原文地址:http://ifeve.com/disruptor-padding/
作者:Trisha 译者:方腾飞 校对:丁一
我们经常提到一个短语Mechanical Sympathy,这个短语也是Martin博客的标题(译注:Martin Thompson),Mechanical Sympathy讲的是底层硬件是如何运作的,以及与其协作而非相悖的编程方式。
我在上一篇文章中提到RingBuffer后,我们收到一些关于RingBuffer中填充高速缓存行的评论和疑问。由于这个适合用漂亮的图片来说明,所以我想这是下一个我该解决的问题了。
(译注:Martin Thompson很喜欢用Mechanical Sympathy这个短语,这个短语源于赛车驾驶,它反映了驾驶员对于汽车有一种天生的感觉,所以他们对于如何最佳的驾御它非常有感觉。)
计算机入门
我喜欢在LMAX工作的原因之一是,在这里工作让我明白从大学和A Level Computing所学的东西实际上还是有意义的。做为一个开发者你可以逃避不去了解CPU,数据结构或者大O符号 —— 而我用了10年的职业生涯来忘记这些东西。但是现在看来,如果你知道这些知识并应用它,你能写出一些非常巧妙和非常快速的代码。
因此,对在学校学过的人是种复习,对未学过的人是个简单介绍。但是请注意,这篇文章包含了大量的过度简化。
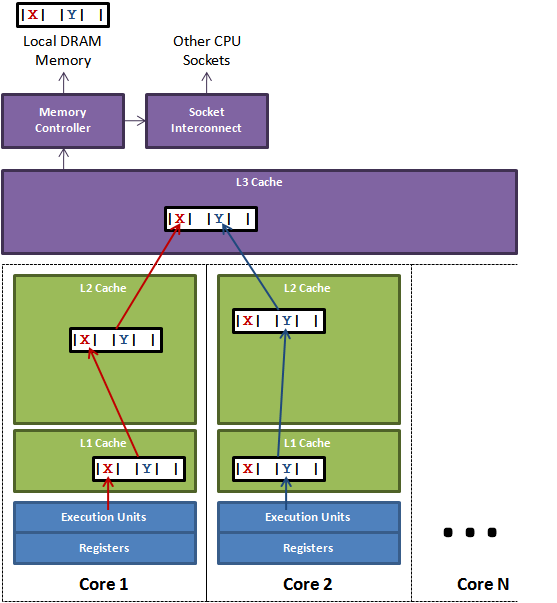
CPU是你机器的心脏,最终由它来执行所有运算和程序。主内存(RAM)是你的数据(包括代码行)存放的地方。本文将忽略硬件驱动和网络之类的东西,因为Disruptor的目标是尽可能多的在内存中运行。
CPU和主内存之间有好几层缓存,因为即使直接访问主内存也是非常慢的。如果你正在多次对一块数据做相同的运算,那么在执行运算的时候把它加载到离CPU很近的地方就有意义了(比如一个循环计数-你不想每次循环都跑到主内存去取这个数据来增长它吧)。
阅读全文

 (62 votes, average: 4.37 out of 5)
(62 votes, average: 4.37 out of 5) (14 votes, average: 3.93 out of 5)
(14 votes, average: 3.93 out of 5)