深入理解并行编程-分割和同步设计(二)
原文链接 作者:paul 译者:谢宝友,鲁阳,陈渝
双端队列是一种元素可以从两端插入或删除的数据结构[Knu73]。据说实现一种基于锁的允许在双端队列的两端进行并发操作的方法非常困难[Gro07]。本节将展示一种分割设计策略,能实现合理且简单的解决方案,请看下面的小节中的三种通用方法。
1.1. 右手锁和左手锁
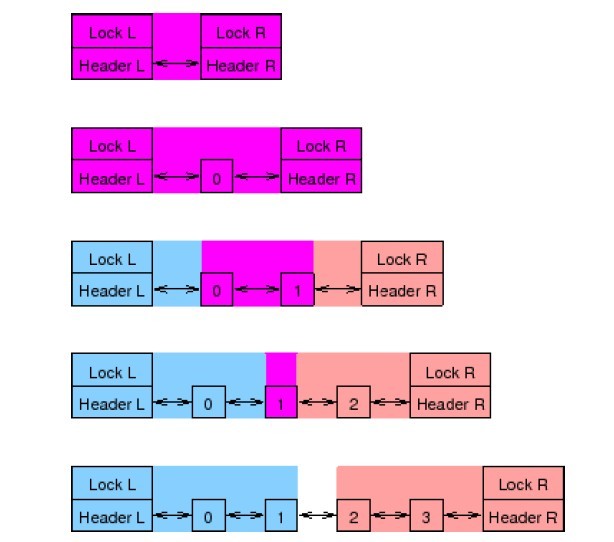
图1.1:带有左手锁和右手锁的双端队列
右手锁和左手锁是一种看起来很直接的办法,为左手端的入列操作加一个左手锁,为右手端的出列操作加一个右手锁,如图1.1所示。但是,这种办法的问题是当队列中的元素不足四个时,两个锁的范围会发生重叠。这种重叠是由于移除任何一个元素不仅只影响元素本身,还要影响它左边和右边相邻的元素。这种范围在图中被涂上了颜色,蓝色表示左手锁的范围,红色表示右手锁的范围,紫色表示重叠的范围。虽然创建这样一种算法是可能的,但是至少要小心5种特殊情况,尤其是在队列另一端的并发活动会让队列随时可能从一种特殊情况变为另一种特殊情况。所以最好还是考虑考虑其他解决方案。
1.2. 复合双端队列
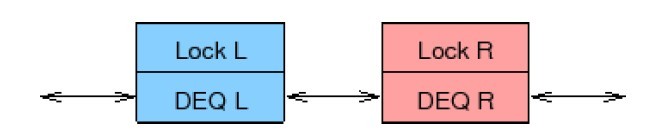
图1.2:复合双端队列
图1.2是一种强制锁范围不重叠的办法。两个单独的双端队列串联在一起,每个队列用自己的锁保护。这意味着数据偶尔会从一个双端队列跑到另一个双端队列。此时必须同时持有两把锁。为避免死锁,可以使用一种简单的锁层级关系,比如,在获取右手锁前先获取左手锁。这比在同一双端队列上用两把锁简单的多,因为我们可以无条件地让左边的入列元素进入左手队列,右边的入列元素进入右手队列。主要的复杂度来源于从空队列中出列,在这种情况下必须: 1. 如果持有右手锁,释放并获取左手锁,重新检查队列是否仍然为空。 2. 获取右手锁。 3. 重新平衡穿过两个队列的元素。 4. 移除指定的元素。 5. 释放两把锁。
小问题1.1: 在复合双端队列实现中,如果队列在释放和获取锁时变的不为空,那么该怎么办? 重新平衡操作可能会将某个元素在两个队列间来回移动,这不仅浪费时间,而且想要获得最佳性能,还需针对工作负荷进行不断微调。虽然这在一些情况下可能是最佳方案了,但是带着更大的雄心,我们还将继续探索其它算法。
1.3. 哈希双端队列
哈希永远是分割一个数据结构的最简单和最有效的方法。可以根据元素在队列中的位置为每个元素分配一个序号,然后以此对双端队列进行哈希,这样第一个从左边进入空队列的元素编号为0,第一个从右边进入空队列的元素编号为1。其他从左边进入只有一个元素的队列的元素则递减的编号(-1,-2,-3,…),而其他从右边进入只有一个元素的队列的元素则递增的编号(2,3,4,…)。关键的是,实际上不用真正的为元素编号,元素的序号暗含在它在队列中的位置中。
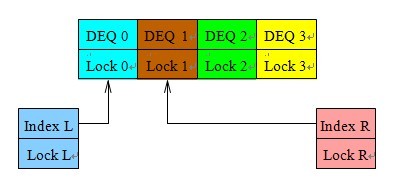
图1.3:哈希双端队列
我们用一个锁保护左手的下标,用另一个锁保护右手的下标,再各用一个锁保护对应的哈希链表。图1.3显示了四个哈希链表的数据结构。注意到锁的范围没有重叠,为了避免死锁,只在获取链表锁之前获取下标锁,每种类型的锁(下标或者链表)每次从不获取超过一个。
每个哈希链表都是一个双端队列,在这里的例子中,每个链表都holds every fourth element。图1.4中最上面的部分是“R1”元素从右边入队后的状态,右手的下标增加,用来引用哈希链表2。图中中间部分是又有三个元素从右边入队。正如您见到的那样,下标回到了它们初始的状态,但是每个哈希队列现在是非空的了。图中下方部分是另外三个元素从左边入队,而另外一个元素从右边入队后的状态。

图1.4:插入后的哈希双端队列
从图1.4中最后一个状态可以看出,左出队操作将返回元素“L-2”,让左手下标指向哈希链2,此时该链表只剩下“R2”。在这种状态下,并发的左入队操作和右入队操作可能会导致锁竞争,但这种锁竞争发生的可能性可以通过使用更大的哈希表来降低。
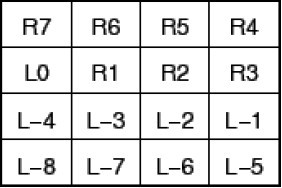
图1.5:12个元素的哈希双端队列
图1.5显示了12个元素如何组成一个有4个并行哈希桶的双端队列。
[code lang=”c”]
struct pdeq {
spinlock_t llock;
int lidx;
spinlock_t rlock;
int ridx;
struct deq bkt[DEQ_N_BKTS];
};
[/code]
图1.6:基于锁的并行双端队列数据结构
图1.6显示了对应的C语言数据结构,假设已有struct deq来提供带有锁的双端队列实现。这个数据结构包括第2行的左手锁,第3行的左手下标,第4行的右手锁,第5行的右手下标,以及第6行的哈希后的基于简单锁实现的双端队列数组。高性能的实现当然还会使用填充或者是特殊对齐指令来避免false sharing(http://en.wikipedia.org/wiki/False_sharing)。
[code lang=”c”]
struct element *pdeq_dequeue_l(struct pdeq *d)
{
struct element *e;
int i;
spin_lock(&d->llock);
i = moveright(d->lidx);
e = deq_dequeue_l(&d->bkt[i]);
if (e != NULL)
d->lidx = i;
spin_unlock(&d->llock);
return e;
}
void pdeq_enqueue_l(struct element *e, struct pdeq *d)
{
int i;
spin_lock(&d->llock);
i = d->lidx;
deq_enqueue_l(e, &d->bkt[i]);
d->lidx = moveleft(d->lidx);
spin_unlock(&d->llock);
}
struct element *pdeq_dequeue_r(struct pdeq *d)
{ struct element *e;
int i;
spin_lock(&d->rlock);
i = moveleft(d->ridx);
e = deq_dequeue_r(&d->bkt[i]);
if (e != NULL)
d->ridx = i;
spin_unlock(&d->rlock);
return e;
}
void pdeq_enqueue_r(struct element *e, struct pdeq *d)
{
int i;
spin_lock(&d->rlock);
i = d->ridx;
deq_enqueue_r(e, &d->bkt[i]);
d->ridx = moveright(d->lidx);
spin_unlock(&d->rlock);
}
[/code]
图1.7:基于锁的并行双端队列实现代码
图1.7显示了入队和出队函数。讨论将集中在左手操作上,因为右手的操作都是源于左手操作。
第1-13行是pdeq_dequeue_l()函数,从左边出队,如果成功返回一个元素,如果失败返回NULL。第6行获取左手自旋锁,第7行计算要出队的下标。第8行让元素出队,如果第9行发现结果不为NULL,第10行记录新的左手下标。不管结果为何,第11行释放锁,最后如果曾经有一个元素,第12行返回这个元素,否则返回NULL。
第15-24行是pdeq_enqueue_l()函数,从左边入队一个特定元素。第19行获取左手锁,第20行pick up左手下标。第21行让元素从左边入队,进入一个以左手下标标记的双端队列。第22行更新左手下标,最后第23行释放锁。
和之前提到的一样,右手操作完全是对对应的左手操作的模拟。
小问题1.2:哈希过的双端队列是一种好的解决方法吗?如果对,为什么对?如果不对,为什么不对?
1.4. 再次回到复合双端队列
本节再次回到复合双端队列,准备使用一种重新平衡机制来将非空队列中的所有元素移动到空队列中。
小问题1.3:让所有元素进入空的队列?这种脑残的方法是哪门子最优方案啊???
相比上一节提出的哈希式实现,复合式实现建立在对既不使用锁也不使用原子操作的双端队列的顺序实现上。
[code lang=”c”]
struct list_head *pdeq_dequeue_l(struct pdeq *d)
{
struct list_head *e;
int i;
spin_lock(&d->llock);
e = deq_dequeue_l(&d->ldeq);
if (e == NULL) {
spin_lock(&d->rlock);
e = deq_dequeue_l(&d->rdeq);
list_splice_init(&d->rdeq.chain, &d->ldeq.chain);
spin_unlock(&d->rlock);
}
spin_unlock(&d->llock);
return e;
}
struct list_head *pdeq_dequeue_r(struct pdeq *d)
{
struct list_head *e;
int i;
spin_lock(&d->rlock);
e = deq_dequeue_r(&d->rdeq);
if (e == NULL) {
spin_unlock(&d->rlock);
spin_lock(&d->llock);
spin_lock(&d->rlock);
e = deq_dequeue_r(&d->rdeq);
if (e == NULL) {
e = deq_dequeue_r(&d->ldeq);
list_splice_init(&d->ldeq.chain, &d->rdeq.chain);
}
spin_unlock(&d->llock);
}
spin_unlock(&d->rlock);
return e;
}
void pdeq_enqueue_l(struct list_head *e, struct pdeq *d)
{
int i;
spin_lock(&d->llock);
deq_enqueue_l(e, &d->ldeq);
spin_unlock(&d->llock);
}
void pdeq_enqueue_r(struct list_head *e, struct pdeq *d)
{
int i;
spin_lock(&d->rlock);
deq_enqueue_r(e, &d->rdeq);
spin_unlock(&d->rlock);
}
[/code]
图1.8:复合并行双端队列的实现代码
图1.8展示了这个实现。和哈希式实现不同,复合式实现是非对称的,所以我们必须单独考虑pdeq_dequeue_l()和pdeq_dequeue_r()的实现。
小问题1.4:为什么复合并行双端队列的实现不能是对称的?
图1.8第1-16行是pdeq_dequeue_l()的实现。第6行获取左手锁,第14行释放。第7行尝试从双端队列的左端左出列一个元素,如果成功,跳过第8-13行,直接返回该元素。否则,第9行获取右手锁,第10行从队列右端左出列一个元素,第11行将右手队列中剩余元素移至左手队列,第12行释放右手锁。如果有的话,最后将返回第10行出列的元素。
图1.8第18-38行是pdeq_dequeue_r()的实现。和之前一样,第23行获取右手锁(第36行释放),第24行尝试从右手队列右出列一个元素,如果成功,跳过第24-35行,直接返回该元素。但是如果第25行发现没有元素可以出列,那么第26行释放右手锁,第27-28行以恰当的顺序获取左手锁和右手锁。然后第29行再一次尝试从右手队列右出列一个元素,如果第30行发现第二次尝试也失败了,第31行从左手队列(假设只有一个元素)右出列一个元素,第32行将左手队列中的剩余元素移至右手队列。最后,第34行释放左手锁。
小问题1.5:为什么图5.11中第29行的重试右出列操作是必须的?
小问题1.6:可以肯定的是,左手锁必须在某些时刻是可用的!!!那么,为什么图5.11中第26行的无条件释放右手锁是必须的?
图1.8中第40-47行是pdeq_enqueue_l()的实现。第44行获取左手自旋锁,第45行将元素左入列到左手队列,最后第46行释放自旋锁。pdeq_enqueue_r(图中第49-56)的实现和此类似。
1.5. 关于双端队列的讨论
复合式实现在某种程度上比第1.3节所描述的哈希式实现复杂,但是仍然属于比较简单的。当然,更智能的重新平衡机制可能更加复杂,但是这里展现的简单机制和另一种软件[DCW+11]相比,已经执行的很好了,即使和使用硬件辅助的算法[DLM+10]相比也是如此。不过,从这种机制中我们最好也只能获得2x的扩展能力,因为最多只能有两个线程并发地持有出列的锁。 关键点在于从共享队列中入列或者出列的巨大开销。
1.6. 关于分割问题示例的讨论
在深入理解并行编程-分割和同步设计(一)第1.1节的小问题中,关于哲学家就餐问题最优解法的答案是“水平”并行化或者“数据并行化”的极佳例子。在这个例子中,同步开销接近于0(或者就是)。相反,双端队列的实现是“垂直并行化”或者“管道”的极佳例子,因为数据从一个线程转移到另一个线程。管道需要密切的合作,因此需要更多的工作来获得某种程度的效率。
小问题1.7:串联双端队列比哈希双端队列运行快两倍,即使我将哈希表大小增加到非常大也是如此。为什么会这样?
小问题1.8:有没有一种更好的方法,能并发地处理双端队列?
这两个例子显示了分割在并行算法上的巨大威力。但是,这些例子还渴求更多和更好的并行程序设计准则,下一篇文章将讨论此话题。
原创文章,转载请注明: 转载自并发编程网 – ifeve.com本文链接地址: 深入理解并行编程-分割和同步设计(二)




暂无评论