Storm入门之第6章一个实际的例子
本文翻译自《Getting Started With Storm》译者:吴京润 编辑:郭蕾 方腾飞
本章要阐述一个典型的网络分析解决方案,而这类问题通常利用Hadoop批处理作为解决方案。与Hadoop不同的是,基于Storm的方案会实时输出结果。
我们的这个例子有三个主要组件(见图6-1)
- 一个基于Node.js的web应用,用于测试系统
- 一个Redis服务器,用于持久化数据
- 一个Storm拓扑,用于分布式实时处理数据
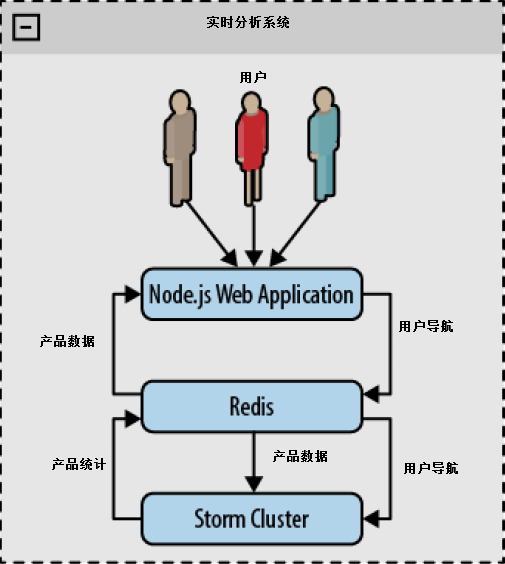
图6-1 架构概览
NOTE:你如果想先把这个例子运行起来,请首先阅读附录C
我们已经伪造了简单的电子商务网站。这个网站只有三个页面:一个主页、一个产品页和一个产品统计页面。这个应用基于Express和Socket.io两个框架实现了向浏览器推送内容更新。制作这个应用的目的是为了让你体验Storm集群功能并看到处理结果,但它不是本书的重点,所以我们不会对它的页面做更详细描述。
主页
这个页面提供了全部有效产品的链接。它从Redis服务器获取数据并在页面上把它们显示出来。这个页面的URL是http://localhost:3000/。(见图6-2,译者注,图6-2翻译如下,全是文字就不制图了)
有效产品:
DVD播放器(带环绕立体声系统)
全高清蓝光dvd播放器
媒体播放器(带USB 2.0接口)
全高清摄像机
防水高清摄像机
防震防水高清摄像机
反射式摄像机
双核安卓智能手机(带64GB SD卡)
普通移动电话
卫星电话
64GB SD卡
32GB SD卡
16GB SD卡
粉红色智能手机壳
黑色智能手机壳
小山羊皮智能手机壳
图6-2 首页
产品页
产品页用来显示指定产品的相关信息,例如,价格、名称、分类。这个页面的URL是:http://localhost:3000/product/:id。(见图6-3,译者注:全是文字不再制图,翻译如下)
产品页:32英寸液晶电视
分类:电视机
价格:400
相关分类
图6-3,产品页
产品统计页
这个页面显示通过收集用户浏览站点,用Storm集群计算的统计信息。可以显示为如下概要:浏览这个产品的用户,在那些分类下面浏览了n次产品。该页的URL是:http://localhost:3000/product/:id/stats。(见图6-4,译者注:全是文字,不再制图,翻译如下)
浏览了该产品的用户也浏览了以下分类的产品:
1.摄像机
2.播放器
3.手机壳
4.存储卡
图6-4. 产品统计视图
启动这个Node.js web应用
首先启动Redis服务器,然后执行如下命令启动web应用:
node webapp/app.js
为了向你演示,这个应用会自动向Redis填充一些产品数据作为样本。
Storm拓扑
为这个系统搭建Storm拓扑的目标是改进产品统计的实时性。产品统计页显示了一个分类计数器列表,用来显示访问了其它同类产品的用户数。这样可以帮助卖家了解他们的用户需求。拓扑接收浏览日志,并更新产品统计结果(见图6-5)。
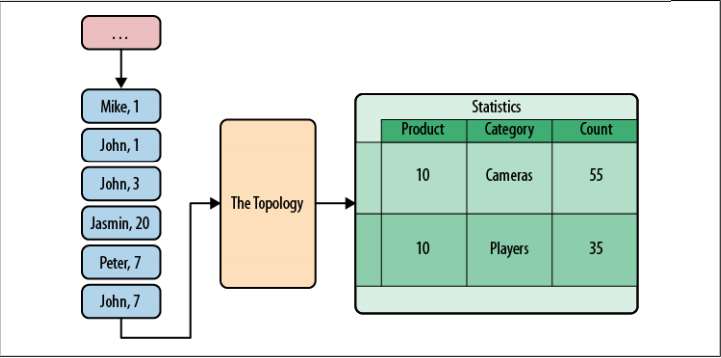
图6-5 Storm拓扑的输入与输出
我们的Storm拓扑有五个组件:一个spout向拓扑提供数据,四个bolt完成统计任务。
UsersNavigationSpout
从用户浏览数据队列读取数据发送给拓扑
GetCategoryBolt
从Redis服务器读取产品信息,向数据流添加产品分类
UserHistoryBolt
读取用户以前的产品浏览记录,向下一步分发Product:Category键值对,在下一步更新计数器
ProductCategoriesCounterBolt
追踪用户浏览特定分类下的商品次数
NewsNotifierBolt
通知web应用立即更新用户界面
下图展示了拓扑的工作方式(见图6-6)
package storm.analytics;
...
public class TopologyStarter {
public static void main(String[] args) {
Logger.getRootLogger().removeAllAppenders();
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("read-feed", new UsersNavigationSpout(),3);
builder.setBolt("get-categ", new GetCategoryBolt(),3)
.shuffleGrouping("read-feed");
builder.setBolt("user-history", new UserHistoryBolt(),5)
.fieldsGrouping("get-categ", new Fields("user"));
builder.setBolt("product-categ-counter", new ProductCategoriesCounterBolt(),5)
.fieldsGrouping("user-history", new Fields("product"));
builder.setBolt("news-notifier", new NewsNotifierBolt(),5)
.shuffleGrouping("product-categ-counter");
Config conf = new Config();
conf.setDebug(true);
conf.put("redis-host",REDIS_HOST);
conf.put("redis-port",REDIS_PORT);
conf.put("webserver", WEBSERVER);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("analytics", conf, builder.createTopology());
}
}
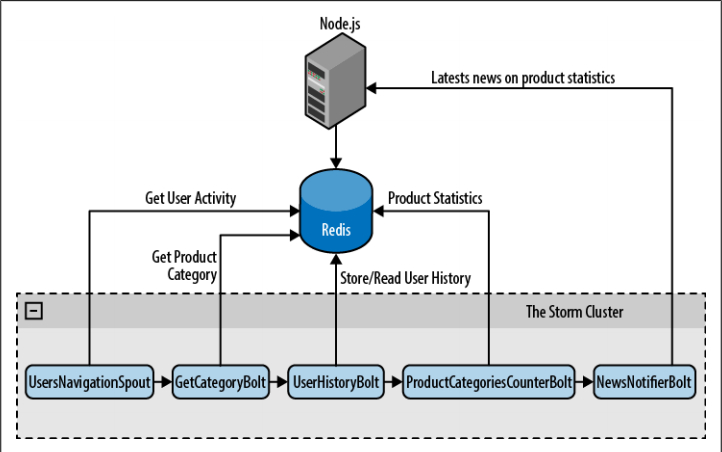
Figure 6-6 Storm拓扑
UsersNavigationSpout负责向拓扑提供浏览数据。每条浏览数据都是一个用户浏览过的产品页的引用。它们都被web应用保存在Redis服务器。我们一会儿就要看到更多信息。
你可以使用https://github.com/xetorthio/jedis从Redis服务器读取数据,这是个极为轻巧简单的Java Redis客户端。
NOTE:下面的代码块就是相关代码。
package storm.analytics;
public class UsersNavigationSpout extends BaseRichSpout {
Jedis jedis;
...
@Override
public void nextTuple() {
String content = jedis.rpop("navigation");
if(content==null || "nil".equals(content)){
try { Thread.sleep(300); } catch (InterruptedException e) {}
} else {
JSONObject obj=(JSONObject)JSONValue.parse(content);
String user = obj.get("user").toString();
String product = obj.get("product").toString();
String type = obj.get("type").toString();
HashMap<String, String> map = new HashMap<String, String>();
map.put("product", product);
NavigationEntry entry = new NavigationEntry(user, type, map);
collector.emit(new Values(user, entry));
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("user", "otherdata"));
}
}
spout首先调用jedis.rpop(“navigation”)从Redis删除并返回”navigation”列表最右边的元素。如果列表已经是空的,就休眠0.3秒,以免使用忙等待循环阻塞服务器。如果得到一条数据(数据是JSON格式),就解析它,并创建一个包含该数据的NavigationEntry POJO:
- 浏览页面的用户
- 用户浏览的页面类型
- 由页面类型决定的额外页面信息。“产品”页的额外信息就是用户浏览的产品ID。
spout调用collector.emit(new Values(user, entry))分发包含这些信息的元组。这个元组的内容是拓扑里下一个bolt的输入。
GetCategoryBolt
这个bolt非常简单。它只负责反序列化前面的spout分发的元组内容。如果这是产品页的数据,就通过ProductsReader类从Redis读取产品信息,然后基于输入的元组再分发一个新的包含具体产品信息的元组:
- 用户
- 产品
- 产品类别
package storm.analytics;
public class GetCategoryBolt extends BaseBasicBolt {
private ProductReader reader;
...
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
NavigationEntry entry = (NavigationEntry)input.getValue(1);
if("PRODUCT".equals(entry.getPageType())){
try {
String product = (String)entry.getOtherData().get("product");
//调用产品条目API,得到产品信息
Product itm = reader.readItem(product);
if(itm == null) {
return;
}
String categ = itm.getCategory();
collector.emit(new Values(entry.getUserId(), product, categ));
} catch (Exception ex) {
System.err.println("Error processing PRODUCT tuple"+ ex);
ex.printStackTrace();
}
}
}
...
}
正如前面所提到的, 使用ProductsReader类读取产品具体信息。
package storm.analytics.utilities;
...
public class ProductReader {
...
public Product readItem(String id) throws Exception{
String content = jedis.get(id);
if(content == null || ("nil".equals(content))){
return null;
}
Object obj = JSONValue.parse(content);
JSONObjectproduct = (JSONObject)obj;
Product i = new Product((Long)product.get("id"),
(String)product.get("title"),
(Long)product.get("price"),
(String)product.get("category"));
return i;
}
...
}
UserHistoryBolt
UserHistoryBolt是整个应用的核心。它负责持续追踪每个用户浏览过的产品,并决定应当增加计数的键值对。
我们使用Redis保存用户的产品浏览历史,同时基于性能方面的考虑,还应该保留一份本地副本。我们把数据访问细节隐藏在方法getUserNavigationHistory(user)和addProductToHistory(user,prodKey)里,分别用来读/写访问。它们的实现如下
package storm.analytics;
...
public class UserHistoryBolt extends BaseRichBolt{
@Override
public void execute(Tuple input) {
String user = input.getString(0);
String prod1 = input.getString(1);
String cat1 = input.getString(2);
//产品键嵌入了产品类别信息
String prodKey = prod1+":"+cat1;
Set productsNavigated = getUserNavigationHistory(user);
//如果用户以前浏览过->忽略它
if(!productsNavigated.contains(prodKey)) {
//否则更新相关条目
for (String other : productsNavigated) {
String[] ot = other.split(":");
String prod2 = ot[0];
String cat2 = ot[1];
collector.emit(new Values(prod1, cat2));
collector.emit(new Values(prod2, cat1));
}
addProductToHistory(user, prodKey);
}
}
}
需要注意的是,这个bolt的输出是那些类别计数应当获得增长的产品。
看一看代码。这个bolt维护着一组被每个用户浏览过的产品。值得注意的是,这个集合包含产品:类别键值对,而不是只有产品。这是因为你会在接下来的调用中用到类别信息,而且这样也比每次从数据库获取更高效。这样做的原因是基于以下考虑,产品可能只有一个类别,而且它在整个产品的生命周期当中不会改变。
读取了用户以前浏览过的产品集合之后(以及它们的类别),检查当前产品以前有没有被浏览过。如果浏览过,这条浏览数据就被忽略了。如果这是首次浏览,遍历用户浏览历史,并执行collector.emit(new Values(prod1,cat2))分发一个元组,这个元组包含当前产品和所有浏览历史类别。第二个元组包含所有浏览历史产品和当前产品类别,由collectior.emit(new Values(prod2,cat1))。最后,将当前产品和它的类别添加到集合。
比如,假设用户John有以下浏览历史:
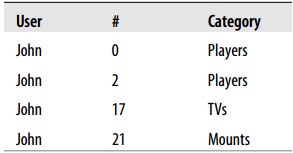
下面是将要处理的浏览数据

该用户没有浏览过产品8,因此你需要处理它。
因此要分发以下元组:
注意,左边的产品和右边的类别之间的关系应当作为一个整体递增。
现在,让我们看看这个Bolt用到的持久化实现。
public class UserHistoryBolt extends BaseRichBolt{
...
private Set getUserNavigationHistory(String user) {
Set userHistory = usersNavigatedItems.get(user);
if(userHistory == null) {
userHistory = jedis.smembers(buildKey(user));
if(userHistory == null)
userHistory = new HashSet();
usersNavigatedItems.put(user, userHistory);
}
return userHistory;
}
private void addProductToHistory(String user, String product) {
Set userHistory = getUserNavigationHistory(user);
userHistory.add(product);
jedis.sadd(buildKey(user), product);
}
...
}
getUserNavigationHistory方法返回用户浏览过的产品集。首先,通过usersNavigatedItems.get(user)方法试图从本地内存得到用户浏览历史,否则,使用jedis.smembers(buildKey(user))从Redis服务器获取,并把数据添加到本地数据结构usersNavigatedItems。
当用户浏览一个新产品时,调用addProductToHistory,通过userHistory.add(product)和jedis.sadd(buildKey(user),product)同时更新内存数据结构和Redis服务器。
需要注意的是,当你需要做并行化处理时,只要bolt在内存中维护着用户数据,你就得首先通过用户做域数据流分组(译者注:原文是fieldsGrouping,详细情况请见第三章的域数据流组),这是一件很重要的事情,否则集群内将会有用户浏览历史的多个不同步的副本。
ProductCategoriesCounterBolt
该类持续追踪所有的产品-类别关系。它通过由UsersHistoryBolt分发的产品-类别数据对更新计数。
每个数据对的出现次数保存在Redis服务器。基于性能方面的考虑,要使用一个本地读写缓存,通过一个后台线程向Redis发送数据。
该Bolt会向拓扑的下一个Bolt——NewsNotifierBolt——发送包含最新记数的元组,这也是最后一个Bolt,它会向最终用户广播实时更新的数据。
public class ProductCategoriesCounterBolt extends BaseRichBolt {
...
@Override
public void execute(){
String product = input.getString(0);
String categ = input.getString(1);
int total = count(product, categ);
collector.emit(new Values(product, categ, total));
}
...
private int count(String product, String categ) {
int count = getProductCategoryCount(categ, product);
count++;
storeProductCategoryCount(categ, product, count);
return count;
}
...
}
这个bolt的持久化工作隐藏在getProductCategoryCount和storeProductCategoryCount两个方法中。它们的具体实现如下:
package storm.analytics;
...
public class ProductCategoriesCounterBolt extends BaseRichBolt {
// 条目:分类 -> 计数
HashMap<String,Integer> counter = new HashMap<String, Integer>();
//条目:分类 -> 计数
HashMap<String,Integer> pendingToSave = new HashMap<String,Integer>();
...
public int getProductCategoryCount(String categ, String product) {
Integer count = counter.get(buildLocalKey(categ, product));
if(count == null) {
String sCount = jedis.hget(buildRedisKey(product), categ);
if(sCount == null || "nil".equals(sCount)) {
count = 0;
} else {
count = Integer.valueOf(sCount);
}
}
return count;
}
...
private void storeProductCategoryCount(String categ, String product, int count) {
String key = buildLocalKey(categ, product);
counter.put(key, count);
synchronized (pendingToSave) {
pendingToSave.put(key, count);
}
}
...
}
方法getProductCategoryCount首先检查内存缓存计数器。如果没有有效令牌,就从Redis服务器取得数据。
方法storeProductCategoryCount更新计数器缓存和pendingToSae缓冲。缓冲数据由下述后台线程持久化。
package storm.analytics;
public class ProductCategoriesCounterBolt extends BaseRichBolt {
...
private void startDownloaderThread() {
TimerTask t = startDownloaderThread() {
@Override
public void run () {
HashMap<String, Integer> pendings;
synchronized (pendingToSave) {
pendings = pendingToSave;
pendingToSave = new HashMap<String,Integer>();
}
for (String key : pendings.keySet) {
String[] keys = key.split(":");
String product = keys[0];
String categ = keys[1];
Integer count = pendings.get(key);
jedis.hset(buildRedisKey(product), categ, count.toString());
}
}
};
timer = new Timer("Item categories downloader");
timer.scheduleAtFixedRate(t, downloadTime, downloadTime);
}
...
}
下载线程锁定pendingToSave, 向Redis发送数据时会为其它线程创建一个新的缓冲。这段代码每隔downloadTime毫秒运行一次,这个值可由拓扑配置参数download-time配置。download-time值越大,写入Redis的次数就越少,因为一对数据的连续计数只会向Redis写一次。
NewsNotifierBolt
为了让用户能够实时查看统计结果,由NewsNotifierBolt负责向web应用通知统计结果的变化。通知机制由Apache HttpClient通过HTTP POST访问由拓扑配置参数指定的URL。POST消息体是JSON格式。
测试时把这个bolt从拜年中删除。
[code lang=”java”]
package storm.analytics;
…
public class NewsNotifierBolt extends BaseRichBolt {
…
@Override
public void execute(Tuple input) {
String product = input.getString(0);
String categ = input.getString(1);
int visits = input.getInteger(2);</code>
String content = "{\"product\":\"+product+"\",\"categ\":\""+categ+"\",\"visits\":"+visits+"}";
HttpPost post = new HttpPost(webserver);
try {
post.setEntity(new StringEntity(content));
HttpResponse response = client.execute(post);
org.apache.http.util.EntityUtils.consume(response.getEntity());
} catch (Exception e) {
e.printStackTrace();
reconnect();
}
}
…
}
[/code]
Redis服务器
Redis是一种先进的、基于内存的、支持持久化的键值存储(见http://redis.io)。本例使用它存储以下信息:
- 产品信息,用来为web站点服务
- 用户浏览队列,用来为Storm拓扑提供数据
- Storm拓扑的中间数据,用于拓扑发生故障时恢复数据
- Storm拓扑的处理结果,也就是我们期望得到的结果。
产品信息
Redis服务器以产品ID作为键,以JSON字符串作为值保存着产品信息。
[code lang=”bash”]
redis-cli
redis 127.0.0.1:6379> get 15
"{\"title\":\"Kids smartphone cover\",\"category\":\"Covers\",\"price\":30,\"id\":
15}"
[/code]
用户浏览队列保存在Redis中一个键为navigation的先进先出队列中。用户浏览一个产品页时,服务器从队列左侧添加用户浏览数据。Storm集群不断的从队列右侧获取并移除数据。
[code lang=”bash”]
redis 127.0.0.1:6379> llen navigation
(integer) 5
redis 127.0.0.1:6379> lrange navigation 0 4
1) "{\"user\":\"59c34159-0ecb-4ef3-a56b-99150346f8d5\",\"product\":\"1\",\"type\":
\"PRODUCT\"}"
2) "{\"user\":\"59c34159-0ecb-4ef3-a56b-99150346f8d5\",\"product\":\"1\",\"type\":
\"PRODUCT\"}"
3) "{\"user\":\"59c34159-0ecb-4ef3-a56b-99150346f8d5\",\"product\":\"2\",\"type\":
\"PRODUCT\"}"
4) "{\"user\":\"59c34159-0ecb-4ef3-a56b-99150346f8d5\",\"product\":\"3\",\"type\":
\"PRODUCT\"}"
5) "{\"user\":\"59c34159-0ecb-4ef3-a56b-99150346f8d5\",\"product\":\"5\",\"type\":
\"PRODUCT\"}"
[/code]
中间数据
集群需要分开保存每个用户的历史数据。为了实现这一点,它在Redis服务器上保存着一个包含所有用户浏览过的产品和它们的分类的集合。
[code lang=”bash”]
redis 127.0.0.1:6379> smembers history:59c34159-0ecb-4ef3-a56b-99150346f8d5
1) "1:Players"
2) "5:Cameras"
3) "2:Players"
4) "3:Cameras"
[/code]
结果
Storm集群生成关于用户浏览的有用数据,并把它们的产品ID保存在一个名为“prodcnt”的Redis hash中。
[code lang=”bash”]
redis 127.0.0.1:6379> hgetall prodcnt:2
1) "Players"
2) "1"
3) "Cameras"
4) "2"
[/code]
测试拓扑
使用LocalCluster和一个本地Redis服务器执行测试(见图6-7)。向Redis填充产品数据,伪造访问日志。我们的断言会在读取拓扑向Redis输出的数据时执行。测试用户用java和groovy完成。
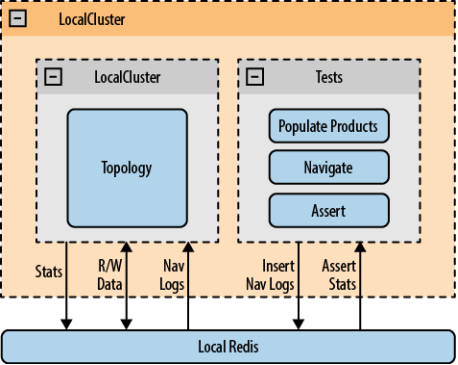
图6-7. 测试架构
初始化测试
初始化由以下三步组成:
启动LocalCluster并提交拓扑。初始化在AbstractAnalyticsTest实现,所有测试用例都继承该类。当初始化多个AbstractAnalyticsTest子类对象时,由一个名为topologyStarted的静态标志属性确定初始化工作只会进行一次。
需要注意的是,sleep语句是为了确保在试图获取结果之前LocalCluster已经正确启动了。
[code lang=”groovy”]
public abstract class AbstractAnalyticsTest extends Assert {
def jedis
static topologyStarted = false
static sync= new Object()
private void reconnect() {
jedis = new Jedis(TopologyStarter.REDIS_HOST, TopologyStarter.REDIS_PORT)
}
@Before
public void startTopology(){
synchronized(sync){
reconnect()
if(!topologyStarted){
jedis.flushAll()
populateProducts()
TopologyStarter.testing = true
TopologyStarter.main(null)
topologyStarted = true
sleep 1000
}
}
}
…
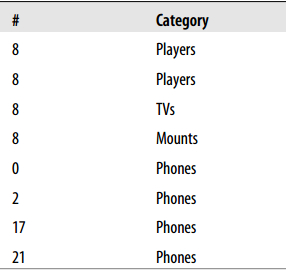
public void populateProducts() {
def testProducts = [
[id: 0, title:"Dvd player with surround sound system",
category:"Players", price: 100],
[id: 1, title:"Full HD Bluray and DVD player",
category:"Players", price:130],
[id: 2, title:"Media player with USB 2.0 input",
category:"Players", price:70],
…
[id: 21, title:"TV Wall mount bracket 50-55 Inches",
category:"Mounts", price:80]
]
testProducts.each() { product ->
def val =
"{ \"title\": \"${product.title}\" , \"category\": \"${product.category}\"," +
" \"price\": ${product.price}, \"id\": ${product.id} }"
println val
jedis.set(product.id.toString(), val.toString())
}
}
…
}
[/code]
在AbstractAnalyticsTest中实现一个名为navigate的方法。为了测试不同的场景,我们要模拟用户浏览站点的行为,这一步向Redis的浏览队列(译者注:就是前文提到的键是navigation的队列)插入浏览数据。
[code lang=”groovy”]
public abstract class AbstractAnalyticsTest extends Assert {
…
public void navigate(user, product) {
String nav =
"{\"user\": \"${user}\", \"product\": \"${product}\", \"type\": \"PRODUCT\"}".toString()
println "Pushing navigation: ${nav}"
jedis.lpush(‘navigation’, nav)
}
…
}
[/code]
实现一个名为getProductCategoryStats的方法,用来读取指定产品与分类的数据。不同的测试同样需要断言统计结果,以便检查拓扑是否按照期望的那样执行了。
[code lang=”groovy”]
public abstract class AbstractAnalyticsTest extends Assert {
…
public int getProductCategoryStats(String product, String categ) {
String count = jedis.hget("prodcnt:${product}", categ)
if(count == null || "nil".equals(count))
return 0
return Integer.valueOf(count)
}
…
}
[/code]
一个测试用例
下一步,为用户“1”模拟一些浏览记录,并检查结果。注意执行断言之前要给系统留出两秒钟处理数据。(记住ProductCategoryCounterBolt维护着一份计数的本地副本,它是在后台异步保存到Redis的。)
[code lang=”groovy”]
package functional
class StatsTest extends AbstractAnalyticsTest {
@Test
public void testNoDuplication(){
navigate("1", "0") // Players
navigate("1", "1") // Players
navigate("1", "2") // Players
navigate("1", "3") // Cameras
Thread.sleep(2000) // Give two seconds for the system to process the data.
assertEquals 1, getProductCategoryStats("0", "Cameras")
assertEquals 1, getProductCategoryStats("1", "Cameras")
assertEquals 1, getProductCategoryStats("2", "Cameras")
assertEquals 2, getProductCategoryStats("0", "Players")
assertEquals 3, getProductCategoryStats("3", "Players")
}
}
[/code]
对可扩展性和可用性的提示
为了能在一章的篇幅中讲明白整个方案,它已经被简化了。正因如此,一些与可扩展性和可用性有关的必要复杂性也被去掉了。这方面主要有两个问题。
Redis服务器不只是一个故障的节点,还是性能瓶颈。你能接收的数据最多就是Redis能处理的那些。Redis可以通过分片增强扩展性,它的可用性可以通过主从配置得到改进。这都需要修改拓扑和web应用的代码实现。
另一个缺点就是web应用不能通过增加服务器成比例的扩展。这是因为当产品统计数据发生变化时,需要通知所有关注它的浏览器。这一“通知浏览器”的机制通过Socket.io实现,但是它要求监听器和通知器在同一主机上。这一点只有当GET /product/:id/stats和POST /news满足以下条件时才能实现,那就是这二者拥有相同的分片标准,确保引用相同产品的请求由相同的服务器处理。
原创文章,转载请注明: 转载自并发编程网 – ifeve.com本文链接地址: Storm入门之第6章一个实际的例子


 (9 votes, average: 3.56 out of 5)
(9 votes, average: 3.56 out of 5)

暂无评论