《Kafka官方文档》实现
1. API Design
Producer APIs
Producer API封装了底层两个Producer:
- kafka.producer.SyncProducer
- kafka.producer.async.AsyncProducer
class Producer {
/* Sends the data, partitioned by key to the topic using either the */
/* synchronous or the asynchronous producer */
public void send(kafka.javaapi.producer.ProducerData<K,V> producerData);
/* Sends a list of data, partitioned by key to the topic using either */
/* the synchronous or the asynchronous producer */
public void send(java.util.List<kafka.javaapi.producer.ProducerData<K,V>> producerData);
/* Closes the producer and cleans up */
public void close();
}这么做的目的是通过一个简答的API暴露把所有Producer的功能暴露给Client。Kafka的Producer可以:
- 排队/缓存多个发送请求并且异步的批量分发出去:
kafka.producer.Producer提供批量化多个发送请求(producer.type=async),之后进行序列化并发送的分区的能力。批大小可以通过一些配置参数进行设置。将事件加入到queue中,他们会被缓冲在queue中,直到满足queue.time或batch.size达到配置的值。后台线程(kafka.producer.async.ProducerSendThread)从queue中获取数据并使用kafka.producer.EventHandler对数据进行序列化并发送到合适的分区。可以通过event.handler参数以插件的形式添加自定义的event handler程序。在producer queue pipeline处理的各个阶段可以注入回调,用于自定义的日志/跟踪代码或者监控逻辑。这可以通过实现kafka.producer.async.CallbackHandler接口并设置callback.handler参数来实现。
- 使用用户指定的
Encoder来序列化数据:
interface Encoder<T> {
public Message toMessage(T data);
}默认使用kafka.serializer.DefaultEncoder。
- 通过用户可选的
Partitioner来实现乱负载均衡:
Partition的路由由kafka.producer.Partitioner决定。
interface Partitioner<T> {
int partition(T key, int numPartitions);
}分区选择API使用key和分区总数来选择最终的partition(返回选择的partition id)。id用于从排序的partition列表中选择最终的一个分区去发送数据。默认的分区策略是hash(key)%numPartitions。如果key是null,会随机选择一个分区。可以通过partitioner.class参数来配置特定的分区选择策略。
Consumer APIs
我们有两个级别的Consumer API。低级别的“简单的”API和单个Broker之间保持链接并且和发送到服务端的网络请求有紧密的对应关系。这个API是无状态的,每个请求都包含offset信息,允许用户维护这个元数据。
高级别的API在Consumer端隐藏了Broker的细节,并且允许从集群消费数据而不关心底层的拓扑结构。同样维持了“哪些数据已经被消费过”的状态。高级别的API还提供了通过表达式订阅的Topic的功能(例如通过白名单或者黑名单的方式订阅)。
Low-level API
class SimpleConsumer {
/* Send fetch request to a broker and get back a set of messages. */
public ByteBufferMessageSet fetch(FetchRequest request);
/* Send a list of fetch requests to a broker and get back a response set. */
public MultiFetchResponse multifetch(List<FetchRequest> fetches);
/**
* Get a list of valid offsets (up to maxSize) before the given time.
* The result is a list of offsets, in descending order.
* @param time: time in millisecs,
* if set to OffsetRequest$.MODULE$.LATEST_TIME(), get from the latest offset available.
* if set to OffsetRequest$.MODULE$.EARLIEST_TIME(), get from the earliest offset available.
*/
public long[] getOffsetsBefore(String topic, int partition, long time, int maxNumOffsets);
}低级别的API用于实现高级别的API,也被直接使用在一些在状态上有特殊需求的“离线”Consumer。
High-level API
/* create a connection to the cluster */
ConsumerConnector connector = Consumer.create(consumerConfig);
interface ConsumerConnector {
/**
* This method is used to get a list of KafkaStreams, which are iterators over
* MessageAndMetadata objects from which you can obtain messages and their
* associated metadata (currently only topic).
* Input: a map of <topic, #streams>
* Output: a map of <topic, list of message streams>
*/
public Map<String,List<KafkaStream>> createMessageStreams(Map<String,Int> topicCountMap);
/**
* You can also obtain a list of KafkaStreams, that iterate over messages
* from topics that match a TopicFilter. (A TopicFilter encapsulates a
* whitelist or a blacklist which is a standard Java regex.)
*/
public List<KafkaStream> createMessageStreamsByFilter(
TopicFilter topicFilter, int numStreams);
/* Commit the offsets of all messages consumed so far. */
public commitOffsets()
/* Shut down the connector */
public shutdown()
}这个API围绕迭代器,通过KafkaStream类实现。一个KafkaStream表示了一个或多个分区(可以分布在不同的Broker上)组成的消息流。每个Stream被单个线程处理,客户端可以在创建流时提供需要的个数。这样,一个流背后可以是多个分区,但是一个分区只会属于一个流。
createMessageStreams调用会吧Consumer注册到Topic,促使Consumer/Broker的重新分配。API鼓励在单次调用中创建多个Stream以减少充分配的次数。createMessageStreamsByFilter方法的调用(另外的)用于注册watcher去发现匹配过滤规则的topic。createMessageStreamsByFilter返回的迭代器可以迭代来此多个Topic的消息(如果多个Topic都符合过滤规则)。
2. Network Layer
网络层是一个直接的NIO Server,不会详细的描述。sendfile是通过给MessageSet增加writeTo方法实现的。这允许使用文件存储的消息用更高效的transferTo实现代替读取数据到进程内的处理。线程模型是简单的单acceptor多processor,每个线程处理固定数量的连接。这种设计已经被很好的测试并且是易于实现的。协议非常简单,以便在将来实现其他语言的客户端。
3. Messages
消息包含一个固定大小的头,一个变长且“不透明”的byte数组表示的key和一个变长且“不透明”的byte数组表示的内容。header包含以下内容:
- A CRC32 checksum to detect corruption or truncation.
- A format version.
- An attributes identifier
- A timestamp
保持key和value的不透明是正确的决定:现在序列化方面取得了巨大的进展,选择特定的一个序列化方式都不太适合所有的场景。不用说使用Kafka的特定程序可能需要特定的序列化方式。MessageSet接口是批量读写消息到NIO Channel的迭代器。
4. Message Format
/**
* 1. 4 byte CRC32 of the message
* 2. 1 byte "magic" identifier to allow format changes, value is 0 or 1
* 3. 1 byte "attributes" identifier to allow annotations on the message independent of the version
* bit 0 ~ 2 : Compression codec.
* 0 : no compression
* 1 : gzip
* 2 : snappy
* 3 : lz4
* bit 3 : Timestamp type
* 0 : create time
* 1 : log append time
* bit 4 ~ 7 : reserved
* 4. (Optional) 8 byte timestamp only if "magic" identifier is greater than 0
* 5. 4 byte key length, containing length K
* 6. K byte key
* 7. 4 byte payload length, containing length V
* 8. V byte payload
*/5. Log
包含两个partition,名称为“my_topic”的Topic的日志包含两个目录(名称为my_topic_0和my_topic_1),其中包含该Topic的消息的数据文件。日志文件的格式是log entry的序列;每个log entry都是4字节的消息长度N加上后面N个字节的消息数据。每条消息都有一个64位的offset标识这条消息在这个Topic的Partition中的偏移量。消息在磁盘中的存储格式如下所示。每个日志文件都以它存储的第一条消息的offset命名。所以第一个文件会命名为00000000000.kafka,随后每个文件的文件名将是前一个文件的文件名加上S的正数,S是配置中指定的单个文件的大小。
消息的确切的二进制格式都有版本,它保持一个标准的接口,让消息集可以根据需要在Producer、Broker、Consumer之间传输而不需要重新拷贝或者转换,其格式如下:
On-disk format of a message
offset : 8 bytes
message length : 4 bytes (value: 4 + 1 + 1 + 8(if magic value > 0) + 4 + K + 4 + V)
crc : 4 bytes
magic value : 1 byte
attributes : 1 byte
timestamp : 8 bytes (Only exists when magic value is greater than zero)
key length : 4 bytes
key : K bytes
value length : 4 bytes
value : V bytes使用消息的Offset作为消息ID是不常见的。我们初始的想法是在Producer生成一个GUID作为Message ID,并在Broker上维持ID和Offset之间的映射关系。但是因为Consumer需要为每个Server维持一个ID,那么GUID的全局唯一性就变得没什么意义了。此外,维持一个随机的ID和Offset的映射关系将给索引的构建带来巨大的负担,本质上需要一个完整的持久化的随机存取的数据结构。因此,为了简化查找结构,我们决定使用每个分区的原子计数器,它可以和分区ID加上ServerID来唯一标识一条消息。一旦使用了计数器,直接使用Offset进行跳转是顺其自然的,两者都是分区内单调递增的整数。由于偏移量从消费者API中隐藏起来,因此这个决定是最终的实现细节,所以我们采用更有效的方法。
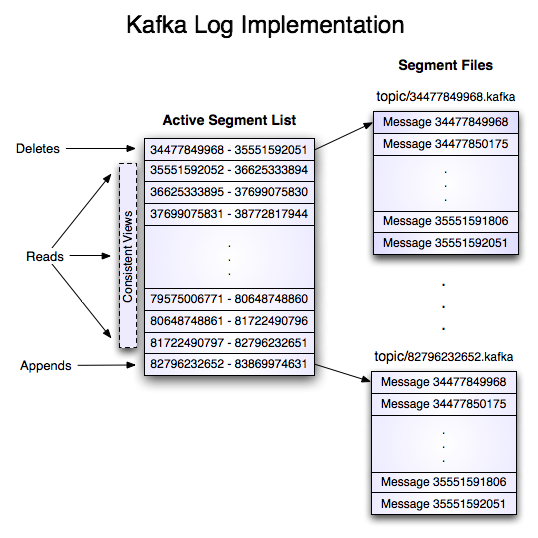
Writes
日志允许连续追加到最后一个文件。当文件达到配置的大小时(如1GB)将滚动到一个新文件。日志采用两个配置:M,配置达到多少条消息后进行刷盘;S,配置多长时间之后进行刷盘。这个持久化策略保证最多只丢失M条消息或者S秒之内的消息。
Reads
读取通过提供64位的offset和S-byte的chunk大小来实现。这将返回包含在S-byte的buffer的消息跌代替。S比任意单条消息都大,但是如果在异常的超大消息的情况下,读取操作可以通过多次重试,每次都将buffer大小翻倍,直到消息被读取成功。最大消息大小和buffer大小可以配置,用于拒绝超过特定大小的消息,以限制客户端读取消息时需要拓展的buffer大小。buffer可能以不完整的消息作为结尾,这可以通过消息大小来轻松的检测到。
实际的读取操作首先需要定位offset所在的文件,再将offset转化为文件内相对的偏移量,然后从文件的这个偏移量开始读取数据。搜索操作通过内存中映射的文件的简单的二分查找完成。
日志提供了获取最近写入消息的能力以允许客户端从“当前时间”开始订阅。这在客户端无法在指定天数内消费掉消息的场景中非常有用。在这种情况下,如果客户端尝试消费一个不存在的offset将抛出OutOfRangeException异常并且可以根据场景重置或者失败。
这面是发送到Consumer的数据的格式:
MessageSetSend (fetch result)
total length : 4 bytes
error code : 2 bytes
message 1 : x bytes
...
message n : x bytes MultiMessageSetSend (multiFetch result)
total length : 4 bytes
error code : 2 bytes
messageSetSend 1
...
messageSetSend nDeletes
数据删除一次删除一个日志段。日志管理器允许通过插件的形式实现删除策略来选择那些文件是合适删除的。当前的删除策略是日志文件的修改时间已经过去N天,保留最近N GB数据的策略也是有用的。为了避免删除时锁定读取操作,我们采用copy-on-write的方式来实现,以保证一致性的视图。
Guarantees
日志提供了配置参数M,用于控制写入多少条消息之后进行一次刷盘。在日志恢复过程中遍历最新的日志段的所有消息并验证每一条消息是有效的。如果消息的大小和偏移量之和小于文件长度并且消息的CRC32和存储的CRC相同,那么消息是有效的。在异常事件被检测到时,日志会被截取到最后一条有效的消息的offset。
两种错误需要处理:因为Crash导致的written块丢失和无意义的block被添加到文件中。这样做的原因是,一般的操作系统不保证file inode和实际数据块之间的写入顺序,所以除了丢失丢失written data,文件还会获得无意义的数据,在inode更新大小但是在block写入数据之前。CRC检测这个错误并防止损坏日志(unwritten的消息肯定会丢失)。
6. Distribution
Consumer Offset Tracking
high-level的Consume保持它自己消费过的每个分区的最大的offset并且周期性的提交,所以可以在重启的时候恢复offset信息。Kafka提供在offset manager中保存所有offset的选项。任何Consumer实例都需要发送offset到offset manager。high-level的Consumer自动化的处理offset。如果使用simple consumer,需要自己手动管理offset。在Java simple consumer中现在还不支持,Java simple consumer只能从ZooKeeper提交和获取offset。如果使用Scala simple consumer,你会找到offset manager并且可以明确指定向offset manager提交和获取offset。Consumer通过向Broker发送GroupCoordinatorRequest请求并获取包含offset manager的GroupCoordinatorResponse来获取offset。之后Consumer可以向offset manager提交和获取offset。如果offset manager移动,Consumer需要重新发现。如果你期望手动管理offset,可以查看这些解释如果提交OffsetCommitRequest和OffsetFetchRequest的代码。
当offset manager收到OffsetCommitRequest,将其添加到一个特殊的、压缩的,成为_consumeroffsets的Kafka topic中。offset manager返回一个成功的offset commit的响应给Consumer,当所有的备份都收到offset之后。如果在配置的timeout时间内所有副本没有完成备份,commit offset认为是失败的,将在之后重试(high-consumer将自动执行)。broker周期性的压缩offset信息,因为它只需要保存每个Partition最近的offset信息即可。为了更快的响应获取offset的请求,offset manager也会在内存缓存offset数据。
当offset manager收到fetch offset的请求,它从cache中返回最近commit的offset。如果offset manager是刚启动或者刚成为一些group的offset manager(通过成为一下offset topic的leader partition),它需要加载offset信息。这种情况下,fetch offset request或返回OffsetsLoadInProgress异常,Consumer需要之后重试(high-level consumer会自动处理)。
Migrating offsets from ZooKeeper to Kafka
Kafka较早的版本将offset信息存储在ZooKeeper中。可以通过以下步骤将这些数据迁移到Kafka中:
- 在Consumer配置中设置offsets.storage=kafka,dual.commit.enabled=true
- 验证Consumer正常
- 设置dual.commit.enabled=false
- 验证Consumer正常
回滚(从Kafka到ZooKeeper)也可以通过以上的步骤执行,只需要将offsets.storage设置为zookeeper。
ZooKeeper Directories
以下说明ZooKeeper用于统筹Consumer和Broker的结构和算法。
Notation
路径中标志位[xyz]表示xyz是不固定的,如/topics/[topic]表示/topics下每个topic都有一个对应的目录。[0…5]表示0,1,2,3,4,5的序列。->符号用于指示一个节点的值,如/hello -> world表示/hello存储的值是“world”。
Broker Node Registry
/brokers/ids/[0...N] --> {"jmx_port":...,"timestamp":...,"endpoints":[...],"host":...,"version":...,"port":...} (ephemeral node)这是一个所有存在的Broker的节点列表,每个都提供一个唯一标识用于Consumer识别(必须作为配置的一部分)。在启动时,Broker通过在/brokers/ids中创建一个znode来注册自己。使用逻辑上的Broker ID的目的是可以在不影响Consumer的前提下将Broker移动到另外的物理机上。如果尝试注册一个已经存在的ID的Broker会失败。
一旦Broker通过临时节点注册到ZK,注册信息是动态的并且在Broker宕机或者关闭后会丢失(那么通知消费者Broker不再可用)。
Broker Topic Registry
/brokers/topics/[topic]/partitions/[0...N]/state --> {"controller_epoch":...,"leader":...,"version":...,"leader_epoch":...,"isr":[...]} (ephemeral node)每个Broker将自己注册到它包含的Topic下面,并保存Topic的partition数量。
Consumers and Consumer Groups
Consumer同样将自己注册到ZK中,为了协调其他的Consumer并且做消费数据的负载均衡。Consumer还可以通过offsets.storage=zookeeper将offset信息也存储在ZK中。但是这个存储一直在未来的版本中将被废弃。因此建议将offset信息迁移到Kafka中。
多个Consumer可以组成一个集群共同消费一个Topic。一个Group中的每个Consumer实例共享一个group_id。
一个Group中的Consumer尽可能公平的分配partition,每个partition只能被一个group中的一个Consumer消费。
Consumer Id Registry
除了一个group内的所有Consumer实例共享一个groupid,每个Consumer实例还拥有一个唯一的consumerid(hostname:uuid)用于区分不同的实例。Consumer的id注册在以下的目录中。
/consumers/[group_id]/ids/[consumer_id] --> {"version":...,"subscription":{...:...},"pattern":...,"timestamp":...} (ephemeral node)每个Consumer将自己注册到Group目录下并创建一个包含id的znode。节点的值包含<topic, #stream=””>的Map。id用于标识group中哪些Consumer是活跃的。节点是临时节点,所以在Consumer进程关闭之后节点会丢失。
Consumer Offsets
Consumer记录每个分区消费过的最大的offset信息。如果配置了offsets.storage=zookeeper,这个数据会被记录到ZK中。
/consumers/[group_id]/offsets/[topic]/[partition_id] --> offset_counter_value (persistent node)Partition Owner registry
每个Partition都被一个group内的一个Consumer消费。这个Consumer必须在消费这个Partition之前建立对这个Partition的所有权。为了建立所有权,Consumer需要将id写入到Partition下面。
/consumers/[group_id]/owners/[topic]/[partition_id] --> consumer_node_id (ephemeral node)Cluster Id
Cluster id是唯一且不可变的,用于表示Cluster。Cluster id最长可以拥有22个字符,由[a-zA-Z0-9_-]+组成。从概念上讲,它在Cluster第一次启动的时候生成。
实现层面上,它在Broker(0.10.1或更新的版本)第一次成功启动后产生。Broker在启动时尝试从/cluster/id节点获取cluster id。如果不存在,Broker穿件一个新的cluster id写入到这个节点中。
Broker node registration
Broker节点基本上是相互独立的,所以他们只是发布他们自己拥有的信息。当一个Broker加入时,它将自己注册到broker node,并写入自己的信息(host name和port)。Broker还将自己的Topic和Partition注册到对应的目录中。新Topic会被动态的注册,当他们在Broker上创建的时候。
Consumer registration algorithm
当启动一个Consumer时,它按照如下步骤操作:
- 在group下注册自己的consumer id
- 注册监听器用于监听新Consumer的加入和Consumer的关闭,Consumer变更都会触发Partition的分配(负载均衡)。
- 注册监听器用于监听Broker的加入和关闭,Broker变更都会触发Partition的分配(负载均衡)。
- 如果Consumer通过filter创建了一个消息流,同样会注册一个监听器用于监听新topic的加入。
- 强制自己在消费group内重新平衡。
Consumer rebalancing algorithm
Consumer的负载均衡算法允许一个group内的所有Consumer对哪个Consumer消费哪些Partition达成一个共识。Consumer的负载均衡被Broker和同一个Group中的其他Consumer的添加和移除触发。对于给定的topic和group,partitions被平均的分配个consumers。这个设计是为了简化实现。如果我们允许一个分区同时被多个Consumer消费,那么在这个分区上会有冲突,需要一些锁去保证。如果consumer的数量超过了分区数,部分consumer会拿不到任何数据。在充分配算法中,我们分配分区时尽量使consumer需要和最少的Broker通信。
每个Consumer按照如下步骤进行重分配:
1. 对于Ci(Ci表示Consumer Instance)订阅的Topic T
2. PT表示Topic T的所有分区T
3. CG表示group内所有的Consumer
4. 对PT进行排序 (那么相同Broker上的分区会被集中到一起)
5. 对GC排序
6. i表示Ci在CG中的位置,N = size(PT)/size(CG)
7. 分配 i*N to (i+1)*N - 1 给Consumer Ci
8. 从分区所有者注册表中删除Ci拥有的这些条目
9. 将分区添加到所有者的分区注册表中
(我们可能需要重试直到分区原来的拥有者释放分区所有权)当分区重分配在一个Consumer触发时,重分配应该在同一时间在相同group内的其他Consumer上也触发。
原创文章,转载请注明: 转载自并发编程网 – ifeve.com本文链接地址: 《Kafka官方文档》实现


 (7 votes, average: 3.86 out of 5)
(7 votes, average: 3.86 out of 5)

暂无评论