Reactive(响应式)编程-Reactor
Reactor 是Reactive Programming规范的一个具体实现(rxjava也是规范的一个实现),
可以概括为:
反应式编程是一种涉及数据流和变化传播的异步编程范例。这意味着可以通过所采用的编程语言轻松地表达静态(例如阵列)或动态(例如事件发射器)数据流。
作为反应式编程方向的第一步,Microsoft在.NET生态系统中创建了Reactive Extensions(Rx)库。然后RxJava在JVM上实现了响应式编程。随着时间的推移,通过Reactive Streams工作出现了Java的标准化,这一规范定义了JVM上的反应库的一组接口和交互规则。它的接口已经在父类Flow下集成到Java 9中。
另外Java 8还引入了Stream,它旨在有效地处理数据流(包括原始类型),这些数据流可以在没有延迟或很少延迟的情况下访问。它是基于拉的,只能使用一次,缺少与时间相关的操作,并且可以执行并行计算,但无法指定要使用的线程池。但是它还没有设计用于处理延迟操作,例如I / O操作。其所不支持的特性就是Reactor或RxJava等Reactive API的用武之地。
Reactor 或 Rxjava等反应性API也提供Java 8 Stream等运算符,但它们更适用于任何流序列(不仅仅是集合),并允许定义一个转换操作的管道,该管道将应用于通过它的数据,这要归功于方便的流畅API和使用lambdas。它们旨在处理同步或异步操作,并允许您缓冲,合并,连接或对数据应用各种转换。
首先考虑一下,为什么需要这样的异步反应式编程库?现代应用程序可以支持大量并发用户,即使现代硬件的功能不断提高,现代软件的性能仍然是一个关键问题。
人们可以通过两种方式来提高系统的能力:
- 并行化:使用更多线程和更多硬件资源。
- 在现有资源的使用方式上寻求更高的效率。
通常,Java开发人员使用阻塞代码编写程序。这种做法很好,直到出现性能瓶颈,此时需要引入额外的线程。但是,资源利用率的这种扩展会很快引入争用和并发问题。
更糟糕的是,会导致浪费资源。一旦程序涉及一些延迟(特别是I / O,例如数据库请求或网络调用),资源就会被浪费,因为线程(或许多线程)现在处于空闲状态,等待数据。
所以并行化方法不是灵丹妙药,获得硬件的全部功能是必要的。
第二种方法,寻求现有资源的更高的使用率,可以解决资源浪费问题。通过编写异步,非阻塞代码,您可以使用相同的底层资源将执行切换到另一个活动任务,然后在异步处理完成后返回到当前线程进行继续处理。
但是如何在JVM上生成异步代码?Java提供了两种异步编程模型:
- CallBacks:异步方法没有返回值,但需要额外的回调参数(lambda或匿名类),在结果可用时调用它们。
- Futures:异步方法立即返回Future 。异步线程计算任务结果,但Future对象包装对它的访问。该值不会立即可用,并且可以轮询对象,直到该值可用。例如,运行Callable 任务的ExecutorService使用Future对象。
但是上面两种方法都有局限性。首先多个callback难以组合在一起,很快导致代码难以阅读以及难以维护(称为“Callback Hell”):
考虑下面一个例子:在用户的UI上展示用户喜欢的top 5个商品的详细信息,如果不存在的话则调用推荐服务获取5个;这个功能的实现需要三个服务支持:一个是获取用户喜欢的商品的ID的接口(userService.getFavorites),第二个是获取商品详情信息接口(favoriteService.getDetails),第三个是推荐商品与商品详情的服务(suggestionService.getSuggestions),基于callback模式实现上面功能代码如下:

- 我们的三个服务接口都是基于callback的,当异步任务执行完毕后,如果结果正常则会调用callback的onSuccess方法,如果结果异常则会调用onError方法。
- 代码1中我们调用了userService.getFavorites接口来获取用户userId的推荐商品id列表,如果获取结果正常则会调用代码2,如果失败则会调用代码7,通知用户UI错误信息。
- 如果正常则会执行代码3判断推荐商品id列表是否为空,如果是的话则执行代码4调用推荐商品与商品详情的服务(suggestionService.getSuggestions),如果获取商品详情失败则执行代码7callback的OnError把错误信息显示到用户UI,否则如果成功则执行代码5切换线程到UI线程,在获取的商品详情列表上施加jdk8 stream运算使用limit获取5个元素,然后显示到UI上。
- 代码3如果判断用户推荐商品id列表不为空则执行代码8,在商品id列表上使用JDK8 stream获取流,然后使用limit获取5个元素,然后执行代码9调用favoriteService.getDetails服务获取具体商品的详情,这里多个id获取详情是并发进行的,当获取到详情成功后会执行代码10在UI线程上绘制出商品详情信息,如果失败则执行代码11显示错误。
如上为了实现该功能,我们写了很多代码,使用了大量callback,这些代码比较晦涩难懂,并且存在代码重复,下面我们使用Reactor来实现等价的功能:
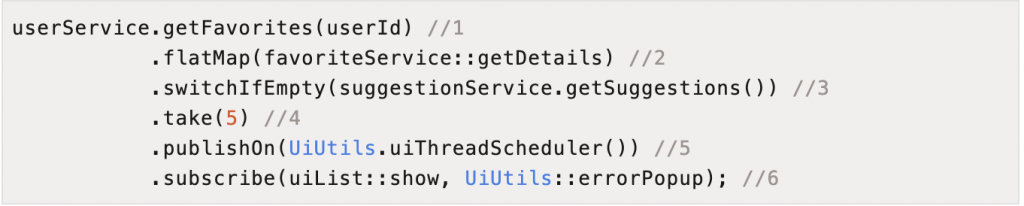
- 代码1调用getFavorites服务获取userId对应的商品列表,该方法会马上返回一个流对象,然后代码2在流上施加flatMap运算把每个商品id转换为商品Id对应的商品详情信息(通过调用服务favoriteService::getDetails),由于方法getDetails是异步的,所以flatmap实际上实现了同步转异步,然后把所有商品详情信息组成新的流返回。
- 代码3判断如果返回的流中没有元素则调用suggestionService.getSuggestions()服务获取推荐的商品详情列表,代码4则从代码2或者代码3返回的流中获取5个元素(5个商品详细信息),然后执行代码5publishOn把当前线程切换到UI调度器来执行,代码6则通过subscribe方法激活整个流处理链,然后在UI线程上绘制商品详情列表或者显示错误。
如上代码可知基于reactor编写的代码逻辑属于声明式编程,比较通俗易懂,代码量也比较少,不含有重复的代码。
future相比callback要好一些,但尽管CompletableFuture在Java 8上进行了改进,但它们仍然表现不佳。一起编排多个future是可行但是不容易的,它们不支持延迟计算(比如rxjava中的defer操作)和高级错误处理,例如下面例子。考虑另外一个例子:首先我们获取一个id列表,然后根据id分别获取对应的name和统计数据,然后组合每个id对应的name和统计数据为一个新的数据,最后输出所有组合对的值,下面我们使用CompletableFuture来实现这个功能,以便保证整个过程是异步的,并且每个id对应的处理是并发的:
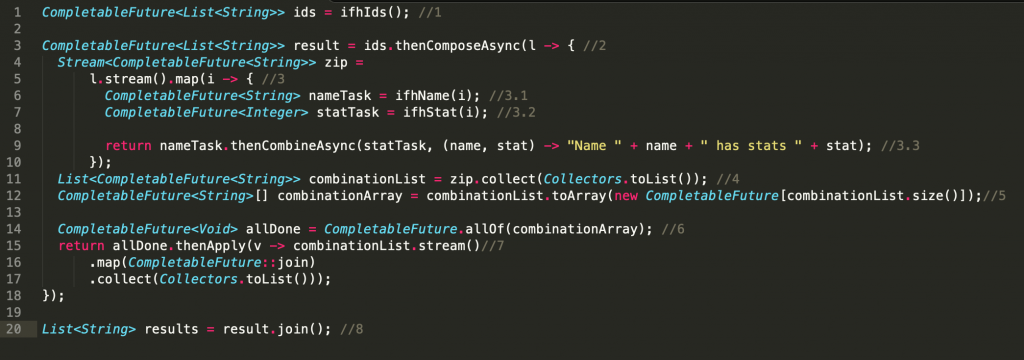
- 如上代码1我们调用ifhIds方法异步返回了一个CompletableFuture对象,其内部保存了id列表
- 代码2调用ids的thenComposeAsync方法返回一个新的CompletableFuture对象,新CompletableFuture对象的数据是代码2中的lambda表达式执行结果,表达式内代码3获取id列表的流对象,然后使用map操作把id元素转换为name与统计信息拼接的字符串,这里是通过代码3.1根据id获取name对应的CompletableFuture对象,代码3.2获取统计信息对应的CompletableFuture,然后使用代码3.3把两个CompletableFuture对象进行合并做到的。
- 代码3会返回一个流对象,其中元素是所有id对应的name与统计信息组合后的结果,然后代码4把流中元素收集保存到了combinationList列表里面。代码5把列表转换为了数组,这是因为代码2的allOf操作符的参数必须为数组。
- 代码6把combinationList列表中的所有CompletableFuture对象转换为了一个allDone(等所有CompletableFuture对象的任务执行完毕),到这里我们调用allDone的get()方法就可以等待所有异步处理执行完毕,但是我们目的是想获取到所有异步任务的执行结果,所以代码7在allDone上施加了thenApply运算,意在等所有任务处理完毕后调用所有CompletableFuture的join方法获取每个任务的执行结果,然后收集为列表后返回一个新的CompletableFuture对象,然后代码8在新的CompletableFuture上调用join方法获取所有执行结果列表。
Reactor本身提供了更多的开箱即用的操作符,使用Reactor来实现上面功能代码如下:

F
- 如上代码1我们调用ifhIds方法异步返回了一个Flux对象,其内部保存了id列表
- 代码2调用ids的flatMap方法对其中元素进行转换,代码2.1根据id获取name信息(返回流对象Mono),代码2.2 根据id获取统计信息(返回流对象Mono),代码3 结合两个流为新的流元素。
- 代码3调用新流的collectList方法把所有的流对象转换为列表,然后返回一个新的Mono流对象。
- 代码4 则调用新的Mono流对象的block方法阻塞获取所有执行结果。
如上代码使用reactor方式编写的代码相比使用CompletableFuture实现相同功能来说,更简洁,更通俗易懂。
Callback和Future的这些弊病是相似的,而响应式编程正是使用发布者 – 订阅者方式来解决这些问题的。
诸如Reactor之类的反应库旨在解决JVM上“经典”异步方法的这些缺点,同时还关注一些其他方面:
- 可组合性和可读性
- 数据作为一个用丰富的运算符词汇表操纵的流程
- 在您订阅之前没有任何事情发生
- 背压或消费者向生产者发出信号反馈发出信号过快的能力
- 高级但高价值的抽象,与并发无关
可组合性,指的是编排多个异步任务的能力,使用先前任务的结果作为后续任务的输入或以fork-join方式执行多个任务。
编排任务的能力与代码的可读性和可维护性紧密相关。随着异步过程层数量和复杂性的增加,能够编写和读取代码变得越来越困难。正如我们所看到的,callback模型很简单,但其主要缺点之一是,对于复杂的处理,您需要从回调执行回调,本身嵌套在另一个回调中,依此类推。那个混乱被称为Callback Hell,正如你可以猜到的(或者从经验中得知),这样的代码很难回归并推理。
Reactor提供了丰富的组合选项,其中代码反映了抽象过程的组织,并且所有内容通常都保持在同一级别(嵌套最小化)。
您可以将响应式应用程序处理的数据视为在装配线中移动。Reactor既是传送带又是工作站。原材料从源(原始发布者)注入,最终作为成品准备推送给消费者(或订阅者)。
原材料可以经历各种转换和其他中间步骤,或者是将中间元素聚集在一起形成较大装配线的一部分。如果在装配线中某一点出现堵塞,受影响的工作站可向上游发出信号以限制原材料的向下流动。
在Reactor中,运算符是我们装配线中类比的工作站。每个运算符都会向发布者添加行为,并将上一步的发布者包装到新实例中。因此链接整个链,使得数据源自第一个发布者并沿着链向下移动,由每个链点进行转换。最终,订阅者订阅该流,然后激活完成该过程。需要注意,在订阅者订阅发布者之前没有任何事情发生。
虽然Reactive Streams规范根本没有指定运算符,但Reactor或者rxjava等反应库的最佳附加值之一是它们提供的丰富的运算符。这些涉及很多方面,从简单的转换和过滤到复杂的编排和错误处理。
在Reactor中,当您编写Publisher链时,默认情况下数据不会启动。相反,您可以创建异步过程的抽象描述(这可以帮助重用和组合)。
通过订阅操作,您可以将发布者绑定到订阅者,从而触发整个链中的数据流。这是通过订阅者发出的单个请求信号在内部实现的,该请求信号在上游传播,一直返回到源发布者。
上游传播信号也用于实现背压,我们在装配线中将其描述为当工作站比上游工作站处理速度慢时向上游线路发送的反馈信号。
Reactive Streams规范定义的真正机制非常接近于下面的类比:订阅者可以在无限制模式下工作,让生产者以最快的速度推送所有数据,或者它可以使用请求机制向生产者发送信号通知它准备处理最多n个元素。
施加到源的中间操作符也可以在途中更改请求。想象一个缓冲区运算符,它以10个批次对元素进行分组。如果订阅者请求1个缓冲区,则源可以生成10个元素。一些生产者还实施预取策略,这避免了往返的request(1),并且如果在请求之前生成元素并不太昂贵,则预取是很有益的。
这将推模型转换为推拉式混合模式,如果上游生产了很多元素,则下游可以从上游拉出n个元素。但是如果元素没有准备好,就会在上游生产出元素后推数据到下游。
本文主要翻译自https://projectreactor.io/docs/core/release/reference/index.html#intro-reactive并融入作者自己的理解
更多技术分享,欢迎关注微信公众号:技术原始积累

原创文章,转载请注明: 转载自并发编程网 – ifeve.com本文链接地址: Reactive(响应式)编程-Reactor

 (7 votes, average: 4.43 out of 5)
(7 votes, average: 4.43 out of 5)

reactor是真正的异步吗?个人理解reactor只是把耗时操作放入另外一个线程池,在线程池内部还是阻塞的,与异步http这种真正的基于nio的还是有差距的