聊聊我对Java内存模型的理解
所有的编程语言中都有内存模型这个概念,区别于微架构的内存模型,高级语言的内存模型包括了编译器和微架构两部分。我试图了解了Java、C#和Go语言的内存模型,发现内容基本大同小异,只是这些语言在具体实现的时候略有不同。
我们来看看Java内存模型吧,提到Java内存模型大家对这个图一定非常熟悉:

这张图告诉我们在线程运行的时候有一个内存专用的一小块内存,当Java程序会将变量同步到线程所在的内存,这时候会操作工作内存中的变量,而线程中变量的值何时同步回主内存是不可预期的。但同时Java内存模型又告诉我们通过使用关键词“synchronized”或“volatile”可以让Java保证某些约束:
“volatile” — 保证读写的都是主内存的变量
“synchronized” — 保证在块开始时都同步主内存的值到工作内存,而块结束时将变量同步回主内存
通过以上描述我们就可以写出线程安全的Java程序,JDK也同时帮我们屏蔽了很多底层的东西。
但当你深入了解JVM的时候你会发现根本就没有工作内存这个东西,即内存中根本不会分配这么一块空间来运行你的Java程序,那么工作内存到底是什么东西呢?
这个问题也曾经困扰了我很长时间,因为我从来没有从JVM的实现中找到过和主内存同步的代码,因为当使用“volatile”时我仅仅能从源代码中调用了这行语句:
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
而这个指令在部分微架构上的主要功能就是防止指令重排,即这条指令前后的其它指令不会越过这个界限执行[注1]。
在现在的x86/x64微架构中读写内存的一致性都是通过MESI(Intel使用MESI-F,AMD使用MOESI)协议保证[注2],MESI的状态转换图如下:
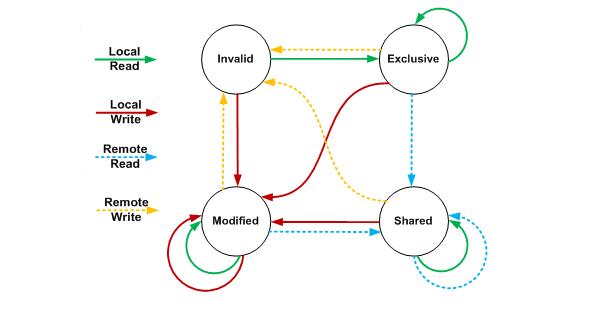
更详细的中文文档描述可以查看这个文档:http://blog.csdn.net/zhuliting/article/details/6210921
那Java内存模型中所说的工作内存是什么呢?
我的理解是,首先“工作内存”是一个虚拟的概念,而承载这个概念主要是两部分:
1. 编译器
2. 微架构
作为编译器肯定是执行速度越快越好,所以作为编译器应当尽量减少从内存读数据,如果一个数据在寄存器中,那么直接使用寄存器中的值无疑性能是最高的,但同时这也会导致可能读不到最新的值,这里我们通过在Java语言中为变量加上“volatile”强制告诉编译器这个变量一定要从内存获得,这时编译器即不会做此类优化【案例见参考资料5(是一个.Net的例子)】。
对于微架构来说,在x86/x64下,CPU会在执行指令时做指令重排,即编译器生成的指令顺序和真正在CPU执行的顺序可能是不一致的。当我们用一个变量做信号的时候这种指令重排会带来悲剧,即如果有如下代码:
[code lang=”java”]
x = 0;
y = 0;
i = 0;
j = 0;
// thread A
y = 1;
x = 1;
// thread B
i = x;
j = y;
[/code]
上面的代码i和j的值会是多少呢?答案是:“00, 01, 10, 11”都是有可能的。
对于这种情况,如果我们想得到确定的结果则需要通过“synchronized”(或者j.c.u.locks)来做线程间同步。
所以,我个人对Java内存模型的理解是:在编译器各种优化及多种类型的微架构平台上,Java语言规范制定者试图创建一个虚拟的概念并传递到Java程序员,让他们能够在这个虚拟的概念上写出线程安全的程序来,而编译器实现者会根据Java语言规范中的各种约束在不同的平台上达到Java程序员所需要的线程安全这个目的。
注1:关于“lock”前缀的详细说明可以查看这个文档《Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 3A: System Programming Guide, Part 1》的 这个章节“CHAPTER 8 MULTIPLE-PROCESSOR MANAGEMENT”。
注2:不同的微架构的内存模型都会有一些差别,本文中都是指x86/x64,如果想了解更多的微架构是如何处理的可以参考这个文档:http://gee.cs.oswego.edu/dl/jmm/cookbook.html
参考资料:
[1]. 《Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 3A: System Programming Guide, Part 1》
[2]. http://en.wikipedia.org/wiki/MESI_protocol
[3]. http://www.javaol.net/2010/10/java-memory-model/
[4]. http://gee.cs.oswego.edu/dl/jmm/cookbook.html
[5]. http://igoro.com/archive/volatile-keyword-in-c-memory-model-explained/
原创文章,转载请注明: 转载自并发编程网 – ifeve.com本文链接地址: 聊聊我对Java内存模型的理解


 (8 votes, average: 3.88 out of 5)
(8 votes, average: 3.88 out of 5)

受益匪浅,多谢分享,不过没有说一下区别
你好,不清楚你讲的“没有说一下区别”是指什么?
他应该指的是Java、C#和Go语言内存模型的细微区别。
嗯,我最近准备整理一下,不过C#和Go语言的资料远远不及Java的多
分析的很透彻,很欣赏你的看法,学习了。
两张图是点睛之笔
hi,“在x86/x64下,CPU会在执行指令时做指令重排,即编译器生成的指令顺序和真正在CPU执行的顺序可能是不一致的。”,关于这句话我很疑惑。我的理解是假如有123这三条指令,CPU是不会先从内存中取出3执行再取2执行的,很多人说的运行时的“指令重排序”,其实指的是Memory Ordering[1]现象,即123三条指令对内存操作的生效次序可能是乱序的,CPU何时通过总线将寄存器、缓存中的值同步到内存中,这一动作相对于指令的执行有点像是异步的。volitale关键字通过在合适的地方插入memory barrier,保证barrier之前的指令对内存的操作都必须先于之后的指令完成,通过这种方式来保证线程间操作的可见性。
JVM的内存模型,几乎就是关于可见性的,它在各个不同硬件架构的内存模型之上为程序员提供了一个统一的内存模型,并通过一系列happens-before规则告知程序员能得到何种可见性的保证。
参考资料:
1. 《Intel® 64 and IA-32 Architectures Software Developers Manual》
The term memory ordering refers to the order in which the processor issues reads (loads) and writes (stores)
through the system bus to system memory. The Intel 64 and IA-32 architectures support several memory-ordering
models depending on the implementation of the architecture. For example, the Intel386 processor enforces
program ordering (generally referred to as strong ordering), where reads and writes are issued on the system
bus in the order they occur in the instruction stream under all circumstances.
2. 《POSIX多线程程序设计》 3.4 内存间的可视性
3. JSR 133 (Java Memory Model) FAQ : http://www.cs.umd.edu/~pugh/java/memoryModel/jsr-133-faq.html
At the processor level, a memory model defines necessary and sufficient conditions for knowing that writes to memory by other processors are visible to the current processor, and writes by the current processor are visible to other processors.
这里讲的指令重排是指“乱序执行”,当然乱序执行是在不改变执行结果的前提下(仅保证单线程下是安全的),《支撑处理器的技术》这本书上也专门关于乱序执行的介绍,个人的理解是写寄存器是编译器的动作,而编译器生成的指令指定写内存时在x86下应该是通过内存一致性模型解决一定性问题,不存在要刷缓存到内存的问题,因为在别的核需要同一个数据时会得到对应cacheline最新的数据(这也就是产生伪共享的原因)。关于指令重排和可见性的关系,我想应该有两层,1.如果读在写后面,那么在x86下是天然能保证可见的,但在IA64这样的架构下是不一定能保证的,所以使用指令“ld.acq”和“st.rel”来读和写;2.在多线程情况下,如果没有插入合适的指令,有可能不能保证某个读需要在某个写后面,所以也需要插入特定指令; 因此我个人理解是指令重排某种程度上是用来实现可见性的。
嗯,谢谢解释
你好,看完你的文章受益匪浅。你说的工作内存我之前也觉得很难理解 ,因为JVM的实现 里面好像是没有发现 这个东西,但我后来想了下,有没有可能是运行时系统 里面的运行栈?比如说getfield 指令 ?
与帖主商榷:
“volatile” — 保证读写的都是主内存的变量
<<< 关于这一点,没有“保证”。只需要保证读到变量是“之前最近一次”写入的值,其他线程也好,同一个线程也好。
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
<<< 这也是为什么只是“防止”指令重排,而没有“同步到主存”代码的原因,因为根本就不需要。"lock" 保证最新值能够在各个CPU Cache之间传递就行了,也就是volatile的属性:能够看到“最新”写入。(请参考MESI的传递过程)
如果一个数据在寄存器中,那么直接使用寄存器中的值无疑性能是最高的,但同时这也会导致可能读不到最新的值
<<< 只有寄存器参与的指令,应该不算是load/store指令吧,除非跟mem相关才算。应该是cache,因为CPU首先是把mem的数据预先加载到cache里面(cacheline),再进行操作的。
PS:
具体请参考McKenney的文章《Memory Barriers: a Hardware View for Software Hackers》(http://irl.cs.ucla.edu/~yingdi/web/paperreading/whymb.2010.06.07c.pdf)
不是运行栈,栈是一种架构在Mem上的抽象
我个人觉得可以把“工作内存”理解为CPU Cache,因为CPU采用首先把Mem内容加载进入Cache的方式工作,SMP系统中因此存在Cache coherence(https://en.wikipedia.org/wiki/Cache_coherence)
主存和工作内存 可以对应于 Mem和Cache