深入理解并行编程-分割和同步设计(四)
原文链接 作者:paul 译者:谢宝友,鲁阳,陈渝

图1.1:设计模式与锁粒度
图1.1是不同程度同步粒度的图形表示。每一种同步粒度都用一节内容来描述。下面几节主要关注锁,不过其他几种同步方式也有类似的粒度问题。
1.1. 串行程序
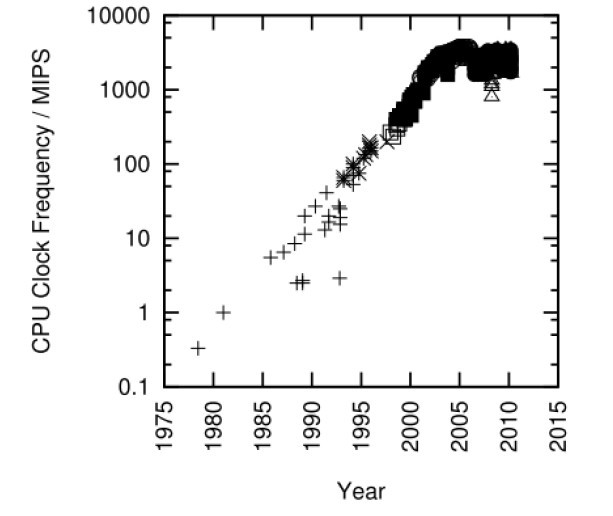
图1.2:Intel处理器的MIPS/时钟频率变化趋势
如果程序在单处理器上运行的足够快,并且不与其他进程、线程或者中断处理程序发生交互,那么您可以将代码中所有的同步原语删掉,远离它们所带来的开销和复杂性。好多年前曾有人争论摩尔定律最终会让所有程序都变得如此。但是,随着2003年以来Intel CPU的CPU MIPS和时钟频率增长速度的停止,见图1.2,此后要增加性能,就必须提高程序的并行化程度。关于是否这种趋势会导致一块芯片上集成几千个CPU的争论不会很快停息,但是考虑到Paul是在一台双核笔记本上敲下这句话的,SMP的寿命极有可能比你我都长。另一个需要注意的地方是以太网的带宽持续增长,如图1.3所示。这种增长会导致多线程服务器的产生,这样才能有效处理通信载荷。

图1.3:以太网带宽 v.s. Intel x86处理器的性能
请注意,这并不意味这您应该在每个程序中使用多线程方式编程。我再一次说明,如果一个程序在单处理器上运行的很好,那么您就从SMP同步原语的开销和复杂性中解脱出来吧。图1.4中哈希表查找代码的简单之美强调了这一点。
[code lang=”c”]
struct hash_table
{
long nbuckets;
struct node **buckets;
};
typedef struct node {
unsigned long key;
struct node *next;
} node_t;
int hash_search(struct hash_table *h, long key)
{
struct node *cur;
cur = h->buckets[key % h->nbuckets];
while (cur != NULL) {
if (cur->key >= key) {
return (cur->key == key);
}
cur = cur->next;
}
return 0;
}
[/code]
图1.4:串行版的哈希表搜索算法
1.2. 代码锁
代码锁是最简单的设计,只使用全局锁。在已有的程序上使用代码锁,可以很容易的让程序可以在多处理器上运行。如果程序只有一个共享资源,那么代码锁的性能是最优的。但是,许多较大且复杂的程序会在临界区上执行许多次,这就让代码锁的扩展性大大受限。
[code lang=”c”]
spinlock_t hash_lock;
struct hash_table
{
long nbuckets;
struct node **buckets;
};
typedef struct node {
unsigned long key;
struct node *next;
} node_t;
int hash_search(struct hash_table *h, long key)
{
struct node *cur;
int retval;
spin_lock(&hash_lock);
cur = h->buckets[key % h->nbuckets];
while (cur != NULL) {
if (cur->key >= key) {
retval = (cur->key == key);
spin_unlock(&hash_lock);
return retval;
}
cur = cur->next;
}
spin_unlock(&hash_lock);
return 0;
}
[/code]
图1.5:基于代码锁的哈希表搜索算法
因此,您最好在只有一小段执行时间在临界区程序,或者对扩展性要求不高的程序上使用代码锁。这种情况下,代码锁可以让程序相对简单,和单线程版本类似,如图1.5所示。但是,和图1.4相比,hash_search()从简单的一行return变成了3行语句,因为在返回前需要释放锁。

图1.6:锁竞争
并且,代码锁尤其容易引起“锁竞争”,一种多个CPU并发访问同一把锁的情况。照顾一群小孩子(或者像小孩子一样的老人)的SMP程序员肯定能马上意识到某样东西只有一个的危险,如图1.6所示。
该问题的一种解决办法是下节描述的“数据锁”。
1.3. 数据锁
[code lang=”c”]
struct hash_table
{
long nbuckets;
struct bucket **buckets;
};
struct bucket {
spinlock_t bucket_lock;
node_t *list_head;
};
typedef struct node {
unsigned long key;
struct node *next;
} node_t;
int hash_search(struct hash_table *h, long key)
{
struct bucket *bp;
struct node *cur;
int retval;
bp = h->buckets[key % h->nbuckets];
spin_lock(&bp->bucket_lock);
cur = bp->list_head;
while (cur != NULL) {
if (cur->key >= key) {
retval = (cur->key == key);
spin_unlock(&bp->hash_lock);
return retval;
}
cur = cur->next;
}
spin_unlock(&bp->hash_lock);
return 0;
}
[/code]
图1.7:基于数据锁的哈希表搜索算法
许多数据结构都可以分割,数据结构的每个部分带有一把自己的锁。这样虽然每个部分一次只能执行一个临界区,但是数据结构的各个部分形成的临界区就可以并行执行了。在锁竞争必须降低时,和同步开销不是主要局限时,可以使用数据锁。数据锁通过将一块过大的临界区分散到各个小的临界区来减少锁竞争,比如,维护哈希表中的per-hash-bucket临界区,如图1.7所示。不过这种扩展性的增强带来的是复杂性的提高,增加了额外的数据结构struct bucket。

图1.8:数据锁
和图1.6中所示的紧张局面不同,数据锁带来了和谐,见图1.8——在并行程序中,这总是意味着性能和可扩展性的提升。基于这种原因,Sequent在它的DYNIX和DYNIX/ptx操作系统中大量使用了数据锁[BK85][Inm85][Gar90][Dov90][MD92][MG92][MS93]。
不过,那些照顾过小孩子的人可以证明,再细心的照料也不能保证一切风平浪静。同样的情况也适用于SMP程序。比如,Linux内核维护了一种文件和目录的缓存(叫做“dcache”)。该缓存中的每个条目都有一把自己的锁,但是对应根目录的条目和它的直接后代相较于其他条目更容易被遍历到。这将导致许多CPU竞争这些热门条目的锁,就像图1.9中所示的情景。

图1.9:数据锁出现问题
在许多情况下,可以设计算法来减少数据冲突的次数,某些情况下甚至可以完全消灭冲突(像Linux内核中的dcache一样[MSS04])。数据锁通常用于分割像哈希表一样的数据结构,也适用于每个条目用某个数据结构的实例表示这种情况。2.6.17内核的task list就是后者的例子,每个任务结构都有一把自己的proc_lock锁。
在动态分配结构中,数据锁的关键挑战是如何保证在已经获取锁的情况下结构本身是否存在。图1.7中的代码通过将锁放入静态分配并且永不释放的哈希桶,解决了上述挑战。但是,这种手法不适用于哈希表大小可变的情况,所以锁也需要动态分配。在这种情况,还需要一些手段来阻止哈希桶在锁被获取后这段时间内释放。
小问题1.1:当结构的锁被获取时,如何防止结构被释放呢?
1.4. 数据所有权
数据所有权方法按照线程或者CPU的个数分割数据结构,这样每个线程/CPU都可以在不需任何同步开销的情况下访问属于它的子集。但是如果线程A希望访问另一个线程B的数据,那么线程A是无法直接做到这一点的。取而代之的是,线程A需要先与线程B通信,这样线程B以线程A的名义执行操作,或者,另一种方法,将数据迁移到线程A上来。
数据所有权看起来很神秘,但是却应用得十分频繁。
1. 任何只能被一个CPU或者一个线程访问的变量(C或者C++中的auto变量)都属于这个CPU或者这个进程。
2. 用户接口的实例拥有对应的用户上下文。这在与并行数据库引擎交互的应用程序中十分常见,这让并行引擎看起来就像顺序程序一样。这样的应用程序拥有用户接口和他当前的操作。显式的并行化只在数据库引擎内部可见。
3. 参数模拟通常授予每个线程一段特定的参数区间,以此达到某种程度的并行化。
如果共享比较多,线程或者CPU间的通信会带来较大的复杂性和通信开销。不仅如此,如果使用的最多的数据正好被一个CPU拥有,那么这个CPU就成为了“热点”,有时就会导致图1.9中的类似情况。不过,在不需要共享的情况下,数据所有权可以达到理想性能,代码也可以像图1.4中所示的顺序程序例子一样简单。最坏情况通常被称为“尴尬的并行化”,而最好情况,则像图1.8中所示一样。
另一个数据所有权的重要实例发生在数据是只读时,这种情况下,所有线程可以通过复制来“拥有”数据。
1.5锁粒度与性能
本节以一种数学上的同步效率的视角,将视线投向锁粒度和性能。对数学不敢兴趣的读者可以跳过本节。
本节的方法是用一种关于同步机制效率的粗略队列模型,该机制只操作一个共享的全局变量,基于M/M/1队列。M/M/1队列。
(本节未翻译)
…
原创文章,转载请注明: 转载自并发编程网 – ifeve.com本文链接地址: 深入理解并行编程-分割和同步设计(四)




暂无评论