从Java视角理解系统结构(三)伪共享
从Java视角理解系统结构连载, 关注我的微博(链接)了解最新动态
从我的前一篇博文中, 我们知道了CPU缓存及缓存行的概念, 同时用一个例子说明了编写单线程Java代码时应该注意的问题. 下面我们讨论更为复杂, 而且更符合现实情况的多核编程时将会碰到的问题. 这些问题更容易犯, 连j.u.c包作者Doug Lea大师的JDK代码里也存在这些问题.
MESI协议及RFO请求
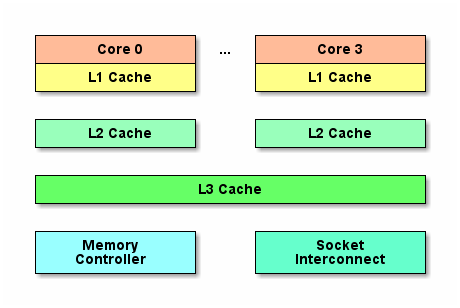
从前一篇我们知道, 典型的CPU微架构有3级缓存, 每个核都有自己私有的L1, L2缓存. 那么多线程编程时, 另外一个核的线程想要访问当前核内L1, L2 缓存行的数据, 该怎么办呢?
有人说可以通过第2个核直接访问第1个核的缓存行. 这是可行的, 但这种方法不够快. 跨核访问需要通过Memory Controller(见上一篇的示意图), 典型的情况是第2个核经常访问第1个核的这条数据, 那么每次都有跨核的消耗. 更糟的情况是, 有可能第2个核与第1个核不在一个插槽内.况且Memory Controller的总线带宽是有限的, 扛不住这么多数据传输. 所以, CPU设计者们更偏向于另一种办法: 如果第2个核需要这份数据, 由第1个核直接把数据内容发过去, 数据只需要传一次。


 (4 votes, average: 3.75 out of 5)
(4 votes, average: 3.75 out of 5)