软件事务内存导论(一)前言
声明:本文是《Java虚拟机并发编程》的第六章,感谢华章出版社授权并发编程网站发布此文,禁止以任何形式转载此文。
请回忆一下你最近完成那个需要对共享可变变量进行同步的项目。在那个项目中,你肯定无法身心愉悦地享受出色地完成工作所带来的乐趣,而是会陷入无尽的质疑之中并抓狂地挨个确认是否在所有需要的地方都作了适当的同步。在过去所经历过的编程工作中,我已经遇到过好几次这样令人神经衰弱的情况了,而其中绝大部分原因都是由于我们在用Java编程的时候没有遵循正确原则和方法来处理共享可变状态。如果我们在某个该同步的地方忘了进行同步,那些不可预知的、潜在的灾难性的结果就将在不远处等待着我们。但是人无完人,遗忘是我们的天性。所以我们应该充分利用工具来弥补我们自身的不足,同时也可以让工具帮助我们实现我们充满创意的大脑所追求的那些伟大的目标,而不是让错误一次次地打击我们的信心。为了能够得到可控的行为和结果,我们需要再次把目光投向JDK。
在本章中,我们将会通过使用Clojure中十分流行的软件事务内存(STM)模型来学习如何线程安全地处理共享可变性(shared mutability)。在需要的时候,我们可能会在示例项目中混入Clojure的代码。但是我们并非强迫你也要使用Clojure,因为随着Multiverse和Akka这些优秀工具的出现,我们也可以在Java中直接使用STM了。在本章中,我们会先来看看STM在Clojure里是什么样子,然后再学习如何用Java和Scala对事务内存进行编程。这种编程模型非常适用于那些读多写少的程序——它简单易用并能提供可预测的结果。
1.1 同步与并发水火不容
同步操作本身就存在一些很基本的缺陷。
如果我们没能处理好或干脆就忘了进行同步,则某个线程所做的更改可能无法被其他线程及时感知。此外,为了同时保证可见性并避免竞争条件,我们还需要通过一些很麻烦的手段来进行同步操作。
不幸的是,当我们执行同步操作的时候,同时也强制了其他竞争相同资源的线程只能等待。由于同步的粒度对并发度是有很大影响的,所以将同步控制的工作完全交由程序员来完将成会大大降低程序整体效率并增加错误发生的几率。
同步操作还可能引发很多活跃度方面的问题。由于某个线程可能吃着碗里的看着锅里的,所以很容易造成程序死锁。此外,同步还很容易造成活锁(livelock)问题,即线程可能会在申请某一把锁的时候不断遭遇失败。
当然,我们可以尝试使用细粒度的锁来提高程序并发度。虽然一般来说这个主意还不错,但是其中最大的风险是程序员可能没在合适的层级进行同步动作,因为这太依赖于程序员的素质和责任心了。更糟的是,同步出问题的时候我们还收不到任何提示。此外,因为需要互斥访问的线程加了锁之后还是会阻塞其他线程的访问请求,所以细粒度的锁只是把线程等待的位置换了个地方而已。
熟练掌握JDK并发工具包的Java程序员在大城市里一般都混的不错。而且由于这么长时间以来,我们在处理可变状态的编程方面都没能找到一个比同步更合适的替代产品,所以导致了我们在这方面的预期一直在不断下降。但是新的编程模型终于还是到来了!
1.2 对象模型的缺陷
作为一个Java程序员,我们对面向对象的编程(OOP)自然都是烂熟于胸的,但语言也极大地影响了我们构建面向对象应用程序的方式。现在的OOP已经和Alan Kay当初创造这个词时候的初衷大不相同了。他的主要思想是采用消息传递并消灭所有状态数据(他认为,系统是由一些类似于生物细胞那样的对象构成的,这些对象通过消息传递进行通信,且无需持有任何状态)——见附录2中《面向对象编程的意义》一书。随着这一技术的演进,面向对象的语言开始朝着通过抽象数据类型(ADTs)来实现数据隐藏(data hiding)的方向发展,并将数据和处理过程绑定或将状态与行为组合在一起。这在很大程度上引领我们走向封装和不断变化的状态。在这个过程中,我们最终还是把状态与实体(identity)进行了融合,即把对象实例与其数据整合在一起。
对于Java程序员来说,实体与状态的融合是在潜移默化间悄悄完成的。当我们顺着指针或引用找到某个实例的时候,实际上是登录到了持有其状态的一块内存上,于是在那个位置上操纵数据也就成了自然而然的事了。该位置即代表了对象实例及其所包含的数据。将实体与状态进行合并最初看起来是非常简单且易于理解的,但从并发的角度来看,这种做法其实有很多严重的不良后果。例如,如果我们需要实现一个打印银行账户详情(资金数量、当前余额、交易信息、最小余额等等)的程序,我们就会碰到很多并发相关的问题。你会发现手头待处理的引用其实是一个随时都可能发生变化的状态的代理。所以当我们查看账户信息的时候,就需要通过加锁来阻止其他线程对账户内容进行修改,而这也必将导致并发度的大幅下降。但问题并不是从加锁的那一刻才开始出现的,而是在我们把账户的实体与其状态合并的时候就已经存在了。
我们曾经被告知说面向对象的编程是对真实世界的建模。但悲催的是,真实世界与OO范式所试图构建的模型实际是大相径庭的。因为在真实的世界中,状态是不变的,而实体却是不断变化的。接下来我们将讨论这种说法为何是正确的。
1.3 将实体与状态分离
你能快速告诉我Google的股价现在是多少吗?我们当然可以说从证券市场开市的那一刻起股价就是在不断变化的,但这只不过是一种文字游戏罢了。举一个简单的例子,2010年12月10日Google的收盘价是592美元,并且这个数字已经被载入史册、是不会再改变了。而我们所要查找的只是Google股价当时的一个快照。当然,Google今天的股价和那天已经完全不同了。而如果过几分钟之后再来查看Google的股价(假设证券市场是开市的),我们就会看到一个不一样的值,但之前的那个值其实并没有改变。从现在开始,我们得改变一下我们对对象的认识,而这也将同时改变我们使用对象的方式。后面我们会看到,把对象的实体与其不可变状态值进行分离的做法将如何帮助我们实现锁无关(lock-free)编程、提高并发度、同时最大程度地降低竞争。
将实体与状态分离绝对是一个天才的构想,这是Rich Hickey在其实现Clojure的STM模型过程中所采用的一个非常关键的步骤,详情请见附录2中的“值与变化—Clojure处理实体和状态的方法”。假定我们的Google股票对象由两部分组成:第一部分用于表示该股的实体,其中包含一个指向第二部分的指针。第二部分则包含了该股最新股价,其中保存股价的变量即为不可变状态,如图 6‑1所示。
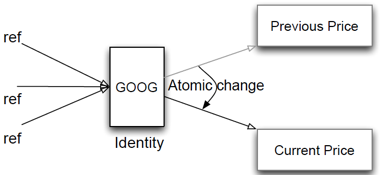 |
|
图 6‑1 将可变实体部分与不可变状态值进行分离 |
一旦接收到一个新的股价信息,我们就可以在不更改任何已存在事务的情况下将其放入历史价格指数中。由于旧的股价是不可变的,所以我们可以将其共享出去供所有线程访问。正如我们在3.6节中所讨论的那样,如果我们在这里采用持久化数据结构的话,则Google股票对象就可以多快好省地对外提供数据读取服务。而一旦有新的数据准备就绪之后,我们可以快速更改实体中的指针,以使其指向保存新股价的字段。
实体与状态分离的做法对于并发来说也是一大福音。因为采用了这种方法之后,我们就可以不用阻塞任何查询股价的请求了。由于状态是不会变的,所以我们可以欣然将其指针传递给发出查询请求的线程。所有在我们更新实体(内部的指针——译者注)之后到达的查询请求都可以看到更新后的股价。我们知道,非阻塞的读操作即意味着更高的并发度,所以我们只需要确保每个线程都能获得一致的视图即可。而这其中最棒的是,我们其实什么也不用做,STM已经帮我们都搞定了。相信你已经迫不及待想要了解更多关于STM的知识了吧?下面就让我们一起来学习这方面的内容。
(未完待续)
原创文章,转载请注明: 转载自并发编程网 – ifeve.com本文链接地址: 软件事务内存导论(一)前言





支持一下!
STM,貌似不错,期待下一篇文章!
前不久才买了这本书,正在学习中
据说这书翻译问题挺多的
有问题,大家一起来校对
讲的不错
一旦接收到一个新的股价信息,我们就可以在不更改任何已存在事务的情况下将其放入历史价格指数中。由于旧的股价是不可变的,所以我们可以将其共享出去供所有线程访问。正如我们在3.6节中所讨论的那样,如果我们在这里采用持久化数据结构的话,则Google股票对象就可以多快好省地对外提供数据读取服务。而一旦有新的数据准备就绪之后,我们可以快速更改实体中的指针,以使其指向保存新股价的字段。
—————————————
这个有点不太明白,这个是怎么实现的呢。和普通的数据库写入再读取有什么差别吗?有具体的代码例子吗?求解