同步与Java内存模型(一)序言
原文:http://gee.cs.oswego.edu/dl/cpj/jmm.html
作者:Doug Lea 译者:萧欢 校对:丁一,方腾飞
先来看如下这个简单的Java类,该类中并没有使用任何的同步。
[code lang=”java”]
final class SetCheck {
private int a = 0;
private long b = 0;
void set() {
a = 1;
b = -1;
}
boolean check() {
return ((b == 0) ||
(b == -1 && a == 1));
}
}
[/code]
如果是在一个串行执行的语言中,执行SetCheck类中的check方法永远不会返回false,即使编译器,运行时和计算机硬件并没有按照你所期望的逻辑来处理这段程序,该方法依然不会返回false。在程序执行过程中,下面这些你所不能预料的行为都是可能发生的:
- 编译器可能会进行指令重排序,所以b变量的赋值操作可能先于a变量。如果是一个内联方法,编译器可能更甚一步将该方法的指令与其他语句进行重排序。
- 处理器可能会对语句所对应的机器指令进行重排序之后再执行,甚至并发地去执行。
- 内存系统(由高速缓存控制单元组成)可能会对变量所对应的内存单元的写操作指令进行重排序。重排之后的写操作可能会对其他的计算/内存操作造成覆盖。
- 编译器,处理器以及内存系统可能会让两条语句的机器指令交错。比如在32位机器上,b变量的高位字节先被写入,然后是a变量,紧接着才会是b变量的低位字节。
- 编译器,处理器以及内存系统可能会导致代表两个变量的内存单元在(如果有的话)连续的check调用(如果有的话)之后的某个时刻才更新,而以这种方式保存相应的值(如在CPU寄存器中)仍会得到预期的结果(check永远不会返回false)。
在串行执行的语言中,只要程序执行遵循类似串行的语义,如上几种行为就不会有任何的影响。在一段简单的代码块中,串行执行程序不会依赖于代码的内部执行细节,因此如上的几种行为可以随意控制代码。这样就为编译器和计算机硬件提供了基本的灵活性。基于此,在过去的数十年内很多技术(CPU的流水线操作,多级缓存,读写平衡,寄存器分配等等)应运而生,为计算机处理速度的大幅提升奠定了基础。这些操作的类似串行执行的特性可以让开发人员无须知道其内部发生了什么。对于开发人员来说,如果不创建自己的线程,那么这些行为也不会对其产生任何的影响。
然而这些情况在并发编程中就完全不一样了,上面的代码在并发过程中,当一个线程调用check方法的时候完全有可能另一个线程正在执行set方法,这种情况下check方法就会将上面提到的优化操作过程暴露出来。如果上述任意一个操作发生,那么check方法就有可能返回false。例如,check方法读取long类型的变量b的时候可能得到的既不是0也不是-1.而是一个被写入一半的值。另一种情况,set方法中的语句的乱序执行有可能导致check方法读取变量b的值的时候是-1,然而读取变量a时却依然是0。
换句话说,不仅是并发执行会导致问题,而且在一些优化操作(比如指令重排序)进行之后也会导致代码执行结果和源代码中的逻辑有所出入。由于编译器和运行时技术的日趋成熟以及多处理器的逐渐普及,这种现象就变得越来越普遍。对于那些一直从事串行编程背景的开发人员(其实,基本上所有的程序员)来说,这可能会导致令人诧异的结果,而这些结果可能从没在串行编程中出现过。这可能就是那些微妙难解的并发编程错误的根本源头吧。
在绝大部分的情况下,有一个很简单易行的方法来避免那些在复杂的并发程序中因代码执行优化导致的问题:使用同步。例如,如果SetCheck类中所有的方法都被声明为synchronized,那么你就可以确保那么内部处理细节都不会影响代码预期的结果了。
但是在有些情况下你却不能或者不想去使用同步,抑或着你需要推断别人未使用同步的代码。在这些情况下你只能依赖Java内存模型所阐述的结果语义所提供的最小保证。Java内存模型允许上面提到的所有操作,但是限制了它们在执行语义上潜在的结果,此外还提出了一些技术让程序员可以用来控制这些语义的某些方面。
Java内存模型是Java语言规范的一部分,主要在JLS的第17章节介绍。这里,我们只是讨论一些基本的动机,属性以及模型的程序一致性。这里对JLS第一版中所缺少的部分进行了澄清。
我们假设Java内存模型可以被看作在1.2.4中描述的那种标准的SMP机器的理想化模型。
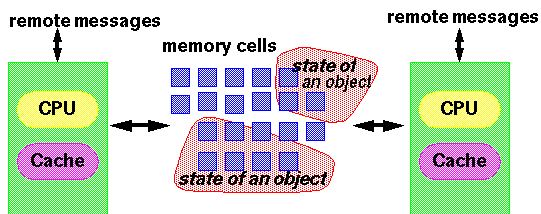
(1.2.4)
在这个模型中,每一个线程都可以被看作为运行在不同的CPU上,然而即使是在多处理器上,这种情况也是很罕见的。但是实际上,通过模型所具备的某些特性,这种CPU和线程单一映射能够通过一些合理的方法去实现。例如,因为CPU的寄存器不能被另一个CPU直接访问,这种模型必须考虑到某个线程无法得知被另一个线程操作变量的值的情况。这种情况不仅仅存在于多处理器环境上,在单核CPU环境里,因为编译器和处理器的不可预测的行为也可能导致同样的情况。
Java内存模型没有具体讲述前面讨论的执行策略是由编译器,CPU,缓存控制器还是其它机制促成的。甚至没有用开发人员所熟悉的类,对象及方法来讨论。取而代之,Java内存模型中仅仅定义了线程和内存之间那种抽象的关系。众所周知,每个线程都拥有自己的工作存储单元(缓存和寄存器的抽象)来存储线程当前使用的变量的值。Java内存模型仅仅保证了代码指令与变量操作的有序性,大多数规则都只是指出什么时候变量值应该在内存和线程工作内存之间传输。这些规则主要是为了解决如下三个相互牵连的问题:
- 原子性:哪些指令必须是不可分割的。在Java内存模型中,这些规则需声明仅适用于-—实例变量和静态变量,也包括数组元素,但不包括方法中的局部变量-—的内存单元的简单读写操作。
- 可见性:在哪些情况下,一个线程执行的结果对另一个线程是可见的。这里需要关心的结果有,写入的字段以及读取这个字段所看到的值。
- 有序性:在什么情况下,某个线程的操作结果对其它线程来看是无序的。最主要的乱序执行问题主要表现在读写操作和赋值语句的相互执行顺序上。
当正确的使用了同步,上面属性都会具有一个简单的特性:一个同步方法或者代码块中所做的修改对于使用了同一个锁的同步方法或代码块都具有原子性和可见性。同步方法或代码块之间的执行过程都会和代码指定的执行顺序保持一致。即使代码块内部指令也许是乱序执行的,也不会对使用了同步的其它线程造成任何影响。
当没有使用同步或者使用的不一致的时候,情况就会变得复杂。Java内存模型所提供的保障要比大多数开发人员所期望的弱,也远不及目前业界所实现的任意一款Java虚拟机。这样,开发人员就必须负起额外的义务去保证对象的一致性关系:对象间若有能被多个线程看到的某种恒定关系,所有依赖这种关系的线程就必须一直维持这种关系,而不仅仅由执行状态修改的线程来维持。
原文
Consider the tiny class, defined without any synchronization:
[code lang=”java”]final class SetCheck {
private int a = 0;
private long b = 0;
void set() {
a = 1;
b = -1;
}
boolean check() {
return ((b == 0) ||
(b == -1 && a == 1));
}
}[/code]
In a purely sequential language, the method check could never return false. This holds even though compilers, run-time systems, and hardware might process this code in a way that you might not intuitively expect. For example, any of the following might apply to the execution of method set:
- The compiler may rearrange the order of the statements, so b may be assigned before a. If the method is inlined, the compiler may further rearrange the orders with respect to yet other statements.
- The processor may rearrange the execution order of machine instructions corresponding to the statements, or even execute them at the same time.
- The memory system (as governed by cache control units) may rearrange the order in which writes are committed to memory cells corresponding to the variables. These writes may overlap with other computations and memory actions.
- The compiler, processor, and/or memory system may interleave the machine-level effects of the two statements. For example on a 32-bit machine, the high-order word of b may be written first, followed by the write to a, followed by the write to the low-order word of b.
- The compiler, processor, and/or memory system may cause the memory cells representing the variables not to be updated until sometime after (if ever) a subsequent check is called, but instead to maintain the corresponding values (for example in CPU registers) in such a way that the code still has the intended effect.
In a sequential language, none of this can matter so long as program execution obeys as-if-serial semantics. Sequential programs cannot depend on the internal processing details of statements within simple code blocks, so they are free to be manipulated in all these ways. This provides essential flexibility for compilers and machines. Exploitation of such opportunities (via pipelined superscalar CPUs, multilevel caches, load/store balancing, interprocedural register allocation, and so on) is responsible for a significant amount of the massive improvements in execution speed seen in computing over the past decade. The as-if-serial property of these manipulations shields sequential programmers from needing to know if or how they take place. Programmers who never create their own threads are almost never impacted by these issues.
Things are different in concurrent programming. Here, it is entirely possible for check to be called in one thread while set is being executed in another, in which case the check might be “spying” on the optimized execution of set. And if any of the above manipulations occur, it is possible for check to return false. For example, as detailed below, check could read a value for the long b that is neither 0 nor -1, but instead a half-written in-between value. Also, out-of-order execution of the statements in set may cause check to read b as -1 but then read a as still 0.
In other words, not only may concurrent executions be interleaved, but they may also be reordered and otherwise manipulated in an optimized form that bears little resemblance to their source code. As compiler and run-time technology matures and multiprocessors become more prevalent, such phenomena become more common. They can lead to surprising results for programmers with backgrounds in sequential programming (in other words, just about all programmers) who have never been exposed to the underlying execution properties of allegedly sequential code. This can be the source of subtle concurrent programming errors.
In almost all cases, there is an obvious, simple way to avoid contemplation of all the complexities arising in concurrent programs due to optimized execution mechanics: Use synchronization. For example, if both methods in class SetCheck are declared as synchronized, then you can be sure that no internal processing details can affect the intended outcome of this code.
But sometimes you cannot or do not want to use synchronization. Or perhaps you must reason about someone else’s code that does not use it. In these cases you must rely on the minimal guarantees about resulting semantics spelled out by the Java Memory Model. This model allows the kinds of manipulations listed above, but bounds their potential effects on execution semantics and additionally points to some techniques programmers can use to control some aspects of these semantics (most of which are discussed in �2.4).
The Java Memory Model is part of The JavaTM Language Specification, described primarily in JLS chapter 17. Here, we discuss only the basic motivation, properties, and programming consequences of the model. The treatment here reflects a few clarifications and updates that are missing from the first edition of JLS.
The assumptions underlying the model can be viewed as an idealization of a standard SMP machine of the sort described in �1.2.4:
For purposes of the model, every thread can be thought of as running on a different CPU from any other thread. Even on multiprocessors, this is infrequent in practice, but the fact that this CPU-per-thread mapping is among the legal ways to implement threads accounts for some of the model’s initially surprising properties. For example, because CPUs hold registers that cannot be directly accessed by other CPUs, the model must allow for cases in which one thread does not know about values being manipulated by another thread. However, the impact of the model is by no means restricted to multiprocessors. The actions of compilers and processors can lead to identical concerns even on single-CPU systems.
The model does not specifically address whether the kinds of execution tactics discussed above are performed by compilers, CPUs, cache controllers, or any other mechanism. It does not even discuss them in terms of classes, objects, and methods familiar to programmers. Instead, the model defines an abstract relation between threads and main memory. Every thread is defined to have a working memory (an abstraction of caches and registers) in which to store values. The model guarantees a few properties surrounding the interactions of instruction sequences corresponding to methods and memory cells corresponding to fields. Most rules are phrased in terms of when values must be transferred between the main memory and per-thread working memory. The rules address three intertwined issues:
- Atomicity
- Which instructions must have indivisible effects. For purposes of the model, these rules need to be stated only for simple reads and writes of memory cells representing fields – instance and static variables, also including array elements, but not including local variables inside methods.
- Visibility
- Under what conditions the effects of one thread are visible to another. The effects of interest here are writes to fields, as seen via reads of those fields.
- Ordering
- Under what conditions the effects of operations can appear out of order to any given thread. The main ordering issues surround reads and writes associated with sequences of assignment statements.
When synchronization is used consistently, each of these properties has a simple characterization: All changes made in one synchronized method or block are atomic and visible with respect to other synchronized methods and blocks employing the same lock, and processing of synchronized methods or blocks within any given thread is in program-specified order. Even though processing of statements within blocks may be out of order, this cannot matter to other threads employing synchronization.
When synchronization is not used or is used inconsistently, answers become more complex. The guarantees made by the memory model are weaker than most programmers intuitively expect, and are also weaker than those typically provided on any given JVM implementation. This imposes additional obligations on programmers attempting to ensure the object consistency relations that lie at the heart of exclusion practices: Objects must maintain invariants as seen by all threads that rely on them, not just by the thread performing any given state modification.
原创文章,转载请注明: 转载自并发编程网 – ifeve.com本文链接地址: 同步与Java内存模型(一)序言

 (8 votes, average: 4.00 out of 5)
(8 votes, average: 4.00 out of 5)

这个网上有很多译文,如果能改变下排版,看起来会舒服很多。比如我对某一句的中文读不通的时候,想看原文,就得不断的拖鼠标,然后找,或者点开另外的链接(有些文章的原文都不在同一片文章里面),然后找。
可不可以把原文和译文放在两个tab里面,或者是直接能分屏分成两栏阅读。
不知道wordpress有木有这样的主题。。。
很好的建议,的确存在这样的问题,当时想的是译文放在前面,原文放在后面。但是也不大合适。如果译文中有什么不能理解的可以直接在回复中提问吧,确实有问题我们再修改译文。这样后面阅读的人就会受益。