU utilization going from 20% before to 100% after an upgrade, which forced an immediate upgrade of all clients to bring performance back to normal. To avoid such message conversion before consumers are upgraded to 0.10.0.0, one can set log.message.format.version to 0.8.2 or 0.9.0 when upgrading the broker to 0.10.0.0. This way, the broker can still use zero-copy transfer to send the data to the old consumers. Once consumers are upgraded, one can change the message format to 0.10.0 on the broker and enjoy the new message format that includes new timestamp and improved compression. The conversion is supported to ensure compatibility and can be useful to support a few apps that have not updated to newer clients yet, but is impractical to support all consumer traffic on even an overprovisioned cluster. Therefore, it is critical to avoid the message conversion as much as possible when brokers have been upgraded but the majority of clients have not.
For clients that are upgraded to 0.10.0.0, there is no performance impact.
Note: By setting the message format version, one certifies that all existing messages are on or below that message format version. Otherwise consumers before 0.10.0.0 might break. In particular, after the message format is set to 0.10.0, one should not change it back to an earlier format as it may break consumers on versions before 0.10.0.0.
Note: Due to the additional timestamp introduced in each message, producers sending small messages may see a message throughput degradation because of the increased overhead. Likewise, replication now transmits an additional 8 bytes per message. If you’re running close to the network capacity of your cluster, it’s possible that you’ll overwhelm the network cards and see failures and performance issues due to the overload.
Note: If you have enabled compression on producers, you may notice reduced producer throughput and/or lower compression rate on the broker in some cases. When receiving compressed messages, 0.10.0 brokers avoid recompressing the messages, which in general reduces the latency and improves the throughput. In certain cases, however, this may reduce the batching size on the producer, which could lead to worse throughput. If this happens, users can tune linger.ms and batch.size of the producer for better throughput. In addition, the producer buffer used for compressing messages with snappy is smaller than the one used by the broker, which may have a negative impact on the compression ratio for the messages on disk. We intend to make this configurable in a future Kafka release.
Potential breaking changes in 0.10.0.0
- Starting from Kafka 0.10.0.0, the message format version in Kafka is represented as the Kafka version. For example, message format 0.9.0 refers to the highest message version supported by Kafka 0.9.0.
- Message format 0.10.0 has been introduced and it is used by default. It includes a timestamp field in the messages and relative offsets are used for compressed messages.
- ProduceRequest/Response v2 has been introduced and it is used by default to support message format 0.10.0
- FetchRequest/Response v2 has been introduced and it is used by default to support message format 0.10.0
- MessageFormatter interface was changed from
def writeTo(key: Array[Byte], value: Array[Byte], output: PrintStream)todef writeTo(consumerRecord: ConsumerRecord[Array[Byte], Array[Byte]], output: PrintStream) - MessageReader interface was changed from
def readMessage(): KeyedMessage[Array[Byte], Array[Byte]]todef readMessage(): ProducerRecord[Array[Byte], Array[Byte]] - MessageFormatter’s package was changed from
kafka.toolstokafka.common - MessageReader’s package was changed from
kafka.toolstokafka.common - MirrorMakerMessageHandler no longer exposes the
handle(record: MessageAndMetadata[Array[Byte], Array[Byte]])method as it was never called. - The 0.7 KafkaMigrationTool is no longer packaged with Kafka. If you need to migrate from 0.7 to 0.10.0, please migrate to 0.8 first and then follow the documented upgrade process to upgrade from 0.8 to 0.10.0.
- The new consumer has standardized its APIs to accept
java.util.Collectionas the sequence type for method parameters. Existing code may have to be updated to work with the 0.10.0 client library. - LZ4-compressed message handling was changed to use an interoperable framing specification (LZ4f v1.5.1). To maintain compatibility with old clients, this change only applies to Message format 0.10.0 and later. Clients that Produce/Fetch LZ4-compressed messages using v0/v1 (Message format 0.9.0) should continue to use the 0.9.0 framing implementation. Clients that use Produce/Fetch protocols v2 or later should use interoperable LZ4f framing. A list of interoperable LZ4 libraries is available at http://www.lz4.org/
Notable changes in 0.10.0.0
- Starting from Kafka 0.10.0.0, a new client library named Kafka Streams is available for stream processing on data stored in Kafka topics. This new client library only works with 0.10.x and upward versioned brokers due to message format changes mentioned above. For more information please read this section.
- The default value of the configuration parameter
receive.buffer.bytesis now 64K for the new consumer. - The new consumer now exposes the configuration parameter
exclude.internal.topicsto restrict internal topics (such as the consumer offsets topic) from accidentally being included in regular expression subscriptions. By default, it is enabled. - The old Scala producer has been deprecated. Users should migrate their code to the Java producer included in the kafka-clients JAR as soon as possible.
- The new consumer API has been marked stable.
Upgrading from 0.8.0, 0.8.1.X or 0.8.2.X to 0.9.0.0
0.9.0.0 has potential breaking changes (please review before upgrading) and an inter-broker protocol change from previous versions. This means that upgraded brokers and clients may not be compatible with older versions. It is important that you upgrade your Kafka cluster before upgrading your clients. If you are using MirrorMaker downstream clusters should be upgraded first as well.
For a rolling upgrade:
- Update server.properties file on all brokers and add the following property: inter.broker.protocol.version=0.8.2.X
- Upgrade the brokers. This can be done a broker at a time by simply bringing it down, updating the code, and restarting it.
- Once the entire cluster is upgraded, bump the protocol version by editing inter.broker.protocol.version and setting it to 0.9.0.0.
- Restart the brokers one by one for the new protocol version to take effect
Note: If you are willing to accept downtime, you can simply take all the brokers down, update the code and start all of them. They will start with the new protocol by default.
Note: Bumping the protocol version and restarting can be done any time after the brokers were upgraded. It does not have to be immediately after.
Potential breaking changes in 0.9.0.0
- Java 1.6 is no longer supported.
- Scala 2.9 is no longer supported.
- Broker IDs above 1000 are now reserved by default to automatically assigned broker IDs. If your cluster has existing broker IDs above that threshold make sure to increase the reserved.broker.max.id broker configuration property accordingly.
- Configuration parameter replica.lag.max.messages was removed. Partition leaders will no longer consider the number of lagging messages when deciding which replicas are in sync.
- Configuration parameter replica.lag.time.max.ms now refers not just to the time passed since last fetch request from replica, but also to time since the replica last caught up. Replicas that are still fetching messages from leaders but did not catch up to the latest messages in replica.lag.time.max.ms will be considered out of sync.
- Compacted topics no longer accept messages without key and an exception is thrown by the producer if this is attempted. In 0.8.x, a message without key would cause the log compaction thread to subsequently complain and quit (and stop compacting all compacted topics).
- MirrorMaker no longer supports multiple target clusters. As a result it will only accept a single –consumer.config parameter. To mirror multiple source clusters, you will need at least one MirrorMaker instance per source cluster, each with its own consumer configuration.
- Tools packaged under org.apache.kafka.clients.tools.* have been moved to org.apache.kafka.tools.*. All included scripts will still function as usual, only custom code directly importing these classes will be affected.
- The default Kafka JVM performance options (KAFKA_JVM_PERFORMANCE_OPTS) have been changed in kafka-run-class.sh.
- The kafka-topics.sh script (kafka.admin.TopicCommand) now exits with non-zero exit code on failure.
- The kafka-topics.sh script (kafka.admin.TopicCommand) will now print a warning when topic names risk metric collisions due to the use of a ‘.’ or ‘_’ in the topic name, and error in the case of an actual collision.
- The kafka-console-producer.sh script (kafka.tools.ConsoleProducer) will use the Java producer instead of the old Scala producer be default, and users have to specify ‘old-producer’ to use the old producer.
- By default, all command line tools will print all logging messages to stderr instead of stdout.
Notable changes in 0.9.0.1
- The new broker id generation feature can be disabled by setting broker.id.generation.enable to false.
- Configuration parameter log.cleaner.enable is now true by default. This means topics with a cleanup.policy=compact will now be compacted by default, and 128 MB of heap will be allocated to the cleaner process via log.cleaner.dedupe.buffer.size. You may want to review log.cleaner.dedupe.buffer.size and the other log.cleaner configuration values based on your usage of compacted topics.
- Default value of configuration parameter fetch.min.bytes for the new consumer is now 1 by default.
Deprecations in 0.9.0.0
- Altering topic configuration from the kafka-topics.sh script (kafka.admin.TopicCommand) has been deprecated. Going forward, please use the kafka-configs.sh script (kafka.admin.ConfigCommand) for this functionality.
- The kafka-consumer-offset-checker.sh (kafka.tools.ConsumerOffsetChecker) has been deprecated. Going forward, please use kafka-consumer-groups.sh (kafka.admin.ConsumerGroupCommand) for this functionality.
- The kafka.tools.ProducerPerformance class has been deprecated. Going forward, please use org.apache.kafka.tools.ProducerPerformance for this functionality (kafka-producer-perf-test.sh will also be changed to use the new class).
- The producer config block.on.buffer.full has been deprecated and will be removed in future release. Currently its default value has been changed to false. The KafkaProducer will no longer throw BufferExhaustedException but instead will use max.block.ms value to block, after which it will throw a TimeoutException. If block.on.buffer.full property is set to true explicitly, it will set the max.block.ms to Long.MAX_VALUE and metadata.fetch.timeout.ms will not be honoured
Upgrading from 0.8.1 to 0.8.2
0.8.2 is fully compatible with 0.8.1. The upgrade can be done one broker at a time by simply bringing it down, updating the code, and restarting it.
Upgrading from 0.8.0 to 0.8.1
0.8.1 is fully compatible with 0.8. The upgrade can be done one broker at a time by simply bringing it down, updating the code, and restarting it.
Upgrading from 0.7
Release 0.7 is incompatible with newer releases. Major changes were made to the API, ZooKeeper data structures, and protocol, and configuration in order to add replication (Which was missing in 0.7). The upgrade from 0.7 to later versions requires a special tool for migration. This migration can be done without downtime.
原创文章,转载请注明: 转载自并发编程网 – ifeve.com本文链接地址: 《kafka中文手册》-快速开始


 (5 votes, average: 3.40 out of 5)
(5 votes, average: 3.40 out of 5)

暂无评论